Recientenemente me han ocurrido varios hechos, que de por sí podrían ser meros errores o bugs en el sistema, pero que todos juntos evidencia que algo falla en las herramientas de transparencia y rendición de cuentas.
La página web con las Solicitudes de acceso a la Información Pública, no funciona
Al hacer click en cualquier de los años se abre por una fracción de segundo la tabla con las solicitudes, pero se vuelve a cerrar, haciendo imposible navegar por la información. A ver, se puede trucar el css y html para poder verlo, pero supone una barera inslvable para acceder a la información para practicamente todo el mundo que visite esta página. Aquí un poco de contexto, de una investación en la que colaboré hace años, sobre la Comisión Vasca de Acceso a Información Pública, que es quien publica estas resoluciones sobre las solicitudes. Pongo el link porque es el que uso para llegar a la web que lista todas las solicitudes, que no suele ser fácil de encontrar. Por otro lado, en este listado no siempre se publican los datos que reclamaban las solicitudes de información pública que tuvieron éxito, pero esa ya es otra historia. Esta página lleva sin funcionar, al menos según la captura de Archive.org, desde el 18 junio de 2025.
Al ver que la web no funcionaba, creé una petición pública en Irekia, que canaliza las peticiones ciudadanas, para ver si podían repararla. De esto hace un mes (23 de septiembre de 2025) y sigue esperando aprobación ¿aprobación de quién? ¿qué más hace falta? Seguimos sin poder acceder a las solicitudes.
El Ayuntamiento de Bilbao consiguió evitar el juicio que iba a celebrarse hoy jueves para no tener que dar explicaciones sobre la aplicación de la normativa. El juzgado condenó simbólicamente al Ayuntamiento en costas.
Apatruyando la ciudad Por el parque con su coche Apatruya la ciudad (Foto tomada minutos después de que me pusieran la multa).
En mayo de 2023 me multaron por ir con mis hijos en bici por el parque de Doña Casilda en Bilbao. Recurrí la multa y el Ayuntamiento de Bilbao desestimó mis alegaciones. Recurrí entonces ante los juzgados de lo contencioso-administrativo para que se aclarara si era acorde a la normativa o no circular en bicicleta por el parque. Tras varios aplazamientos, se fijó el juicio para el 19 de septiembre.
En agosto de 2024, el gobierno municipal intentó mediante la anulación de la multa evitar el juicio y así no tener que dar explicaciones sobre la normativa que regula la circulación en bici. Su argumento, 16 meses después de poner la multa, era que el expediente no había sido “debidamente tramitado” y solicitaba el archivo por satisfacción extraprocesal. Esto de “satisfacción” es un eufemismo, porque seguimos sin aclaración de cuál es la correcta aplicación de la normativa, que era y es el principal objetivo.
Presentamos alegaciones, porque no habían anulado la multa conforme a los procedimientos requeridos en el derecho administrativo, ni la habían motivado ni notificado correctamente. Hoy ha llegado la notificación del juzgado que anuncia el archivo definitivo del juicio, pasando por alto las alegaciones. Se condena en costas al Ayuntamiento a pagarme 50€ en costas: “Se impone a la parte demandada las costas causadas en el presente recurso, por importe de 50 euros sin incluir el IVA”.
El importe es simbólico, porque imaginad lo que habría podido suponer pagar a un abogado, si no fuera porque apoyó esta causa gratuitamente desde el principio. Donaré esa cantidad a la Asociación Biziz Bizi, Asociación de ciclismo urbano de Bilbao, que me ha apoyado en todo este proceso. Un dinero, que, por otra parte, lo hemos pagado entre todos.
Nos toca buscar otros caminos para que la normativa se aclare. Seguiremos informando. Hablo en plural, porque en el proceso hemos aunado fuerzas la buena gente Biziz Bizi y Aitor Anchía, el abogado que ha hecho posible este proceso judicial. Una alegría encontrar nuevos amigos mientras intentamos hacer el mundo un poco mejor. Han pasado más cosas positivas en este proceso. Por ejemplo, que al principio de todo esto monté una web donde poder buscar en las ordenanzas municipales, porque la web del Ayuntamiento solamente te permite descargar cada PDF por separado. Y más tarde, siguiendo con esta idea de “abrir” lo que contienen los PDF y hacerlos buscables, hice otra web para buscar en las actas de los plenos municipales y los de distrito desde 2007.
Ahora puedo circular de nuevo en bici por Doña Casilda cuando la concurrencia de personas así lo permita, aunque no tenga la sentencia que me hubiera gustadoa enseñar a la policía si me paraba. De momento he ido a probar hoy, de camino a la inauguración-protesta del carril bici de Biziz Bizi. No me han puesto multa.
PD1: Publicaremos todos los documentos de este litigio, convenientemente anonimizados, por si pueden servir a otras personas en sus luchas contra la Administración.
PD2: El Ayuntamiento vio que iba a tener que responder en el juicio a este listado de preguntas que el juzgado había aprobado:
1. ¿Es cierto que el Ayuntamiento de Bilbao, a través de sus Ordenanzas permite que adultos circulen en bicicleta u otros medios de transporte similares en zonas peatonales cuando la concurrencia de personas así lo permita, extremándose en todo caso las medidas de seguridad por parte de la persona usuaria de tales artilugios?
2. ¿Es cierto que el Ayuntamiento de Bilbao, a través de sus Ordenanzas permite que adultos acompañen en bicicleta u otros medios de transporte similares, a menores hasta ciertas edades, ya sea 7, 10 o 12 años?
3. ¿Es cierto que la Policía Municipal de Bilbao tenía un dispositivo de vigilancia especial en la fecha de la multa en el parque de Doña Casilda? Si la respuesta es afirmativa, ¿en qué consistía ese dispositivo y qué motivo el mismo?
4. ¿Existen informes que justifiquen la actuación de ese dispositivo impidiendo a un adulto acompañar en bicicleta u otros medios de transporte similares a menores en bicicleta hasta ciertas edades, ya sean 7, 10 o 12 años?
5. ¿El Ayuntamiento ha realizado la evaluación de las Ordenanzas Espacio Público y de Espacios Verdes que indica el artículo 130 LPAC desde su aprobación hasta la actualidad? Si la respuesta es negativa, ¿por qué no se ha realizado?
6. ¿El Ayuntamiento ha publicado las evaluaciones de las Ordenanzas Espacio Público y de Espacios Verdes que indica el artículo 130 LPAC desde su aprobación hasta la actualidad? – Si la respuesta es afirmativa, ¿dónde las ha publicado? Si la respuesta es negativa, ¿por qué no las ha publicado?
7. ¿El Ayuntamiento ha realizado a través de la policía municipal cursos para aprender a hacer uso de la bicicleta? Si la respuesta es afirmativa, ¿en esos cursos se ha transitado por zonas que luego la policía municipal ha sancionado a personas desplazándose en bicicleta como el paseo de Deusto junto a la ría?
¿Os acordáis de la multa que me pusieron por ir con mis hijos en bici por Doña Casilda? Eso fue en mayo de 2023. La recurrí en julio y su desestimación me llegó en octubre. En diciembre presenté una demanda contra el Ayuntamiento de Bilbao para recurrir la multa mediante un recurso contencioso-administrativo en los juzgados. Tras varios aplazamientos, el juicio será el jueves 19 de septiembre, justo en mitad de la Semana Europea de la Movilidad. No creo que hubieran podido escoger mejor fecha. Pero, para ser rigurosos, ya no es seguro que haya juicio, porque el Ayuntamiento ha anuladola multa, al menos aparentemente, para intentar evitarlo.
En un principio me ofrecieron un procedimiento abreviado, pero elegí la vista oral,
porque el objetivo de todo esto es esclarecer para mi, para mis hijos y para todos mis compañeros, que si alguien vuelve a ir en bici por el parque no le pondrán una nueva multa. Queremos saber qué implican, en la práctica, las confusas normativas municipales sobre ir en bici por el parque de Doña Casilda. Y ya que estamos, sobre todos los parques y otras zonas peatonales donde también han puesto multas a ciclistas, como en el paseo junto a la ría entre el puente de Gehry y Elorrieta.
Sin embargo, el gobierno municipal no parece estar interesado en esclarecer nada de esto. Ha propuesto al juzgado que no se lleve a cabo el juicio porque ha anulado la multa “al apreciarse irregularidades procedimentales en su tramitación” y que “se comprueba que no fue debidamente tramitado”. Me quitan la multa, pero por problemas en el trámite, sin especificar, así que nos quedamos como estamos. La dificultad, por no decir imposibilidad, de interpretación de las normas genera una inseguridad jurídica que lleva indirectamente a establecer un margen de arbitrariedad que no permite nuestro ordenamiento jurídico.
Y todo esto ha ocurrido unos días antes de celebrarse el juicio, 16 meses después de ponerme la multa. Precisamente justo después de que el juzgado haya aceptado una serie de preguntas que el Ayuntamiento debía contestar por escrito y unos requerimientos de información que debía aportar. Hacen un requiebro (una cobra) administrativa para evitar responder a esta sencilla pregunta: ¿Es cierto que el Ayuntamiento, a través de sus ordenanzas municipales, permite la circulación en bicicleta en zonas peatonales cuando la concurrencia de personas así lo permite?
A las 52 personas multadas por este motivo en Bilbao desde el 17 de junio de 2023, según lo publicado por el Área de Seguridad en febrero de este año, seguro que también les interesa conocer la respuesta. Como a mí, también les sancionaron por infracción grave, cuando la nueva Ley de Tráfico no lo permite.
En este viaje me he encontrado con Biziz bizi, asociación de ciclismo urbano de Bilbao, como apoyo. Hemos lanzado una encuesta para conocer otros casos similares al mío. Personas multadas por ir en bici por zonas peatonales y así poder denunciar colectivamente esta situación. Ayudadnos a difundirla.
Porque, en definitiva, ¿de qué va verdaderamente el discurso de apoyo a la movilidad urbana sostenible si multan a un padre por ir con sus hijos en bici por un parque para luego quitarle la multa 16 meses después solamente porque ha sido capaz de recurrirla en un juicio?
¿Por dónde íbamos? Ah, sí, me habían puesto una multa por ir en bici con mis hijos, menores de edad, por un parque de Doña Casilda semivacío y estaba a punto de presentar mis alegaciones.
El Órgano sancionador competente por razón de la materia, en función de los datos, antecedentes y circunstancias existentos en el expediente administrativo debidamente comprobados, en ejercicio de las atribuciones que le corresponden, ha dictado la siguiente: RESOLUCIÓN
1º.- DESESTIMAR las alegaciones presentadas en el expediente sancionador de referencia por la persona interesada, en razón de las siguientes consideraciones:
El artículo 121.5 del Reglamento General de Circulación establece que la circulación de toda clase de vehículos en ningún caso deberá efectuarse por las aceras y demás zonas peatonales.
El párrafo quinto del artículo 21 de la Ordenanza de Espacio Público de Bilbao señala que los y las menores de 12 años, bajo la exclusiva responsabilidad de las personas que ostenten su patria potestad, podrán utilizar las zonas peatonales, plazas y parques de Bilbao, para circular en bicicleta, monopatín, patines y similares cuando el número de personas concurrentes en dichos espacios lo permita. En el caso que nos ocupa, la circulación con la bicicleta se realizó por una persona mayor de 12 años, no concurriendo por tanto, la excepción preceptuada en el referido artículo.
La referencia que el artículo 21 realiza a la utilización de bicicletas y otros elementos de desplazamiento fuera de las zonas habilitadas al efecto, cuando la concurrencia de personas así lo permita, refiere únicamente a zonas peatonales en sentido estricto, no entendiendo por éstas las plazas y parques de Bilbao.
2.- Enviadas las alegaciones al agente denunciante de conformidad con lo establecido en el art. 95.2 del RDL 6/2015 de 30 de octubre, las ha desestimado ratificándose en los términos de la denuncia.
2º.- ESTIMAR por el organo instructor no necesaria la apertura de período de prueba y audiencia en los términos previstos por el artículo 13 del R.D. 320/1994, por el que se regula el Reglamento del procedimiento sancionador en materia de Tráfico, Circulación de vehículos a motor y Seguridad Vial, para la averiguación y calificación de los hechos o para la determinación de las posibles responsabilidades, por haber resultado debidamente constatados los hechos denunciados en la fase instructora del expediente sancionador.
A los efectos procedentes, el órgano instructor pone a disposición de la persona interesada para su examen el expediente sancionador en las dependencias del Área.
Ahora voy a impugnar esta desestimación mediante Recurso contencioso-administrativo ante el Juzgado de lo contencioso-administrativo del Tribunal Superior de Justicia del País Vasco.
0. ¿De verdad no hay una forma sencilla de buscar en las actas de los plenos municipales?
Te ha pasado. Bueno, hagamos como si te hubiera pasado.
Quieres saber cuándo, en el pleno de tu ayuntamiento, han hablado de tal o cuál tema. Vas a la web del ayuntamiento y tras un rato navegando encuentras la página ¡bingo!
Una URL maravillosamente larga: https://www.bilbao.eus/cs/Satellite?c=Page&cid=3000015482&language=es&pageid=3000015482&pagename=Bilbaonet%2FPage%2FBIO_ListadoSesionesPlenarias. Puedes acceder a las actas en PDF. Todo bien.
Basta ahora con descargarlas una a una, abrir cada documento y buscar. Puede resultarte algo tedioso. Lo haces para el 2023, pero cuando llegas a 2022 ya te cansas ¿no existe una manera mejor para poder buscar en todas las actas? Y si las tuvieras descargadas ¿cómo buscar en todas ellas?
En la web del ayuntamiento hay disponibles actas de los plenos desde noviembre de 2007, pero descargarlas todas te llevaría más tiempo del que dispones. Son 193 a día de hoy (y eso sin contar con los extractos de las actas, que están disponibles desde 2002).
Las actas están ahí. Están publicadas. Cualquiera puede acceder a elllas. Otra cosa es que alguien tenga el tiempo para descargarlas y analizarlas.
¡Este es un caso para Abrir Datos Abiertos!
No es la primera vez que me pasa. Tener la información al alcance y no poder procesarla, porque no está publicada de una forma que pueda ser fácilmente consumida. Requiere demasiado trabajo.
Así que me puse manos a la obra.
Lo primero es 1) obtener la lista completa de actas; luego 2) descargar todos los PDF; y por último3) procesar todos los textos para poder hacer búsquedas.
1. Scraping
Para lo primero hace falta “escrapear” (de scraping, en inglés), esto es, descargar sistemáticamente la información de la web. Para ello le pregunté a Ekaitz si se le ocurría algo, porque el escrapeado no era imposible, pero tampoco trivial. En unas horas me mandó este código de python, que sirve para genera un archivo JSON que contiene la lista y URL de todos los documentos para poder descargarlos:
# Copyright 2023 Ekaitz Zárraga <ekaitz@elenq.tech>
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import requests
from bs4 import BeautifulSoup
from urllib.parse import urlparse, urljoin
import json
if __name__ == "__main__":
base_url = urlparse("https://www.bilbao.eus/cs/Satellite?c=Page&cid=3000015482&language=es&pageid=3000015482&pagename=Bilbaonet%2FPage%2FBIO_ListadoSesionesPlenarias")
r = requests.get(base_url.geturl())
soup = BeautifulSoup(r.text, "html.parser")
years = { i.text: i["value"] for i in soup.select("select#anioId option[value]") if i.text.isdigit()}
data = []
for year, id in years.items():
r = requests.post(base_url.geturl(), {"anioId": id})
soup = BeautifulSoup(r.text, "html.parser")
table = soup.find('table', class_='tablalistados')
headers = [ th.text.strip() for th in table.find("tr").find_all("th") ]
data_rows = table.find_all("tr")[1:]
print(year)
for data_row in data_rows:
line = { k: v for k, v in zip(headers, data_row.find_all("td"))}
line["Fecha"] = line["Fecha"].get_text().strip()
line["Número"] = line["Número"].get_text().strip()
line["Sesión"] = line["Sesión"].get_text().strip()
# Los que tienen archivo: guardar enlace (luego se puede hacer un GET)
for field in ["Orden del día", "Actas", "Resumen sesión", "Extractos", "Vídeos"]:
link = line[field].find("a")
url = urlparse(urljoin(base_url.geturl(), link["href"])) if link else None
line[field] = url.geturl() if url else None
data.append(line)
with open("plenos.json", "w") as f:
f.write(json.dumps(data))¡
2) Descargar los PDF
Para eso me fui a R, que es donde me encuentro más cómodo para trastear. Este archivo de R lee el JSON descargado, descarga todos los PDF y genera un archivo CSV en el que en cada línea guarda: el texto contenido en una página de cada PDF, el número de página, la URL al PDF original del acta y la fecha del pleno municipal.
# Cargar librerías
library(tidyverse)
library(pdftools)
library(tm)
library(rjson)
# Genera archivo .json con el código de plenos.py
# Archivo descargado plenos_230823.json
# Segundo archivo, en vista de que han cambiado las URL
data <- fromJSON(file= paste0("data/original/plenos_230823.json") )
# Apana (flat) el archivo json para operar más fácilmente --------
for( i in 1:length(data) ) {
print(i)
# for( i in 1:2 ) {
fecha <- data[[i]]$Fecha
num <- data[[i]]$Número
sesion <- data[[i]]$Sesión
orden <- data[[i]]$"Orden del día"
extractos <- data[[i]]$Extractos
actas <- data[[i]]$Actas
resumen <- data[[i]]$"Resumen sesión"
video <- data[[i]]$Videos
if( is.null(orden) ) { orden = NA }
if( is.null(extractos) ) { extractos = NA }
if( is.null(actas) ) { actas = NA }
if( is.null(resumen) ) { resumen = NA }
if( is.null(video) ) { video = NA }
if ( i == 1 ) {
plenos <- data.frame(fecha = fecha, num = num, sesion = sesion, orden =orden, extractos = extractos, actas = actas, resumen = resumen, video =video)
} else{
plenos <- rbind( plenos,
data.frame(fecha = fecha, num = num, sesion = sesion, orden =orden, extractos = extractos, actas = actas, resumen = resumen, video =video)
)
}
}
# Format date (pon en formato fecha)
plenos <- plenos %>% mutate(
fecha = as.Date(fecha, format="%d/%m/%Y")
)
# Descarga los PDF - Download ----
for( i in 1:nrow(plenos) ) {
# for( i in 1:22 ) {
print(plenos$actas[i])
if ( !is.na(plenos$actas[i]) ) {
print(plenos$fecha[i])
#Descarga el archivo
download.file(plenos$actas[i],
paste0("data/output/actas_230823/",plenos$fecha[i],"_acta_pleno-municipal-bilbao.pdf"))
}
}
# Read pdf -------
# Guarda el resultado de cada página en una celda, junto con fecha y número de página
for( i in 1:nrow(plenos) ) {
print( paste(i,"fila"))
print(plenos$fecha[i])
if ( !is.na(plenos$actas[i]) ) { # Que exista el acta
text <- pdf_text(paste0("data/output/actas/",plenos$fecha[i],"_acta_pleno-municipal-bilbao.pdf"))
if ( i == 5 ) { # TODO: Para el primer pleno que tiene acta (metido a mano, mejorar!) en este caso el 5
for( j in 1:length(text)) { # itera por todas las páginas de cada pdf
print( paste("row:", j, " ----------------------------------"))
if( j == 1) { # Para la primera iteración
print("j es 1")
all_pages <- text[j] %>% as.data.frame() %>% rename( txt = 1) %>% mutate(
pag = j,
fecha = plenos$fecha[i],
actas = plenos$actas[i]
)
} else (
page = as.data.frame(text[j]) %>% rename( txt = 1) %>% mutate(
pag = j,
fecha = plenos$fecha[i],
actas = plenos$actas[i]
)
)
if( j != 1) {
all_pages = rbind(all_pages, page)
}
}
} else {
for( j in 1:length(text)) { # itera por todas las páginas de cada pdf
if( j == 1) {
print("4")
all_pages_temp <- text[j] %>% as.data.frame() %>% rename( txt = 1) %>% mutate(
pag = j,
fecha = plenos$fecha[i],
actas = plenos$actas[i]
)
} else (
page = as.data.frame(text[j]) %>% rename( txt = 1) %>% mutate(
pag = j,
fecha = plenos$fecha[i],
actas = plenos$actas[i]
)
)
if( j != 1) {
all_pages_temp = rbind(all_pages_temp, page)
}
}
all_pages = rbind(all_pages, all_pages_temp)
}
} else {
print("No existe acta")
}
}
# salvar archivo como CSV
write.csv(all_pages, "data/output/paginas-actas-plenos_230823.csv")
3. Página para buscar
A partir del CSV generado en el paso anterior monte un buscador básico (sólo se puede buscar por una palabra) desarrollado en PHP (ver código):
¿Qué le sobra, qué le pasa, qué le falta a esta web? ¿os resulta útil? ¿cómo podíais vivir sin ella? ¿encontrais algo interesante? Encantados de escucharos.
Me acaban de poner multa por ir con mis hijos en bici por el parque Doña Casilda (Bilbao) el agujero negro para las bicicletas. Parque semi vacío, dos agentes a la espera del ciclistas ¿alguien sabe si hay posibilidades al recurrir la multa?
Me ha pedido la documentación y empezado a escribir la multa sin decir nada más, sin siquiera explicar qué es lo que estaba haciendo mal. Esa es la imagen que mis hijos se llevan de la policía municipal
Tras pregutarle, el agente municipal citaba la ordenanza de bicis (no existe como tal) y no era capaz de indicar qué normativa en concreto había incumplido más alla de “la ordenanza de Bilbao” y el código de circulación. Aquí las ordenanzas municipales de Bilbao. Fuente del mapa.
Apatruyando la ciudad Por el parque con su coche Apatruya la ciudad. (Así estaban los policías minutos después de multarme)
Facilitar el acceso y búsqueda a las ordenanzas municipales
A raíz de la multa por ir en bici por un parque (y ante la imposibilidad de buscar en la web del Ayto. de Bilbao qué normativa trata sobre bicicletas y/o zonas peatonales) he montado esta web para buscar en las ordenanzas. Es un ejercicio rápido de transparencia para abrir datos (que deberían) ser abiertos.
Tuve que pasar las ordenanzas de PDF a html. En un caso tuve que hacer OCR (reconocimiento de caracteres en imágenes) porque la ordenanza estaba publicada como imágenes escaneadas. En otro casono pude usarla porque el link al PDF de la ordenanza daba error.
Como prueba de concepto de lo que debería ser una web municipal creo que vale.
Dejo anotado aquí el cómo se hizo, casi todo desde línea de comandos:
Un script en R para descargar todos los PDF.
Con el comando pdftohtml convierto los PDF en html. Algunos los tengo que limpiar ya que tienen demasiadas imágenes repetidas. Además, en la página no usaré imágenes. Lo hago con “sed -e ‘s/]*>//g’ input.html > output.html”
En el caso de la ordenanza del Casco Viejo no se puede copiar el texto, son imágenes: 3.1 Convertir PDF a imágenes con pdftoppm 3.2 OCR con tesseract con loop “for i in casco-??.png; do tesseract “$i” “text-$i” -l eng; done;” 3.3 Unir los textos “cat text-casco-*.png.txt > fin.txt” 3.4 Sustituyo los múltiples espacios juntos que genera tesseract “ ” por ” “.
Abro el html generado de cada ordenanza en navegador y copio el contenido y lo pego en una página de wordpress (una página por ordenanza). Cambio de fecha de la página a fecha de aprobación.
Retoques en wordpress mínimos y resaltar buscador.
Borrador de alegaciones
Publiqué en Twitter todo esto y con las sugerencias recibidas (y la ayuda de Bizi Bizi Bilbao) publiqué este borrador y recopilación de información para escribir las alegaciones. Pronto publicaré las alegaciones finales y actualizaré este post. El documento compartido también incluye una recopilación de toda la normativa aplicable en mi caso.
Esto no lo hago por mi solamente, para no pagar la multa, sino para que se reconozca que las bicis sí podemos circular por espacios peatonales.
Well, I know you are not going to read the entire PhD thesis and annexes, so I am publishing it little by little, chapter by chapter. I am transforming the content to html, so I can use all the hyperlinks features and make it easier to navigate. It will take months, but I’ll complete the job.
I’ve created a page that is a summary of all the extra content of the dissertation: Color of corruption. Visual evidence of agenda-setting in a complex mass media ecosystem submitted on December 2022 and defended successfully on June 2023.
I’ve already uploaded all the code for the data gathering and analysis as well as the data bases that I’ve used.
I haven’t posted as much as I wanted to tell what I was doing, but I hope this page will help introduce what I’ve been doing. It’s been a long very long journey.
A visual analysis of all the pages of the PhD dissertation.
PS: In the past I’ve also published my research online, see these two examples. The goal was to publish the process, not only the final results, and make them available for everyone else:
TLDR: cómo procesar uan pregunta de todos los barómetros del CIS que no está en los archivos fusionados. Necesito para mi tesis procesar todos los microdatos. Preguntas y próximos pasos al final.
Una de las fuentes de datos que uso para mi tesis son los barómteros del CIS. Cada mes desde hace muchos años el CIS hace una encuesta, barómetro, en donde se pregunta por los tres principales problemas que tiene España.
18/ …y analizando cómo la sociedad percibe la corrupción, por ejemplo, usando los barómetros del CIS y su percepción de ésta como problema. imagen de barómetro y corrupción. Analicé esto para el libro @espanaconC, un manual para entender de dónd viene la corrupción en España pic.twitter.com/13ZLGebAmk
Como los microdatos de cada barómetro están disponibles, esto es, cada una de las respuestas a los cuestionarios está publicada, es posible analizar y cruzar variables por edad, comunidad autónoma o profesión. El primer problema es conseguir y procesar los datos.
Disponibilidad de los datos: web y FID
Lo primero es dirigirse a la página del CIS a descargarlos (pestaña Estudios http://www.analisis.cis.es/cisdb.jsp), pero se encuentra uno el primer problema: hace falta introudcir tus datos personales (nombre, apellidos, universidad, email, objeto) para descargarlo, lo cual descarta un scrapero rápido automatizado de los datos. Existen datos fusionados de varios barómetros juntos para algunos años, pero no están disponibles para todos los años.
Así que la siguiente opción es usar los Fichero Integrado de Datos (FID) (http://analisis.cis.es/fid/fid.jsp) “un único fichero, de los microdatos de un conjunto de variables, para los estudios del CIS que se seleccionen”:
“El interfaz permite al usuario elegir de forma rápida y cómoda a partir de una colección, los estudios que desee y, de estos, las variables deseadas de entre las contenidas en el diccionario del FID. Posteriormente, la solicitud se envía al CIS y, una vez que el CIS procede a su autorización, el fichero con los microdatos seleccionados se puede descargar en formato ASCII o SAV, de modo sencillo y fácil de tabular por diversos programas estadísticos. Es necesario el registro del usuario o identificación del mismo (si el usuario ya está registrado), para completar una petición de datos”.
Web del CIS. Explicación sobre los Fichero Integrado de Datos (FID).
El problema es que la pregunta que necesito “¿Cuál es el principal problema que existe en España? ¿ y el segundo? ¿y el tercero?”, aunque su enunciado concreto ha ido variando a lo largo de los años, no está disponible en los FID, ya que solamente se ofrece un subconjunto de las variables integradas.
Según me han indicado soy el primero en hacerlo. Me parece raro que nadie lo haya hecho antes, ciertamente. Seguramente hayan usado otros métodos.
Tras una serie de pruebas con unos archivos de prueba para comprobar que los abría bien han procedido a preparar para que descargue todos los microdatos de los barómetros en zips por año. En pocos días me he hecho con la colección completa de microdatos de barómetros.
.zips esperando paciente a ser abiertos.
Un poco de código para descomprimirlos fácilmente:
unzip ‘*.zip’ unzipear todos los archivos mv */* . mover los que están en directorios al raiz mv MD*/* . rm -r 19* 20* fu* eliminar directorios vacíos Ahora que tengo todos, volver a unzipear: unzip ‘*.zip’
Ahora creo un archivo con todos los *.sav: ls | grep sav > files.csv
Ahora tengo el listado de todos los barómetros disponibles (los de 2020 y 2021 me da un problema para abrirlos que tengo que resolver “error reading system-file header”). Puedo procesar todos los microdatos de los barómetros desde junio de 1989, los anteriores solamente están disponibles uno de 1987 (nº 1695), dos de 1985 (nº 1442 y 1435) y otro de 1982 (nº 1320), que me enviarán cuando sea posible. Para el resto desde junio de 1979 no hay microdatos y habría que pagar por ellos si los quisiera.
Encontrar la pregunta y su número
Documentos que se incluyen en un .zip de un barómetro.
Para poder analizar las respuestas por CCAA, que es mi objetivo, tengo que encontrar el código de la pregunta, que, oh sorpresa, va cambiando a lo largo de los años. Para ello he montado una hoja de cálculo para anotar qué código lleva la pregunta (https://docs.google.com/spreadsheets/d/1xxlt8FnWanVzYkIQdU2yaWlE8-HUvnzVXSiE2QvNJRU/edit#gid=0). Así, la primera vez que aparece es en los archivos disponibles es de mayo de 1992, y tiene los códigos P501, P502 y P503, una por cada uno de los problemas percibidos. Ese código ha ido variando a lo largo de los años a la pregunta: P1401, P701, P1601, P1201… los primero números indican el número de la pregunta. Para averiguar el código hay dos maneras. Cada barómetro está compuesto por un conjunto de archivos. Así, el barómetro nº 3134 tiene los siguientes archivos:
3134.sav microdatos
DA3134 archivo dat
ES3134
FT3134.pdf ficha técnica
cues31314.pdf cuestionario original
codigo3134.pdf códigos utilizados
tarjetas3134.pdf tarjetas que usan los encuestadores
Al principio miraba si la pregunta estaba en el cuestionario, pero luego vi que era más rápido mirar directamente si en el archivo con los códigos venía la pregunta y su número: “P.7 Principal problema que existe actualmente en España. El segundo. El tercero” que con suerte correspondería con la variable P701, P702 y P703.
El problema es que en algunos casos contados ponen la “p” de la variable con minúscula y el código es p701. Algo que solamente se puede averiguar abriendo el archivo .sav. Para ver lo que contiene el archivo.sav con la librería “foreign” en R: df <- read.spss(data, use.value.label=TRUE, to.data.frame=TRUE), siendo data el “path” al archivo .sav correspondiente.
Desde Rstudio se puede previsualizar el archivo .sav cargado y mirar cuál es el código correcto:
Así se ve en Rstudio.
Lo que pasa es que muchos barómetros no tienen disponible esa pregunta, pero ¿cómo saberlo para ahorrarnos tiempo? Existe una página, ya ni recuerdo cómo llegué a ella, que tiene todas las respuestas recogidas y procesadas “Tres problemas principales que existen actualmente en España (Multirrespuesta %) http://www.cis.es/cis/export/sites/default/-Archivos/Indicadores/documentos_html/TresProblemas.htm, esto pernite de un vistazo saber cuáles son los barómetros que tienen respuesta:
Así se puede ir a tiro hecho a buscar el código en los barómetros que sabemos tienen respuesta. Relleno celdas de la hoja de cálculo de las columnas p1, p2 y p3 (cada una corresponde con una de las respuestas a los 3 principales problemas) copiando el valor anterior, hasta que da error el script que lo procesa (ver más adelante).
Clasificando en p1, p2 y p3 los códigos de las preguintas en cada uno de los barómtreos. En negro si lo he mirado, en gris si lo he “acertado” y no ha fallado el script.
Pero no se detienen los problemas. Los encuestadores recogían la respuesta libre (que no se ofrece en los microdatos) para después clasificarla en unos cajones-respuestas establecidos:
Lo que ocurre es que en algunos años “La corrupción y el fraude” no se ofrecían como respuesta posible, así que de haber habido alguna respuesta corrupción como respuesta en aquello años de bonanza económica habrá ido a la casilla de “otros”. Esto pasó entre septiembre de 2000 y julio de 2001, por ejemplo, lo que hará que la serie tenga algunos agujeros. Habrá que hacerlos explícitos.
Procesar 1: juntar todas las respuestas
Una vez sorteadas estas trabas es la hora de programar un script que vaya abriendo cada archivo .sav, seleccione las variables adecuadas y cree un archivo con todas las respuestas:
# Select and load multiple barometro files ------------
# where are files stored
path <- "~/data/CIS/barometro/almacen/tmp/"
# remove if it hasn't got the questions
cis_files <- cis_files %>% filter( p1 != "" )
# iterate through all the files
for ( i in 1:nrow(cis_files) ) {
# for ( i in 1:8 ) {
print("--------------------")
print(paste(i,cis_files$name[i],cis_files$date[i] ) )
# create path to file
data <- paste0(path, cis_files$name[i])
# load data in the file
df <- read.spss(data, use.value.label=TRUE, to.data.frame=TRUE)
# chec if variable ESTU exists
if ( "ESTU" %in% colnames(df) ) {
df <- df %>% mutate(
ESTU = as.character(ESTU)
)
} else {
# if ESTU is not in the variables, insert the ID of the barometer
df <- df %>% mutate(
ESTU = cis_files$id[i],
ESTU = as.character(ESTU)
)
}
# if REGION exixts, rename it as CCAA
if ( "REGION" %in% colnames(df) ) {
df <- df %>% rename(
CCAA = REGION
)
}
# add date to data by taking it gtom cis_id dataframe
df <- left_join(df,
cis_id %>% select(id,date),
by = c("ESTU"="id")
# ) %>% select( date, ESTU, CCAA, PROV, MUN, P701, P702, P703 )
)
# select the basic columns and the 3 questions
# the true name of the question is specified in the online document https://docs.google.com/spreadsheets/d/1xxlt8FnWanVzYkIQdU2yaWlE8-HUvnzVXSiE2QvNJRU/edit#gid=0
selected <- c( "date", "ESTU", "CCAA", "PROV", "MUN", cis_files$p1[i], cis_files$p2[i], cis_files$p3[i])
df <- df %>% select(selected) %>% rename(
p1 = cis_files$p1[i],
p2 = cis_files$p2[i],
p3 = cis_files$p3[i],
) %>% mutate(
p1 = as.character(p1),
p2 = as.character(p2),
p3 = as.character(p3)
)
# For the first file
if ( i == 1) {
print("opt 1")
# loads df in the final exportdataframe "barometros"
barometros <- df
print(df$date[1])
print(df$ESTU[1])
} else {
print("not i==1")
barometros <- rbind( df, barometros)
}
}
Por el momento tengo 570.795 respuestas a la pregunta analizada de 223 barómetros, a falta de solventar algunos problemas.
Ahora toca agrupar las respuestas por barómetros de nuevo y calcular el número de encuestas por barómetro que hacen mención a tal o cual tema:
# Group by date and CCAA ----------------------
evol_count <- barometros %>% group_by(CCAA,date) %>% summarise(
# counts number of elements by barometro and CCAA
count_total = n()
) %>% ungroup()
evol_p1 <- barometros %>% group_by(CCAA,date,p1) %>% summarise(
# counts number of answers for each type for question 1 by barometro and CCAA
count_p1 = as.numeric( n() )
)
evol_p2 <- barometros %>% group_by(CCAA,date,p2) %>% summarise(
# counts number of answers for each type for question 1 by barometro and CCAA
count_p2 = as.numeric( n() )
)
evol_p3 <- barometros %>% group_by(CCAA,date,p3) %>% summarise(
# counts number of answers for each type for question 1 by barometro and CCAA
count_p3 = as.numeric( n() )
)
# joins p1 and p2
evol <- full_join(
evol_p1 %>% mutate(dunique = paste0(date,CCAA,p1)) ,
evol_p2 %>% mutate(dunique = paste0(date,CCAA,p2)) %>% ungroup() %>% rename( date_p2 = date, CCAA_p2 = CCAA),
by = "dunique"
) %>% mutate (
# perc_p2 = round( count_p2 / count_total * 100, digits = 1)
)
# fills the dates and CCAA that were empty
evol <- evol %>% mutate(
date = as.character(date),
date = ifelse( is.na(date) , as.character(date_p2), date),
date = as.Date(date),
CCAA = as.character(CCAA),
CCAA = ifelse( is.na(CCAA), as.character(CCAA_p2), CCAA),
CCAA = as.factor(CCAA)
)
# joins p1-p2 with p3
evol <- full_join(
evol,
evol_p3 %>% mutate(dunique = paste0(date,CCAA,p3)) %>% ungroup() %>% rename( date_p3 = date, CCAA_p3 = CCAA),
by = "dunique"
) %>% mutate (
# perc_p2 = round( count_p2 / count_total * 100, digits = 1)
)
# fills the dates and CCAA that were empty
evol <- evol %>% mutate(
date = as.character(date),
date = ifelse( is.na(date) , as.character(date_p3), date),
date = as.Date(date),
CCAA = as.character(CCAA),
CCAA = ifelse( is.na(CCAA), as.character(CCAA_p3), CCAA),
CCAA = as.factor(CCAA)
)
# add number of answers per barometer and CCAA
evol <- left_join(
evol %>% mutate(dunique = paste0(date,CCAA)),
evol_count %>% mutate(dunique = paste0(date,CCAA)) %>% select(-date,-CCAA),
by = "dunique"
) %>% mutate (
count_p = count_p1 + replace_na(count_p2,0) + replace_na(count_p3,0),
# este sistema da error en los "no contesta" al contarlos varias veces al sumar!!!
perc = round( count_p / count_total * 100, digits = 1)
) %>% select ( date, CCAA, everything(), -dunique, -date_p2, -date_p3, -CCAA_p2, -CCAA_p3 ) %>% mutate(
p = p1,
p = ifelse( is.na(p),p2,p),
p = ifelse( is.na(p),p3,p),
date = as.Date(date)
)
Limpiar los datos 2: las respuestas
Toca limpiar las respuestas para eliminar las múltiples formas de escribir “La corrupción y el fraude” o “Corrupción y fraude ” (ojo al espacio después de “fraude” que a algunos vuelve loco). Una tarea de estandarización de las respuestas que hago con OpenRefine y que en algunos casos requiere de decisiones subjetivas, véase el ejemplo:
Detección de respuestas parecidas para su consolidación en OpenRefine.Proceso de consolidación de respuestas con OpenRefine.
Visualizar
El siguiente paso es visualizar los resultados para detectar los primero errores y corregir problemas en la captura y procesado. Antes de publicar esto ha ocurrido varias veces: detecté unos barómetros de 2016 que no se habían descomprimido, por ejemplo.
En las primeras visualizaciones trato de ver que salen valores congruentes y que no hay agujeros en los datos. En este primer gráfico de rejilla muestro el porcentaje de entrevistas de cada barómetro que tienen como respuesta “El paro” (rosa) y “La corrupción y el fraude” (verde). Ya se pueden ver cómo hay mucho más ruido en lugares como Ceuta y Melilla por el bajo número de respuestas, pero que el resto de valores sigue una tendencia parecida. En La Rioja (fila de abajo, tercera por la izquierda) también se ve ese problema, con sus 17 entrevistas por barómetro.
Un primer vistazo a las visualizaciones, publicaré más cuando tenga más claro que no hay errores en los datos
Problemas y siguientes pasos
Desde el CIS no solamente me enviaron todos los microdatos sino que me asesoraron sobre su uso. Les conté lo que pretendía hacer con los datos y me advirtieron de dos cosas relacionadas con la cantidad de entrevistas por CCAA y la ponderación:
A. Ponderación en SPSS
“Los ficheros Sav, por defecto van con la ponderación activada, siempre, en todos los que hemos pasado ya y en los que pasaremos, de esta lista”, algo que no entiendo del todo bien, porque eso no creo que deba afectar a los microdatos. Si alguien ha trabajado con los .sav en SPSS quizás me pueda aclarar cómo funciona la ponderación en ese programa, dónde se almacena esa información.
B. Si no tienes más de 400 entrevistas…
“Nosotros no consideramos representativos los datos de Comunidades con un tamaño menor a 400 entrevistas. En los barómetros, salvo los del último año para algunas Comunidades (mire ficha técnica), el tamaño muestral es de entorno a las 2.500 entrevistas, eso significa que habitualmente salvo Madrid y Cataluña, la mayor parte se quedan muy por debajo, incluso de menos de 100. Los márgenes de error cuando se quiere hablar sobre esos datos son muy altos, y más aún si además va a hacer cruces”. Me redirigían a una sección de su web:
ADVERTENCIA: El error muestral aumenta conforme disminuye el número de entrevistas realizadas. Téngase presente sobre todo en los cruces de variables y las preguntas filtradas. A modo orientativo, bajo la hipótesis de muestreo aleatorio simple, P=Q=1/2 y un 95% de intervalo de confianza, véase la siguiente tabla: Fuente: http://www.analisis.cis.es/aAvisoVars.jsp?tipo=2&w=800&h=600
Una cuestión no menor que puede hacer que no use finalmente estos datos para las comunidades, o tenga que emplear grados de incertidumbre demasiado altos.
En los últimos estudios sí aparece la ponderación usada para el valor global:
Día en que se realiza la entrevista ¿se podría saber?
Tenía interés en cruzar el día de la encuesta para ver si se podía estudiar con determinados escándalos que tienen un día muy marcado su anuncio en los medios de comunicación, podŕia verse su impacto en las encuestas, pero ese dato no está disponible. Lo que se conoce es el periodo en que se realizan las encuestas, que suele ser la primera quincena del mes. ¿se podrá conseguir la fecha exacta de cada entrevista?
En el mes de Marzo de 2018 eldiario.es sacó a la luz irregularidades en el caso del máster de la entonces presidenta de la Comunidad de Madrid Cristina Cifuentes. Para tener más contexto puedes escuchar el magnífico podcast sobre el escándalo que publicó eldiario.es.
En esta serie de posts analizaremos cuantitativa y cualitativamente la cobertura que se le dio al escándalo en diferentes medios de comunicación y redes sociales para intentar entender cómo es el flujo de información entre unos canales y otros. Estos textos forman parte de la investigación para mi tesis doctoral sobre cobertura de corrupción en España. En su momento ya analicé la cobertura en las portadas de los periódicos en papel.
Porcentaje de noticias en portada Cifuentes (sobre el total) en periódicos digitales.
Hoy analizo las noticias sobre lo que se ha venido a conocer como el caso “Máster” en una nueva base de datos: los Telediarios de Televisión Española que Civio pone fácil estudiar con su herramienta Verba (https://verba.civio.es/).
Verba permite hacer búsquedas por palabras en las transcripciones de los telediarios de TVE y descargar los datos. La unidad de medida es la frases que contiene tal o cual palabra.
No centraremos ahora en cuando estalló el escándalo, el 21 de marzo de 2018. El resultado es fruto buscar en Verba tras la búsqueda multipalabra para ese periodo concreto: “Cifuentes”|”Javier Ramos”|”Enrique Álvarez Conde”|”Pablo Chico”|”María Teresa Feito”|”Alicia López de los Cobos”|”Cecilia Rosado”|”Clara Souto|Amalia Calonge”|”Universidad Rey Juan Carlos”.
Los gráficos están hechos con VerbaR, unos scripts de R que he desarrollado para analizar con R datos de Verba. Cada línea negra es una frase que incluye una de las palabras de la búsqueda:
El gráfico está dividido en una parte de arriba, para los telediarios de las 15:00h y la de la abajo, para los de las 21:00h. He marcado los primeros dos minutos para enfatizar la cabecera o “portada” del noticiario. No tengo claro todavía cuánto dura este inicio con las noticias más destacadas.
Aquel 21 de marzo, tras salir publicado el escándalo en eldiario.es el Telediario de las 15:00h se hizo eco de la noticia en su apertura:
1’18”: La Universidad Rey Juan Carlos atribuye a un error de transcripción que en dos asignaturas del máster que Cristina Cifuentes cursó hace seis años figurase como no presentada.
1’28”: Cifuentes aprobó ambas asignaturas, según ha confirmado el rector.
Más adelante expandía la noticia ne el minuto 14:
14’56”: En Madrid, la universidad Rey Juan Carlos niega cualquier irregularidad en el máster de la presidenta Cristina Cifuentes.
15’03”: Un diario digital sostiene que obtuvo la titulación con dos notas falsificadas.
Verba ofrece la posibilida de acceder a la transcripción completa y no solamente a las frases resultado de la búsqueda-
En el gráfico se puede ver cómo en ese primer día hay dos bloques de información: el del resumen inicial, esos 2 ó 3 minutos -estaría bien poder cuantificarlo- y cuando se amplia la noticia. Esa cabecera viene a ser análoga a la portada de los periódicos, donde se seleccionan las noticias más importantes.
El problema de la búsqueda por palabras es que se deja fuera las frases que no contienen las palabras buscadas pero que pertenecen a la noticia, por ello esos existen huecos en los gráficos entre unas líneas y otras. Por ejemplo, la noticia en cabecera duraba más, pero se quedó fuera de nuestra búsqueda:
1’31”: La oposición pide explicaciones.
1’34”: El Gobierno regional subraya la honorabilidad del comportamiento de la presidenta.
En el gráfico se ha sobredimensionado la duración de las frases asignándoles 30 segundos de duración para facilitar su lectura.
Si pudiéramos distinguir los bloques de noticias, cuando empieza un tema y acaba otro, podríamos ver algo como esto, donde coloreo “a mano” en rojo la posible duración del total de las noticias relacionadas con el máster:
Este otro gráfico visualiza el número de frases que contienen las palabras clave. Suma todas las frases encontradas y las agrega en una columna:
Nos da una idea aproximada de la evolución de la cobertura. Sería interesante poder clasificar esta información según los días que la noticia ha estado en la cabecera del telediario y poder así estudiar la relación de tiempo de frases dedicadas a la noticia con su aparición en el resumen de inicio. También sería interesante conocer la duración de la noticia, y no únicamente el número de frases encontradas.
Si volvemos a hacer el primer gráfico clasificando manualmente las frases seleccionadas, podemos entender mejor la historia: primero salta la noticia sobre el master (“máster” en verde) , vuelve a aparecer a primeros de abril con fuerza, con 10 días seguidos con noticia en cabecera en el telediario de las 15:00h y se cierra con la dimisión el 26 de abril, tras el nuevo escándalo del vídeo sobre el robo de las cremas en un supermercado:
Podemos ver estos mismo datos agregados en columnas:
Este primer análisis nos permite ver la potencia y las limitaciones de este tipo de visualizaciones:
las palabras clave de búsqueda son determinantes
es necesario reclasificar la información para poder analizar en profundidad la evolución de la cobertura. Otras variables a analizar serían el enfoque de las noticias.
¿Cómo de relevante fue la cobertura de TVE en relación a otros medios de comunicación o redes sociales como Twitter? Lo veremos en los siguientes capítulos.
He creado una aplicación con Shiny para poder generar gráficos de este tipo y analizar más rápidamente las diferentes búsquedas en Verba: [actualizción: mejor esta versión: https://r.montera34.com/users/numeroteca/verbar/app/] https://numeroteca.shinyapps.io/verbar/
Gracias a que es interactiva puedes ver que contiene cada frase.
Hay una opción que te permite seleccionar una fecha y ver todas las frases de ese día.
Basta pasearse por las páginas dedicadas a la COVID-19 en Euskadi en los principales diarios que ofrecen información local (eldiario.es, elcorreo.com, por ejemplo) para ver que esos gráficos de evolución de fallecidos por provincia no se publican. Y no se publican porque la Administración publica esos datos de una forma que hace imposible, digamos mejor muy dificultosa, su elaboración. Es un claro ejemplo de cómo la forma de publicar los datos dicta la agenda mediática. Publica los datos de una forma y los medios de comunicación hablarán de una determinada forma ¡Si quieres evitar que se hable de algo, no publiques esos datos!
Fallecidos diarios en las webs de El Correo y El Diario
Open Data Euskadi, la plataforma de datos abiertos en País Vasco, publica los datos diarios de fallecidos para toda Euskadi una vez a la semana (pestaña 08 de la hoja de cálculo). Por poner un ejemplo: hasta hoy solamente conocíamos los fallecidos agregados en las tres provincias vascas hasta el 15 de noviembre ¡hace 10 días!
Esta serie de datos vale para ver la evolución en la CAPV, pero no por provincia (Nota: sí que se publica en días laborables los fallecidos por hospitales, que era la cifra que usábamos, por aproximación, hasta hace bien poco).
Para construir la serie de fallecidos por provinicas tenemos que recurrir a los datos de fallecidos acumulados que se publican por municipio y una vez a la semana (pestaña 07). Ojo, no se publica el histórico, como sí se hace con los casos o los hospitalizados. Esto es, si quieres saber los fallecidos que había habido en un municipio en determinada fecha no puedes saberlo, porque el archivo que se publica sobre escribe al anterior. Tampoco puedes saber los fallecidos en una determinada semana, porque el dato que se publica es el total acumulado de muertes.
Esto cambió el 20 de octubre de 2020, tras solicitar que fuera posible acceder al histórico de archivos publicados. Además habría que comparar dos archivos para poder calcular el incremetno de muertes de una semana a otra. No nos engañemos, una tarea que nadie va a realizar. A pesar de la buena noticia de que ahora sí se guardan y se publican en abierto los archivos anteriores para permitir trazabilidad… las fechas anteriores al 20 de octubre siguen sin ser accesibles… a no ser que alguien haya guardado todos los archivos que se hayan publicado diariamente… y ¡nosotros lo hemos hecho! (esto es como el he “estudiado a Agrippa” de La Princesa Prometida).
Así que de este modo, no sin un poco de sudor, hemos podido reconstruir la serie histórica de fallecidos por municipios que nos ha permitido construir la serie por provinicas. Un proceso tedioso que implica rescatar con git (el sistema de versiones que usamos) todas las versiones de un archivo, construir la serie y agregar por provincias ¡Por fin tenemos la serie de fallecidos!
Fallecidos diarios por provincias en Euskadi. Se pueden ver los escalones de las últimas fechas al publicarse los datos de forma semanal. Para los últmos días se usan los datos de fallecidos en hospitales. Más gráficos en la web de Escovid19data.
Tenemos un vacio entre mediados de mayo y junio: desde que se dejaron de publicar datos por provincias hasta que se empezó a hacerlo por municipios.
¿Por qué no se publican los datos históricos de fallecidos por municipios, OSI y provinicias? ¿a qué se debe esta opacidad y poner tan difícil una serie de datos que seguro está disponible internamente y que el resto de comunidades autónomas sí publican?
Tenemos más preguntas que ya hemos hecho a Open Data Euskadi, pero las dejamos para otro post.
Esta iniciativa de abrir datos abiertos forma parte del proyecto Escovid19data que recopila colaborativa y voluntariamente datos de COVID-19 en todas las comunidades y ciudades autónomas para ofrecer los datos y gráficos en abierto.
Fallecidos semanales en municpios de más de 10.000 habitantes en País Vasco. Más gráficos en la web de Escovid19data (se cambió la imagen, originalmente tenía un error en los colores),
Muero por datos cuando la administraciones publican datos aparentemente muy detallados pero que impiden ver el bosque.
Un ejemplo lo tenemos con los fallecidos por COVID-19 en Euskadi.
De primeras, si revisas las fuentes de datos que se publican, parece que hay muchos datos disponibles. Si miras un poco más en detalle parece imposible responder a una pregunta básica ¿cómo evolucionan los fallecidos por COVID-19 provincias en Euskadi?
Cada cuál llega con sus preguntas bajo el brazo e intentan que los datos le den la respuesta. En los medios de comunicación locales no he visto publicada la evolución de muertes por provincias.
En mi caso la inquietud forma parte del proyecto de recopilación y visualicación de datos colaborativo Escovid19data, que recopila datos de 19 territorios en España.
Open Data Euskadi ofrece varias series de datos de fallecidos, pero ninguna es la que necesitamos. Este es el listado de los diferentes conjuntos de datos que ofrecen:
Serie de fallecidos acumulados para todo Euskadi. Acumulados diarios del 24/02/2020 al 15/07/2020. Luego los datos pasan a publicarse semanalmente ¿por qué? Última fecha disponible 25/10/2020. Hace 16 días.
Serie de fallecidos diarios para todo Euskadi: “Casos positivos fallecidos en Euskadi por fecha de fallecimiento”. Datos diarios del 01/03/2020 al 01/11/2020 (hace 9 días). [2.212 acumulados]
Serie de fallecidos diarios por hospitales en Euskadi. Datos diarios del 01/03/2020 al 08/11/2020 desagregados por hospitales y el total diairo [1.528 acumulados].
Acumulados de fallecidos en cada municipio de Euskadi. No se ofrece la serie de datos temporales, se da el dato de la última fecha disponible con periodicidad semanal. Última fecha disponible 2020/11/01, hace 10 días.
Este último conjunto de datos es el que nos puede proporcionar la serie temporal de fallecidos por municipio y, por tanto, por provincia, si los agregamos convenientemente. Solamente podremos reconstruir la serie temporal si antes hemos ido descargando los archivos semana a semana. (El histórico de archivos publicados por Open Data Euskadi solamente está disponible desde el 20 de octubre 2020. Es buena noticia pero insuficiente para nuestro propósito).
Con un script de git es posible obtener todas las versiones de un archivo y poder reconstruir la serie temporal.
Esperamos que Open Data Euskadi se anime a publicar la serie completa de fallecidos por provincias, como ha hecho recientemente con la serie de casos por franjas de edad. Originalmente se publicaba exclusivamente en datos diarios sueltos en los informes en PDF y ahora es una serie más de datos abiertos.
¿Por qué publicar una serie de casos detectados por provincias y no la de fallecidos?
Para mi tesis sobre cobertura de corrupción en España llevo tiempo recopilando tuits. Llevo el seguimiento de mensajes de Twitter relacionados con algunos casos de corrupción, para luego poder compararlos con cómo los medios de comunicación han hablado del tema.
Utilizo t-hoarder, desarrolllado por Mariluz Congosto, para capturar tuits según se van publicando. Lo tengo instalado en un servidor remoto que está continuamente descargándose tuits que contienen una determindad lista de palabras. Con un interfaz en la línea de comandos desarrollado en python permite interactuar de manera sencilla con la API de Twitter para obtener y procesar tuits descargados (ver este manual que escribimos hace un tiempo para aprender a usarlo).
T-hoarder guarda los tuits en archivos .txt en formato .tsv. Cada cierto tiempo comprime el archivo streaming_cifuentes-master_0.txt en uno comprimido streaming_cifuentes-master_0.txt.tar.gz que contiene entre 150.000 o 250.000 tuits.
En el servidor se van acumulando estos archivos comprimidos que me descargo periódicamente con rsync: rsync -zvtr -e ssh numeroteca@111.111.111.111:/home/numeroteca/t-hoarder/store/ .
Con ese sistema tengo un directorio con múltiples archivos de los diferentes temas que voy capturando:
El primer paso consiste en entender de forma básica qué he conseguido recopilar. Hay múltiples razones por las que puedo tener agujeros en los datos: el servidor se llenó, el acceso a la API de Twitter se interrumpió por algún problema de permisos, etc.
Para ello he desarrollado este pequeño script en bash para obtener la información básica que contiene cada archivo de tuits:
Este script lee todos los archivos como streaming_cifuentes-master_20.txt y va guardando en cada línea del archivo mycifuentes.txt en líneas separadas: el nombre del archivo tar.gz, la fecha y hora del primer tuit (head) y del último (tail) y por último el número de tuits. Con eso obtengo un archivo como este:
Que proceso a mano en gedit son sustituciones masivas (me falta generar mejor el tsv donde cada campo esté en la línea que le corresponde):
Actualización 8 junio 2020: Gracias a @jartigag@mastodon.social que me llegó por Twitter no me hace falta el procesado manual ya que cada dato va a su propia columna:
lo que hace es leer el archivo (read_tsv) y cuenta las horas entre el primer y último tuit y calcula los tuits por hora:
Ahora ya podemos hacer las primeras visualizaciones para explorar los datos. En este primer gráfico cada línea es un archivo que va del primer al último tuit según su fecha. En el eje vertical se indica el número medio de tuits por hora. En el caso del master de Cifuentes el primer archivo no se comprimió por error y contiene 828.374 tuits. el fondo gris indica cuando no hay tuits descargados. Hay un periodo en blanco la inicio del caso y otro en diciembre de 2019, la escala vertical es logarítmica, para que se puedan ver todos los archivos incluyendo los primeros.
En este otro gráficos (escala vertical lineal) muestro los archivos de tuits que he capturado de unos cuantos medios de comunicación españoles, para luego poder comparar las diferentes coberturas, vuelvo a tener agujeros para los que todavía tengo que encontrar explicación.
En este otro gráfico comparo la fecha del archivo con el número de tuits que contiene:
Este es un primer análisis muy “meta” que no entra ni de lejos a analizar el contenido de los tuits pero me sirve como primer paso para entrar en faena a analizar los datos que tengo. Tenía que haber hecho esto hace tiempo. En cualquier caso bueno es ponerse en marcha y documentar. Mis conocimientos de bash son escasos pero creo que merece la pena y es más rápido en este caso que usar R. Inspirado por este libro que estoy a medio leer Data Science at the Command Line de Jeroen Janssens.
5 Easy Facts About https fortnite com 2fa Described buy testosterone cypionate 250mg ski-in/ski-out hotel sport, saas-almagell: find the best price
Nota: no soy experto en epidemias ni en medicina. Me he limitado a plasmar gráficamente los datos publicados por el Ministerio de Sanidad. Si ves errores en los gráficos o de concepto, házmelo saber. Son datos de casos registrados, no tienen en cuenta los protocolos para obtención de datos (pruebas) de cada comunidad autónoma ni todos los casos “reales” que hay pero no han sido detectados.
Errores por resolver: la bajada de datos en Galacia en una base de datos acumulativa debe ser un error. Estamos mirando a qué puede deberse.
Hemos montado desde Montera34 una web para mantener actualizados estos datos en lab.montera34.com/covid19/
Cuando ayer publiqué una reflexión sobre lo que estaba pasando en relación al COVID-19 y la necesidad de autoencerrarse para la parar su propagación, no había mirado si había gráficos de evolución por comunidad autónoma en España. Sí que encontré mapas de “bolas”, tablas con el número por comunidad autónoma, pero no su evolución en el tiempo.
Lo primero que encontré fue el repositorio de datos por países (y algunas provincias y estados) que recopilan desde la universidad de Johns Hopkins y que se pueden ver en este dashboard de Rami Krispin. Sin embargo, lo que buscaba eran datos desagregados por comunidad autónoma o provincia en España, y esos no estaban disponibles. Quería conocer el avance del virus en mi entorno más cercano.
Encontré que el Ministerio de Sanidad, Consumo y Bienestar Social los estaba publicando en PDF (!) en informes diarios desagregados por comunidad autónoma. Cuando estaba descargando todos los PDF encontré que desde Datadista los habían pasado a un formato reutilizable. Alegría, visitad su respositorio. (Todavía no sé de qué PDF han sacado los datos previos al 3 de marzo, espero aclararlo cuando pueda).
Con los datos a mano monté un repositorio de R para analizar cómo estaba evolucionando la propagación por comunidad autónoma. Estos son los resultados.
Número de casos registrados
Lo primero es ver el número de casos registrados por cada comunidad autónoma. Un “small multiple” parece una buena opción para ver cada uno de los lugares:
Podemos ver los mismos datos superpuestos en el siguiente gráfico, donde se aprecia que la pendiente es similar en cada línea. Una línea recta en una escala logarítmica indica que el crecimiento es exponencial. Madrid encabeza en número de casos seguido de País Vasco y Cataluña.
Si profundizamos un poco más podemos calcular los datos relativos a la población de cada comunidad autónoma. Aunque el número de casos acumulados es lo que muchos quieren saber, el relativo a su población nos puede permitir entender mejor lo que está pasando. En este caso representamos a los casos acumulados de COVID-19 por millón de habitantes:
La Rioja pasa del 4º al primer puesto con 647 por cada millón de habitanes, seguido por Madrid (208), País Vasco (156) y Navarra (111).
Número de ingresos en la UCI
Miremos ahora los casos registrados de personas en la UCI (Unidad de Cuidados Intensivos):
Madrid (135) parece está a la cabeza claramente en número de ingresos en la UCI por el COVID-19, seguida de Euskadi (18), y Castilla-La Mancha (9):
En números relativos también es la comunidad de Madrid la primera con respecto a su población, tiene 20,3 por cada millón de habitantes, seguida de Euskadi (8,2) y Navarra (4,6):
Fallecimientos por COVID-19
El número total de fallecimientos registrados por COVID-19 a día 12 de marzo de 2020 ascendía a 84 en toda España.
En números totales la Comunidad de Madrid va primera en fallecimientos con 56, muy lejos de Euskadi con 11.
Sin embargo, si lo relacionamos con su población, vemos que las diferencias no son tan grandes. La Rioja (6,3 fallecidos por cada millón de habitanes) pasa a estar muy cerca de Madrid (8,4), les siguen Euskadi (4,9) y Aragón (4,5).
Todo el código para producir estos gráficos está en este repositorio: https://code.montera34.com:4443/numeroteca/covid19. Os animo a echar un ojo y ayudar a mejorarlo. En la carpeta de imágenes podéis encontrar todas las que no han tenido cabida en este artículo.
Los datos representados son de casos registrados, según otros análisis, hasta que pasen varias semanas no sabremos
A petición popular subo este gif animado que representa los mismos datos, número de casos registrados por comunidad autónoma en España cambiando la escala del eje vertical:
escala líneal,
escala logarítmica y
escala logarítmica y casos por millón de habitantes.
A la izquierda escal lineal y a la derecha logarítmica
En la escala lineal solo se aprecia de manera clara los datos de Madrid.
Comparativa escala logarítmica y lineal en el eje vertical.
He analizado los titulares de las páginas de inicio de algunos periódicos online antes del #28A para medir la cobertura de los principales partidos de ámbito estatal. Cuento nº de titulares que contengan los nombres, siglas o líderes de cada partido #homepagex c @PageOneXpic.twitter.com/QzO7jan2ao
He analizado los titulares de las páginas de inicio de algunos periódicos online antes del #28A para medir la cobertura de los principales partidos de ámbito estatal. Cuento nº de titulares que contengan los nombres, siglas o líderes de cada partido #homepagex c @PageOneX
He calculado también el porcentaje de esos titulares sobre el total de titulares de cada página de inicio #28A. Una forma de medir automatizadamente la cobertura que realiza cada medio.
Y aquí agrupando por partido, que facilita la comparativa entre cabeceras. Las líneas finas son los datos por hora y las más gruesas el redondeo que permite ver las tendencias más fácilmente #28A
Son análisis preliminares mientras refino la herramienta. Encantado si queréis aportar vuestra lectura y crítica. Hoy no me dará tiempo a más. Se basan en una base de datos que recopila hora a hora las páginas de inicio de cada periódico
Este curso he empezado como profesor colaborador de la asignatura de Periodismo de datos para estudiantes del máster de ciencia de datos en la Universitat Oberta de Catalunya (UOC). A principios de año preparamos desde Montera34 (con Alfonso) tres ejercicios prácticos sobre análisis y visualzición de datos: análisis de Twitter, de datos de Airbnb y sobre segregación escolar.
Para dinamizar la clase y dar algunas referencias que he ido viendo estos días he escrito lo siguiente en el foro de la clase:
Recopilo en este hilo algunas referencias que pueden ser de interés e inspiración:
A raiz de un hilo de correo sobre uso de las redes sociales en Internet en Wikitoki y de nuestras infraestructuras digitales, he enviado esto sobre Montera34:
Nuestra web (montera34.com) como centro de comunicaciones: publicamos anuncio de actividades que luego son el archivo (recopilación de documento de la actividad). Si no llegamos a tiempo para anunciar, se publica el proyecto/actividad a toro pasado, para el archivo. Una vez se publica en la web se empieza la difusión en las diversas redes.
Wiki: para documentos activos en colaboración con otras gentes. Documentación de talleres, manuales, recetas, investigaciones abiertas. Ver la del proyecto Efecto Airbnb, por ejemplo: wiki.montera34.com/airbnb
Newsletter: sin periodicidad clara pero más o menos cada mes. Anuncio de protyectos/actividades futuras o pasadas. La hacemos con un pllugin desde nuestro WordPress (montera34.com/suscribete).
Repositorios de código: usamos github.com y nuestra propia guenta de gitlab en nuestro server. Ver código de proyectos (montera34.com/project-list).
Servidor autónomo: todo ello alojado en nuestro server asociativo que pronto será una máquina propia: hosting.montera34.org
Redes
Twitter: canal más activo de redes sociales en internet donde publicamos o RT cosas en proceso, anuncios, respondemos preguntas. Tanto desde la cuenta de @montera34 como de las nuestras personales. Se publica info ya publicada en la web. Es el canal donde estamos más activos. También manejamos otras cuentas de proyectos en que colaboramos (cadáveres inmobiliarios, bilbao data lab, datahippo, pageonex, kulturometer…).
Instagram: abierta pero poco activa. Se publica info ya publicada en la web.
Google+: la teníamos poco activa, y ya por fin google va a cerrar el servicio.
Youtube: para publicar los streamings y hangouts en directo que hacemos.
Facebook: lo mismo que las otras. Se publica info ya publicada en la web… si llegamos a tiempo. Cada vez menos.
En resumen: intentamos publicarlo todo en nuestras propias infraestructura para luego redifundirlo por otros canales. En Twitter es donde más conversamos con otros.
Too long & do not read Spanish: How to parse and make the visualizations based on the archive of digital home pages built with storytracker: R code available.
Bueno, por fin puedo ponerme a contar noticias de Cifuentes en portada de los periódicos digitales. A ver qué sale:
Para poder el porcentaje de noticias sobre Cifuentes en portada necesitamos saber cuál es el total de noticias en cada momento (cada hora) en cada periódico:
Noticias en portada por hora en eldiario.es.
Después hay que contar los titulares en portada de las noticias que contienen “Cifuentes” (y palabras relacionadas con el caso de su máster) para un periódico. Ejemplo con eldiario.es:
Número de noticias en portada en eldiario.es sobre Cifuentes.
Para hacer el cálculo del número de noticias se han elegido todas aquellas que incluyen una de las siguientes palabras o grupos de palabras en su titular: “Cifuentes|Javier Ramos|Enrique Álvarez Conde|Pablo Chico|María Teresa Feito|Alicia López de los Cobos|Cecilia Rosado|Clara Souto|Amalia Calonge|Universidad Rey Juan Carlos”.
Paseando con el globo para fotografiar desde el aire el polígono industrial El Serrallo, en el puerto de Castellón de la Plana.
After a very long and exhausting peer review process, we started this back in 2014, the paper we co-wrote with Hagit Keysar, Shannon Dosemagen, Catherine D’Ignazio and Don Blair is finally up there: “Public Lab: Community‑Based Approaches to Urban and Environmental Health and Justice”.
Abstract
This paper explores three cases of Do-It-Yourself, open-source technologies developed within the diverse array of topics and themes in the communities around the Public Laboratory for Open Technology and Science (Public Lab). These cases focus on aerial mapping, water quality monitoring and civic science practices. The techniques discussed have in common the use of accessible, community-built technologies for acquiring data. They are also concerned with embedding collaborative and open source principles into the objects, tools, social formations and data sharing practices that emerge from these inquiries. The focus is on developing processes of collaborative design and experimentation through material engagement with technology and issues of concern. Problem-solving, here, is a tactic, while the strategy is an ongoing engagement with the problem of participation in its technological, social and political dimensions especially considering the increasing centralization and specialization of scientific and technological expertise. The authors also discuss and reflect on the Public Lab’s approach to civic science in light of ideas and practices of citizen/civic veillance, or “sousveillance”, by emphasizing people before data, and by investigating the new ways of seeing and doing that this shift in perspective might provide.
Rey-Mazón, P., Keysar, H., Dosemagen, S., D’Ignazio, C., & Blair, D. (2018). Public Lab: Community-Based Approaches to Urban and Environmental Health and Justice. Science and engineering ethics, 24(3), 971-997.
We used three different case studies to: Aerial Photography and Community Building in Castellón, Spain, 2014; The Aerial Testimony: Silwan, East Jerusalem, Israel/ Palestine, 2011; and Open Water Science for Civic Veillance.
Cuando me preguntaron si podía hacer unas visualizaciones de los datos sobre segregación escolar en la escuela pública y privada en Euskadi para la Iniciativa Legislativa Popular (ILP) por una escuela inclusiva me interesó mucho el tema. Veo en mi entorno más cercano de Bilbao unas diferencias grandes entre una y otra red escolar, pero no me había parado a estudiar con datos el tema.
No conocía la definición exacta del término “segregación”. Imaginaba que sí existían desigualdades socioeconómicas entre quienes atiende a las redes pública, concertada y privada en Euskadi, pero no había pensado cómo medirlo.
Según una definición la segregación escolar es el fenómeno por el cual los estudiantes se distribuyen desigualmente en las escuelas en función de alguna de sus características” y que es “por tanto, uno de los factores que contribuyen en mayor medida a impedir una verdadera igualdad de oportunidades y generar desigualdad social” como explican Murillo y Martínez-Garrido en un artículo publicado este año. Hay mucha literatura al respecto, que luego he ido conociendo, pero en un primer acercamiento nos pusimos a trabajar y trastear con los datos que teníamos disponibles.
Para estudiar las desigualdades entre las redes pública y privado-concertada de los centros educativos en Euskadi usamos los datos disponibles en el informe La educación en Euskadi 2013-2015 del Consejo Escolar de Euskadi.
Desde hace un tiempo nos rondaba en Montera34 a Alfonso y a mi la idea de ponernos de nuevo con los datos de las tarjetas black. El juicio donde se juzgaba a los directivos de Caja Madrid y Bankia que habían usado sus tarjetas opacas a Hacienda estaba a punto de acabar. Todavía teníamos un pequeño margen antes de las deliberaciones finales y la sentencia.
En vez de analizar los datos en su conjunto otra vez ¿por qué no cambiar la forma de acercarse a los datos y fomentar ver el detalle de cada gasto? Nos parecía interesante poder tratar los gastos uno a uno y entender cuándo y cómo sucedían. Un ejercicio de “small” data para hacer mininarrativas con tamaño tuit de cada gasto.
La fechas no podían ser peores. Las navidades se acercaban, hacía falta cerrar varios proyectos, líos familiares… un tiempo perfecto para hacer un proyecto en modo exprés y en abierto.
Alfonso reutilizó algo de código de otro proyecto para hacer una página que publicaba los gastos del día. Por suerte teníamos ya los datos recopilados en un único archivo de la otra visualización: unos 75.000+ gastos clasificados por usuario, comercio, tipo de actividad…
A partir de esta primer boceto surgían algunas preguntas ¿se podían buscar otras fechas u otras distancias de años además de la década de distancia?
En principio nos gustó la idea que ahora parece obvia: ofrecer pocos datos para centrar la atención del usuario. Diez años es una cifra fácilmente inteligible por cualquiera.
Luego teníamos que resolver dónde ibamos a publicar la web. El subdominio lab.montera34.com podía valer. Tras un poco de tuneo a los estilos la web empezaba a tomar forma:
Por el camino surgió algo que también parece obvio ahora y que hacía casi todo lo demás del proyecto redundante. Tras comentar con Martín (@martgnz) el proyecto @censusamericans, que convierte cada hora una línea del censo en un tuit, del tipo “I had a baby last year. I don’t have health insurance. I am divorced. I moved last year. I got married in 2000.” nos sugirió tuitear en directo los gastos de las tarjetas black en riguroso directo en diferido.
propone @martgnz hacer un bot que tuitee qué gastaban hace justo 10 años, momento exacto. Siguiendo la idea de @censusAmericans
Ya sólo nos faltaba desarrollar el bot para Twitter… y alguna cosa más.
Nos faltaba un nombre e imagen con gancho. Gracias a hacer el desarrollo del proyecto en abierto Guille nos sugirió Black to the Future. Lo españolizamos a @BlacktoDeFuture y así lo reducíamos a los caracteres necesarios para que cupiera en el nombre de una cuenta de Twitter. Nos gustaba también el Black2thefuture que proponía @jorgelamb, pero ya estaba pillado.
Mientras Alfonso cocinaba el bot hecho en Python me dediqué a lanzar la web para preparar la llegada del bot de Twitter. Publicar los gastos en una sola frase requería algunos retoques. A veces el nombre comercio no figuraba, pero sí el tipo de actividad (cajero, disposición en efectivo…). Con unas cuantas sentencias condicionales en PHP quedaba arreglado. También aproveche mis conocimientos recién adquiridos de R para reordenar todos los gasos por días y hora, así saldrían ordenados en la página de gastos del día.
Ya por entonces nos habíamos dado cuenta de que la web molaba, y mucho, pero que lo realmente iba a funcionar era el bot de Twitter. La web sería la partitura diaría que el bot tiene que seguir. La cuenta de Twitter permitiría seguir en “tiempo real” lo que gastaban los directivos de las black. Unos días después empezabámos a retransmitir:
Desde ya tuiteamos en riguroso diferido de 10 años todos los gastos de las #tarjetasblack ¡No te pierdas el sprint de compras navideñas!
En resumen, acabábamos de lanzar desde Montera34 un bot que tuiteaba todos los gastos de las tarjetas black con 10 años de retraso. Riguroso directo en diferido. Un viaje en el tiempo a otra era. Un viaje a 2006, un país que todavía no se enteraba de que la burbuja inmobiliaria y muchas otras cosas iban a estallar: @BlacktodeFuture.
Hay gastos de las tarjetas black anotados hasta el 29 de agosto de 2012:
2012-08-29 | 14:18:45 | APARCAMIENTO MONTALBAN | GARAJES,RESTO DE APARCAMIENTOS | 15.8€ | COMPRA | Miguel Ángel Abejón Resa
Quién sabe, quizás para el año 2022 todavía sigue funcionando nuestra máquina del tiempo y vayamos a celebrar el fin de su viaje al aparcamiento de la calle Montalbán en Madrid.
Hemos hecho la selección buscando iniciativas quedesde distintos ámbitos de acción,están proponiendo un impacto sobre el desarrollo urbano (y urbanístico) sostenible en su entorno. Iniciativas que, en mayor o menor medida hibridan entre el trabajo socio-comunitario, el urbanismo participativo, la arquitectura, y las prácticas culturales y artísticas para imaginar conjuntamente soluciones para un desarrollo urbano sostenible. Proyectos que tienen que ver con la regeneración urbanística y arquitectónica de barrios, la recuperación de patrimonio industrial para usos culturales y comunitarios, el empleo de la cultura como herramienta transformadora del territorio, la reapropiación del espacio público, la reutilización de residuos para la construcción de espacios comunes, el replanteamiento de los mercados de producción y consumo, el desarrollo de plataformas en red para visibilizar vacíos urbanos.
Cadáveres Inmoiliarios compartirá presentación exprés con todas estas experiencias el miércoles 23 de Noviembre a las 19.00h en Bizkaia Aretoa (Bilbao), en una sesión abierta y gratuita par todo el público. Consigue tu entrada gratuita y más información sobre la sesión.
El día siguiente, en un taller interno, compartiremos experiencias y realizaremos una consultoría entre pares que ayude a enriquecer y mejorar cada uno de los proyectos.
Justo ayer, el día que empezaba a declarar Correa en el juicio de la primera época de la Gürtel, me ha llegado la noticia. Ha sido aprobado el proyecto de tesis y plan de investigación “The color of corruption coverage in Spain” (descarga el pdf) que presenté en mayo. Así que ya soy oficialmente doctorando. Sólo me queda hacer la tesis. Correa es el acusado clave de la trama y por el que toma nombre el caso Gürtel, que es “correa” en alemán.
Ahora un resumen de los últimos acontecimientos en cunato a la tesis se refiere.
Data gathering in the age of information
It’s been a busy week. Almost all the tasks are related to data gathering: tweets, front pages or video streaming. It is interesting how non trivial is to gather all the different information flows that surround as.
Researched different ways of “hunting” tweets. This reminds me to the uncompleted experiment I launched for collecting tweets with different methods.
Check out this scripts:
Cheered Mari Luz Congosto to relaunch t-hoarder.com, a platform that collects, visualizes and archives tweets about corruption in Spain. It is the main I plan to use for my PhD dissertation. I am going to help her document the tool to allow other researchers/activists install, use it and… share their data!
By the way, we are looking for other people interested in installing their own instances of t-hoarder… or hosting our own instance. Do you have empty space in your server?
I’ve been recording the video streaming of the Gürtel trial, one of the main cases of corruption in Spain that involves the party in the government (PP), as I am not finding any public archive that does it for me. I’ve used Kazam to do it, so it means that I have to be there at the right moment. It is like going back to he ’80-’90 and recording with VHS.
I have the video recording, the tweets of the day, the screenshots of the main online newspapers… I’ll be able to reconstruct on an minute basis one day in the media ecology of that particular corruption case.
Answers from reviewers to the thesis research plan
Hypothesis too general “hypotheses are too general. Here is my recommendation: the candidate defines the hypothesis thinking on the connection between the dependent and independent variables”.
Operationalization of variables and independent variables “The candidate will use three types of data, one related to front-pages of print media, another with the information about twitter, and public opinion. To do that the candidate not only will follow existing methodologies but will also use pageonex.com (elaborated by the author). Here it will be relevant to know something else about the operationalization of variables. I guess the unit of analysis is going to be stories (number of percentage?), tweets (number?), public opinion (percentage?) for one or two years (2016-2017). Also we need more information about which are the independent variables that will be taken into account. In general the methodology seems as appropriate for the plan but needs further elaboration in the future”.
Define agenda setting role of media, traditional vs new media, analyze literature
“In general, it is clear the author has analyzed some of the main contributions to the field, but there are some important shortcomings. There is not a discussion about which is the agenda setting role of the media, what we mean by that, why this is important, and which are the factors that limit the capabilities of the new and traditional media to develop this agenda setting role. (…) Accordingly, the theoretical part needs an elaborated discussion about the agenda setting role of the new and traditional media, highlighting the similarities and differences between the two and why this matters. To do that the author needs to analyze the literature about agenda setting taking into account authors like Norris to better understand the role of the media in a democracy, Graber and Iyengar to explain the agenda setting role of the media and the interconnection between different types of media outlets, Hallin and Mancini to better understand the media systems and why this matter (just to mention some of the most cited).
Add asocial movemente theory and atudy anti-corruption activist
“Suggest the author add an additional RQ / hypothesis about anti-corruption activists attempts to influence the mass media agenda, outside of social media (through meetings, petitions, protests, and so on). Do anti-corruption protests shift the mass media agenda? (…) The author may want or need to develop additional data (qualitative and/or quantitative) about attempts by anti-corruption activists to shift the mass media agenda. For example, a dataset of anti-corruption protests, by size/participation, and/or analysis of interviews with anti-corruption activists. (…) the dissertation might benefit from a section that engages significantly with the social movement studies literature. Specifically, there is a subfield of social movement studies that explores the ways that social movement actors attempt to gain access to mass media visibility, and in the context of the Spanish corruption cases, presumably this is taking place extensively. This introduces additional possibilities and questions about mass media agenda setting. For example: are there social movement actors who have personal friends among journalists, editors, and other members of the mass media? Potentially, they are meeting, lobbying, talking with, protesting, and otherwise attempting to shift the mass media agenda to cover corruption, NOT ONLY via social media but also through face to face methods, phone calls, petitions, meetings, perhaps direct actions, advertiser boycotts, and so on. Also: do anti-corruption protests shift the news agenda?”
Mejor conexión entre los ámbitos de la investigación
“Faltaría, en algunos casos, trabar mejor la transición o la interconexión entre los distintos ámbitos de la investigación. En especial faltaría una mejor/mayor justificación de la (supuesta) disrupción que hacen los medios sociales en el panorama informativo y su papel de contrapeso con los medios tradicionale. (…) La parte del impacto de los nuevos medios en el establecimiento de la agenda debería reforzarse para que no quede coja respecto al resto de marco teórico. Por otra parte, la retroalimentación mútua entre los viejos y los medios nuevos/digitales debería perfilarse mejor para poder acabar de definir la metodología”.
¿Qué preguntas hacer a los datos pra no desbordarse?
“La metodología es muy robusta y utilizará sobre todo dos grandes fuentes de datos, extensas, objetivas y relativamente fáciles de manipular. En este sentido, el reto será saber qué preguntas hacerles a los datos – de las muchas posibles dada la riqueza de los mismos – para que la investigación no se desborde”.
Falta mayor profundidad en el planteamiento “Sí, los objetivos, las preguntas y las hipótesis son claras y fundamentadas en el debate teórico. Sin embargo, falta una cierta profundidad de planteamiento que se queda en lo descriptivo. Ciertas cuestiones de fondo quedan implícitas o marginadas, como si la polarización es mayor en las redes sociales que en los medios de referencia o si los casos de corrupción preeminentes en ambas esferas (redes digitales y medios convencionales) difieren en cuanto a sus protagonistas. La primera cuestión se relacionaría con las dinámicas de polarización que se atribuyen a la esfera pública digital y la segunda, con el control que se atribuye a las fuentes oficiales en la agenda de los medios convencionales de referencia y a los alineamientos político-edioriales que se han percibido en la prensa española. Se recomienda un mayor énfasis en estas preguntas para facilitar un debate académico que haga aportaciones más allá del caso de estudio nacional que ahora se plantea”.
Falta autores españoles anteriores al año 2000
“La bibiliografía recoge en extenso las principales contribuciones en el orden teórico y empírico, en el plano nacional e internacional. Se echa en falta, sin embargo, el conocimiento y la referencia a obras de autores españoles anteriores del año 2000 y anteriores que abordan el tema de la construcción de la agenda y de los marcos discursivos tanto en la teoría como en análisis de casos”.
El otro día comparábamos el número de votantes con el de abstencionistas con una visualización donde cada punto equivalía a 10.000 personas. Se podía evaluar el peso de la abstención y de los votos en blanco y nulos, que no suelen reprentarse en las estadísticas electorales.
Si actualizamos los datos con los resultados de 2016:
podemos ver que el aspecto general es bastante parecido, aunque sí hay diferencias. Para poder apreciarlas es necesario poner una visualización al lado de la otra:
Aquí sí se puede percibir el aumento de la abstención (gris), el aumento de votos del PP (azul), pero el descenso en PSOE, Podemos y Ciudadanos es más complicado de apreciar. El gráfico es válido para hacerse una idea de los datos en su conjuto, pero para comparar valores entre sí, no es la mejor forma: los colores comienzan en filas diferentes y en diferentes lugares de cada fila. Para poder comparar valores tenemos que alinear los inicios de cada partido:
De este modo podemos ver mucho más claramente el aumento de votos del PP y el descenso de los otros partidos. Este método nos permite además poner a IU junto a Podemos (y confluencias) en las elecciones de 2015, cuando se presentaban por separado y poder comparar los resultados cuando se han presentado en confluencia en Unidos Podemos. Esta visualización está pensada para mostrar el peso de los abstencionistas.
Actualización 28 junio 2016: Incluyo una mejora de la visualizacióncon los
Por último os dejo con un gráfico de barras. Sólo suben en votos la abstención, el PP y el PACMA, de entre los partidos más votados.
Todo empezó por el cansancio que me producen los mapas que colorean las regiones con el color del ganador. A cualquiera le alarmaría un mapa como este:
no porque gane el PP, sino porque da una información muy incompleta fácilmente malinterpretable. Un partido con el 28,7% de los votos emitidos colorea toda las superficie.
Conceptualmente no es muy diferente a este otro, donde se colorea cada municipio con el color del ganador. El nivel de detalle es mayor, por lo tanto vemos más datos, pero creo que el problema sigue siendo el mismo.
Todos comparten el mismo problema the winner takes it all, esto es, aunque en una región haya ganado un partido por un 2% toda ella quedará pintada del mismo color. Prefieron n veces el mapa con el nivel de detalle de los municipios, pero nos sigue representando solamente a los ganadores en uan realidad simplificada. Algunos mapas trabajan con gradientes de los colores para indicar cuánto es el porcentaje de votos de cada partido, como en este buenísimo mapa interactivo:
El gradiente aumenta la información que se ofrece al usuario, pero creo que sigue siendo insuficiente si lo que queremos es analizar un sistema de más de 2 jugadores que comparten porcentajes de voto similares. No se trata de mayor nivel de detalle, sino de poder representar en un mismo gráfico al segundo, tercer y cuarto más votados. Se han probado gradientes entre 2, 3 ó 4 colores, pero si ya es difícil interpretar en valores numéricos un gradiente, imaginad lo complicado que es interpretar un color mezcla de distintas intensidades de azul, rojo, morado y naranja.
Si a eso le sumamos que queremos ver a las personas que no han ido a votar y nos olvidamos del mapa de momento… sale algo como la siguiente visualización, donde cada punto representa 10.000 votos en las pasadas eleciones de diciembre de 2015 al congreso:
Uno de cada cuatro personas con derecho a voto no fue a votar. Los puntos en gris representan a los más de 9 millones de personas que se abstuvieron. Estamos tan acostumbrados a leer los porcentajes de los que votaron, a ver los semicírculos coloreados que representan el congreso, a ver los mapas de los ganadores, que se nos olvida que existen los que no ejercieron su derecho. Ya sabemos que España no es bipartidista, pero tampoco es de cuatro (y algunos más) colores.
Si agrupamos por comunidades autónomas saldría algo así [nota, faltan los votos a Ciudadanos en Galicia]:
Y en un primer acercamiento al mapa saldría algo así:
que es una interpretación de una idea de Mark Monmonier para mejorar algunos problemas de los mapas con gradientes de color o “choropleth maps“.
Después de unos ajustes al resumen que preparé para el seminario de hace unas semanas he presentado el Abstrac Research Plan a la comisión de doctorado. El cambio principal es centrar o dar más peso al estudio de las redes sociales (social networking sites) en el ecosistema de medios, que son que ha cambiado el panorama de la comunicación en los últimos tiempos. Dentro de “mass media” incluyo “news media” y “social media“. La idea es usar el caso de la cobertura de corrupción para realizar esta investigación.
A finales de mes tengo que presentar el plan de investigación completo (4.500 palabras) así que ya estoy trabajando en ello. A ver cómo este nuevo enfoque me hace reestructurar y escribir lo que tenía hasta ahora.
Mientras, pastpages.org se ha puesto a funcionar para capturar las portadas de los principales diarios online que le pasé a Ben Welsh ¡thank you! No está funcionando del todo bien, no todos los periódicos aparecen etiquetados como “Spain” pero ya va empezando a existir el archivo de periódicos online en España. De momento sólo archiva la imagen de la portada, no el código html. Esa funcionalidad solamente está disponible para ciertos periódicos.
Además, tendré que leer las recomendaciones de Ismael Peña, mi tutor, sobre el tema de la influencia de los social media. Jóvenes clásicos que hay que no he leído todavía que me ayudaran a tratar el tema de la importancia de los medios sociales en la web: hablan del “daily me” en Being digital (1996) de Negroponte, las “echo chambers” en Republic.com 2.0 (2009) o sobre amateurs “Our social tools remove older obstacles to public expression, and thus remove the bottlenecks that characterized mass media” en Here comes everybody: How change happens when people come together (2009) de Shirky.
Pego aquí el abstract que entregué este domingo. Se aceptan y agradecen consejos, sugerencias.
Title: The color of corruption coverage in Spain. Agenda setting in a polarized media ecosystem.
Objectives, hypothesis and questions
By selecting and framing stories mainstream media help determine what is important and what not. Mass media play then a key role in shaping public opinion. Since the seminal article The agenda-setting function of mass media was published in 1972, and specially during the last decade, we have witnessed the emergence and the growth of influence of social media. Social media users (writers/readers) help to disseminate the news, but are also able to participate directly in the selection, creation and framing of the stories to modify the agenda setting traditionally dominated by the mainstream media (Negroponte 1995; Shirky, 2008; Sunstein, 2001). News media remain as key players in mass media ecosystem but they are no longer alone in the way political reality is shaped. How are social networking sites changing the agenda-setting role of traditional media?
How is the dialogue between social networking sites and mass media and how they drive attention to certain stories? We will use the topic of corruption in Spain to study this question.
In the past years, corruption cases in Spain have involved almost every institution in the country. These scandals are usually brought to light by news media and amplified by social media. Every week, a new investigation is unveiled provoking an increasing sense of indignation. As there is a wide range of actors involved in the scandals it makes corruption an appropriate field of research to analyze the role of social media in a polarized media ecology, where Spanish media outlets are traditionally aligned with political parties.
We will research the different variables that shape mass media coverage and public perception such as the main actors involved in a corruption case, the medium where it is published, the publicity given to the story or when it is published. Through the analysis of corruption coverage we are going to measure how news media protect or attack certain parties and institutions by hiding or promoting certain stories. The underlying objective is to update theories about the Spanish partisan media ecosystem.
In a system where people select the newspaper more aligned to their ideology: what comes first, the agenda setting and framing by mass media or the general public predisposition? We are specially interested to see how the situation evolves in a political situation that is shifting from a bipartisan system to a four players game, where new online news sites and networking sites are entering with strength the mass media ecosystem.
Methodology
The unit of analysis of this research are corruption stories in front/home pages of paper and online newspaper newspapers and social media messages in Twitter. We want to measure the importance given by the mass media to certain topics and compare it to the discussion in social media so that we can infer similarities and differences in both their characteristics and determinants.
We will quantify corruption coverage by measuring: the number of news; the size, by using the percentage of surface dedicated to the topic; the “color”, which institution was related to corruption. Informed by other studies and literature in the field of corruption coverage and media studies (Rivero & Fernández-Vázquez, 2011; Baumgartner & Chaqués Bonafont, 2015) we will also study the framing of corruption (Costas-Pérez, Solé-Ollé & Sorribas-Navarro, 2012), whether the coverage is neutral or negative or defensive and giving a positive view.
Whereas front page analysis is not new, we propose the use of new methods to have better and more accurate metrics that take in account size and visual aspect of the analyzed stories. We are going to use PageOneX.com to analyze front pages of paper newspapers and StoryTracker (http://storytracker.pastpages.org/) to analyze home sites of online news sites. Our collection of data can also be compared with other analysis of front pages conducted by the Spanish Policy Agendas project (Chaqués-Bonafont, Palau & Baumgartner, 2014) in the two largest newspapers in Spain: El País and El Mundo.
To analyze social media messages in Twitter we will use the software and data set developed by Mari Luz Congosto at the Universidad Carlos III available at http://t-hoarder.com/. We will quantify conversations about topics by the number of messages, retweets, number of users and the topic they are referred to. We will also analyze user networks and the dissemination of tweets by the mainstream media in Twitter.
To provide related information to our stories data set and in order to measure impact in public opinion we are using two different approaches, existing public opinion surveys and focus groups.
The monthly national survey, “the barometer”, of the Centro de Investigaciones Sociológicas (CIS), that asks about the three more important problems for citizens, where corruption and fraud is since 2013 in the top three.
Focus groups to provide context to understand how people “read” front pages, how they judge about scandals along personal ideologies. We want to contrast data from media coverage with direct perceptions of readers. Participants will be selected to have diverse affinity to political parties and different ideologies. We will use the newspapers front pages of the week as a starting point for a conversation about corruption.
–
Próximamente espero renovar el tema de wodpress de este blog. Stay tuned!
ESS Visualisation Workshop 2016. Valencia. May 17-18, 2016.
Abstract
Data visualizations are a powerful way to display and communicate data that otherwise would be impossible to transmit in effective and concise ways. The spread of broadband Internet, the easier access to reusable datasets, the rise in read/write digital media literacies, and the lower barrier to generate data visualizations are making mass media to intensively use of infographics. Newspaper and online news sites are taking advantage of new, affordable and easy to access data visualization tools to broadcast their messages. How can these new tools and opportunities be used effectively? What are good practices regarding data visualization for a general audience?
After an introduction to a series of key concepts about visualizing data the lecture will follow with an analysis of a series of significant data visualizations (tables, pie and bar charts, maps and other systems) from TV, daily newspapers and news websites to detect good and bad practices when visualizing statistical information. The lecturer will then analyze recent literature of visualization studies regarding persuasion, memorability and comprehension. What are more effective embellished or minimal data visualizations? Does graphical presentation of data make a message more persuasive?
Presenta el trabajo dentro de la unidad de datos de El Español.
Repaso a las diferentes unidades de datos en los principales medios de comunicación en España:
El Confidencial 2013
El Diario 2014
La Sexta 2015
El Mundo 2015
El Español 2015
Cuatro perfiles básicos:
Periodismo de investigación
Programació nde en python o R para scraping y análisis
Manejo de bases de datos y excel para análisis
Desarrollo en html y javascript
¿Qué e periodimo de datos? “Recopilar y analizar grandes cantidades de información y datos derallados para hacerlos comprensibles a la audiencia a través de artículos, visulizaciones o aplicaciones”.
En El Español trabajan desde dentro de la redacción en colaboración con todas las secciones. También desarrollan proyectos propios.
Repaso a leyes de transparencia:
Leyes de Transparencia
Ley de Transparencia España Ley 19/2013
En vigor para autonomías y entidades locales desde el 10 de diciembre de 2015.
– Ley de derechos de acceso a la infomración Medio Ambiental (Ley/2006)
– Regulación de la Unión Europea (1049/2001)
Desde El Español han trabajado pidiendo datos a la administración. Una actividad normal en otros países pero que en España no se tiene la costumbre.
Que se llame “Periodismo de datos” da idea de que todavía estamos en momentos iniciales de la disciplina en España. En otros países se llama simplemente “periodismo” o “periodismo de investigación”. En EE.UU. este tipo de periodismo está en todos los medios y no solo en medios de comunicació nde ámbito nacional. En España hay pocas unidades demomento, en relación EE.UU.
El programa excel tiene sus limitaciones, solo permite un millón de entradas.
Una de las grandes ventajas del periodismo de datos es que no debes favor a nadie, a un político que te filtra unos datos, a un partido político que te da un soplo. Los datos pueden llegar de una consulta a la administraciń pública.
La primera persona que empezó a hacer prácticas en eldiario.es estaba dedicada a los datos. Valga como indicativo de por dónde queríamos crecer.
Asumimos que tenemos menos medios que la inteligencia colectiva. Cuando llegan grandes bases de datos las comparimos y empezamos a hacer la investigación con los datos publicados. Hay una desconfianza hacia los medios y el público quiere tener acceso a la información. Así lo hicieron con los datos de la tarjetas black.
A veces lo datos cuentan la historia. Como la única manzana donde ganó el PP en las elecciones municipales: en esa manzana había una residencia de la policia nacional.
El ejemplo de la visualización de datos de las elecciones del 20D. La redaccción trabaja colectiva y simultáneamente en una misma hoja de cálculo.
El periodismo de datos no tiene porque ser visual, en absoluto.
Lo que cobran los periodistas no es lo mismo que cobran los programadores, eso genera tensiones. El Diario es un periódico que no quenta con grandes medios en coparación con otros grandes medios de comunicación, pero que demuestra que con poco se puede hacer muchas cosas.
Tienen previsto incorporar 5 programadores en los próximos meses (oferta disponbile en eldiario.es/redaccion).
Somos un medio local. cuando salen datos solo tenemos que preocuparnos por los datos que afectan a nuestra comunidad. Cuenta con 3 periodistas, un programador y una socióloga (fundamental para gameficacion)
En Navarra salió una ley de transparencia antes que en el resto de España. Más basada en la participación y colaboración ciudadana.
A nivel periodístico nos hemos encontrado con una falta de colaboración de agencias centrales y unos recursos muy limitados en Open Data Navarra. Algunos organismos no han cedido sus datos estadísticos.
La oficina de intervención y asuntos económicos en navarra nos ha servido de mucha ayuda para aclararnos ciertas dudas. Navarra, al tener las competencias de Hacienda, hace más complicado entender algunas historias.
Algunas historias han salido a través de cartas al director. Puede parecer algo anticuado pero ha funcionado esa forma de participación ciudadana.
¿Qué recursos usan? La policía foral les ha ayudado. También funcionarios “amables” y la creación de datos propias de bases de datos. Creen que para medios de ámbito estatal puede ser difícil, pero dado nuetro caracter más local, nos es posible.
Así hicieron las investigación de los desahucios de más de 500 familias en Navarra. Generaron un mapa y luego ofrecieron datos relativos a la cnatidad de población para poder calcular índices. http://www.diariodenavarra.es/pags/desahucios_navarra.html
Hacen para la web algunas visualizaciones. Otros departamentos les ayudna en la gráfica.
Han tratado temas como las elecciones, casos de corrupción, peericos de másteres, gasolinas, accidentes, papeles de Panamá.
Tiene una función, cuando llegan los grandes sumarios de instrucción: 20.000 págians donde los redactores que tienen que xtraer información de ahí. Tabajan con OCR para poder hacer ases de datos buscables también para los redactores.
Medio pionero como diario únicamente digital. Llevan 20 años.
Tiene 18 ediciones locales, hace periodismo muy local.
Entró como directora septiembre del año pasado.
Tambíén piden muchos datos.
La ley catalana es tan exigente en cuanto a la transparencia que nadie lla cumple.
Hace poco hemos sacado una marca sobre los datos como han hecho otras cabeceras como el Confidencial y El Español: http://www.naciodigital.cat/labs
Es imporante mencionar que es importante la interpretación de los datos es también muy importante.
Hace años el debate estaba más centrado en los programas (Tableau, CartoDB) peor l oque vamos viendo es que las visualizaciones tienen que ser más sencillas. En el móvil se hacen complicados ver ciertos gráficos (dará taller). El acceso por móvil es mayor del 60%.
Gráfico de distribución presupuestaria de gasto en Cultura del Ayuntamiento de Madrid. 2009.
Como continuación del proyecto Kulturometer (2009) que desarrollé en Medialab-Prado durante las jornadas de Visualizar’09: Datos públicos, datos en público junto con otros agentes culturales de Madrid (Atravesadas por la cultura), se presenta ahora la investigación gráfica sobre visualización de los presupuestos municipales del Área de Cultura del Ayuntamiento de Madrid en 2016 que he realizado junto con Mar M. Núñez (noez.org).
Una oportunidad para volver a trabajar y pensar sobre datos en abierto y reutilizables y explorar maneas de visualizar presupuestos públicos. Hace 7 años hice el gráfico de tipo sankey prácticamente “a mano” con Freehand. Ahora he podido usar d3 y el plugin para Sankey, lo cual facilita mucho la tarea.
Merece la pena recordar, si nos remontamos a los orígenes del proyecto, que el objetivo inicial no eran ni los datos abiertos, ni la visualización de datos “per sé”, sino el entender cómo fluía el dinero -o no- desde las instituciones a los productores culturales. Seguimos teniendo eso en mente, aunque el resto de cosas que se han añadido al proyecto nos interesen igualente.
En esta primera sesión se compartirá la investigación sobre el análisis de los presupuestos. Se darán las claves para poder analizar presupuestos oficiales y por otra se presentarán diferentes análisis gráficos del gasto dedicado a cultura en el Ayuntamiento de Madrid. Será una sesión abierta para que cualquiera pueda compartir sus dudas y preguntas. Todo el mundo es bienvenido.
Taller (fecha por concretar. Junio 2016)
El proyecto Kulturometer 2.0 comprenderá además la celebración de un taller de dos días en primavera (fechas por concretar) en el que se presentarán otras experiencias de visualización de presupuestos y se trabajará de manera práctica con ejemplos concretos de presupuestos de cultura en torno a las siguientes preguntas: ¿Qué herramientas tenemos y podemos usar para hacer análisis comparativos de presupuestos, tanto para uso interno de las organizaciones como para hacerlos accesibles y comprensibles para la ciudadanía? ¿Qué tipo de procesos de participación podemos poner en marcha para deliberar sobre los presupuestos públicos?
Rescaté estos resúmenes de los libros que había leído este verano de 2015. He tenido que completar alguna parte que había quedado incompleta. Me animó a publicarlos la review of books que ha hecho Charlie DeTar de 2015.
El verano oficial acaba dentro de unos días. Para mi, y muchos otros, terminó el 30 de agosto en Cantabria.
Todavía no llega a ser tradición, pero este es el segundo año que me conjuro para recordar mis lecturas veraniegas. Este año he tenido menos tiempo, pero he sido más disciplinado. Tres libros consecutivos, sin yuxtaposiciones. Todos ellos regalos.
El primero es Por encima de mi cadáver, me lo regaló Isak, un amigo desde los tiempos del instituto y que está escrito por Mario Cuesta, otro compañero del instituto de entonces. Leer las vivencias de alguien que conoces te aporta unos datos que están fuera del libro. Conoces al personaje antes de leerlo. Es como el enésimo capítulo de una serie de la que te has perdido unas cuantas, muchas, temporadas. El relato es sobre un viaje a Líbano y Turquía que se entralaza con los recuerdos y personajes de un viaje anterior a Siria y la historia de la región. Emails de sus primeros tiempos en Damasco se mezclan con lo que le está ocurriendo ahora. La guerra civil de Siria se huele en el aire y las historias de sus amigos hablan de los problemas dentro del país y las dificultades para conseguir salir de allí.
Pero, como bien apunta Mario, esto no se trata de un “viaje iniciático”, porque no existen. Aquel que va a la India y “aprende” que se puede vivir con muy poco, ya lo sabía antes de aterrizar. Sin llegar a ser un ensayo sobre la región, cosa que tampoco pretende, sí que explica las raíces históricas de los conflictos geopolíticos que producen tantos muertos y llenan tantas páginas en los periódicos cada día. Para los que nos perdemos en el complejo conflicto de Oriente Medio es una buena guía para iniciarse. Le acompañamos a regiones donde Hezbolá gobierna (el partido-grupo militar en Líbano), vamos a ciudades con toque de queda en la frontera de Turquía para conocer el conflicto turco-kurdo, o ligamos en un bar de Beirut. Nos muestra el día a día, o al menos, las vidas que se encuentra un viajero ocasional con ganas de conocer y que tiene amigos en la región.
Como buen “demente”, cuando visita Estambul, va al estadio donde el Estudiantes jugó su única Final Four europea. Coincide con el Two Nations Cup que enfrenta en partido amistoso a Panathinaikos y Fenerbahce. Sin embargo, ante la falta de público y de ambiente está a punto de quedarse fuera viendo un partido de fútbol de barrio . Me gusta esa forma de viajar: sabes a dónde se quiere ir, pero estás abierto a modificar tu plan inicial y a abrazar a las nuevas circustancias que el viaje te depare. Es como saber navegar una noche de fiesta que no es lo que esperabas.
El siguiente libro, El Círculo de David Eggers, también me llegó por correo desde Italia. Qué alegría recibir regalos, qué alegría recibir libros, y más aún si apetece leerlos. Por casa anda una novela de Eggers anterior bastante conocida por los USA, Zeitoun, sobre el desastre del Katrina, que no me he decidido todavía a leer. El que tenía entre manos era una traducción, que, no siendo mala, dificulta a veces avanzar por el texto imaginándose cómo estaría escrito en el original en inglés. No suelo ser muy picajoso con estas cosas, pero al tratarse de un libro con tanta jerga tecnológica se nota más.
La novela transcurre en el campus del Círculo, una empresa de Sylicon Valley que en unos pocos años ha pasado a dominar internet. El Círculo no es otra cosa que una manera de hablar de Google, pero sin nombrarlo, así se ahorra los pleitos. El campus es un centro de innovación idílico (cual Googleplex) donde se desarrollan, con éxito, todo tipo proyectos destinados a cambiar el mundo. Las mentes más brillantes del mundo están allí. Los empleados disponen de todo tipo de servicios: comida, gimnasio, habitaciones…
Devoré el libro, no tanto porque me atrapara, sino porque quería acabarlo. Es válido como fábula para reflexionar dónde puede acabar la hegemonía que ejercen algunas compañías en Internet (Google, Facebook) y plantear preguntas. Sinembargo, simplifica en exceso. El personaje principal, una chica que empieza a trabajar en el Círculo, es una caricatura del nuevo creyente tecnológico. Presenta un poco de resistencia al principio, pero luego parece que le hayan lavado el cerebro y dice sí a todo. Tras haber leído Por encima de mi cadáver, donde se retrataban personajes más complejos (también reales) en unas cuantas frases, los personajes de Egger parecen demasiado unidireccionales y, por lo tanto, poco creíbles. Valen para ser la cigarra holgazana, la hormiga trabajadora o el ogro malvado del cuento, pero no para hacer verosímil, o al menos creíble, el relato.
Siempre me han interesado las novelas o películas distópicas. Las hay que empiezan con la distopía ya organizada, como Un mundo feliz, Fahrenheit 451 o 1984, y las que cuentan cómo se llega a esa situación, como Las partículas elementales. En El Círculo la historia es lineal: de una situación de casi dominio la empresa acaba siendo el nuevo “Gran Hermano” en pro de la transparencia. Todo ello ocurre en connivencia, y apoyo, de los gobiernos de todo el mundo y sin una resistencia organizada. Hay una pequeña historia de disidencia solitaria. El exnovio de la protagonista que no quiere participar de todo ese mundo digital, de hipertransparencia donde se retransmite la vida entera en público, escapa y se va a vivir al bosque. Podría ser el inicio de una resistencia organizada, el bombero que quema libros que abandona su oficio, pero la caricaturización del personaje impide que eso ocurra (“me fui a los bosques, porque quería vivir a conciencia”). No hay espacio para que piense o intente organizar la resistencia. Intenta revertir la situación (¿enviando cartas a su exnovia?) y luego desaparece (“sálvate a ti mismo”).
En cualquier caso, es una lectura interesante para un verano en el que las cotas de uso de Whatsapp han llegando, espero, a su culmen. Queremos compartirlo que nos pasa con los que están lejos. Retratar esos momentos irrepetibles de las sobrinas. Lo que pasa es que al final la mitad de los presentes está dedicada a documentar el evento, más que a vivirlo. Esta reflexión no es nueva, mucho se ha dicho. Lo curioso es que por más que se han facilitado las herramientas para compartir la información (entre los presentes) seguimos necesitando cada uno hacer una foto con nuestra propia cámara.
Por último he leído El Cura y los Mandarines de Gregorio Morán, que saqué de la biblioteca pero que he regalado a mi hermano, para cumplir con ese triplete de regalos que prometía líneas más arriba. Regala lo que te gusta recibir. Uno de esos libros densos, largos y con tantos nombres que es imposible retenerlos todos. Una historia de la cultura y la política en España en las últimas fases del franquismo y las primeras de la democracia. Su título triple completo es El cura y los mandarines. Historia no oficial del bosque de los letrados. Cultura y política en España 1962-1996. Para el lector que no ha vivido, ni apenas estudiado esos años, es todo un descubrimiento. Para quien no haya leído a Morán todo un descubrimiento que te lleva a conocer a otros escritores y libros. Una escritura mordaz que no se muerde la lengua.
El libro usa personaje de referencia al cura Jesús Aguirre, que luego fue duque de Alba. El recorrido de un cura homosexual del Santander de posguerra y su escalada hasta lo más alto, cuando se convierte en duque al casarse con la duquesa de Alba y le hacen director de unas cuantas instituciones culturales, sirve de hilo conductor para narrar cómo era ese vacío cultural que dejó la guerra y el exilio en España. Ya solo el prólogo o prefacio, no recuerdo bien, es muy interesante y se cuentan las vicisitudes del proceso de escritura del libro y como tras muchos años preparándolo y casi ya en imprenta quiso ser censurado por la editorial Planeta. No accedió a que le recortaran un capítulo sobre la Real Academia Española, en concreto 11 páginas dedicadas a Víctor García de la Concha y terminó siendo publicado por Akal.
De memoria y sin el libro a mano siguen en mi cabeza muchos de los personajes o eventos relatados. Enuncio en una lista sin orden algunas de esas personas y sucesos:
el contubernio de Munich del ’62, cómo había vivido tanto tiempo sin saber de él, 1969 como el año del estado o el proceso de Burgos de 1970. Cuánta ignorancia.
la importancia cultural del Santander de posguerra y los personajes que allí empezaron y luego fueron élite, como Jesús Polanco, que con su editorial Santillana pegó el pelotazo con los libros de texto en los años ’70;
la relevancia política Luís Martín Santos (el de Tiempo de Silencio) con su militancia en el PSOE y lo poco que se menciona eso en los libros de literatura; el continuismo entre las élites culturales entre el franquismo, la transición y la democracia;
se presenta a Camilo José Cela como colaborador y censor del régimen que llegó a ofrecerse durante la guerra civil como espía de los rebeldes franquistas. Más interesante todavía es la red de contactos que tejió con la revista Papeles de Son Armadans, donde colaboraban muchos escritores en el exilio. Cela era para ellos el único canal de contacto con la España que habían abandonado, y su revista, un reducto de libertad en una España desolada. Lo que nos cuenta Morán es que la revista no era casi leída dentro de nuestras fronteras, como creían lo colaboradores exiliados, y sí en los departamentos de literatura española en múltiples universidades. Esto sirvió para colocar el nombre de Cela y que fuera invitado a universidades extranjeras y le ayudara a posicionarse internacionalmente para el premio Nobel ¿cómo podría tejerse esa red en la actualidad teniendo a todos contentos y que nadie se sienta utilizado? Todo esto no menoscaba la calidad literaria del escritor de La familia de Pascual Duarte o La colmena, pero sí ayuda a situar su obra y al personaje en su contexto histórico político.
un capítulo apasionante es el dedicado a los comienzos del periódico El País. No es, como piensa mucha gente, una creación de la mano de los socialistas. Por allí estaba Manuel Fraga Iribarne en sus inicios… mejor que lo leais vosotros. Traigo a Fraga a colación también porque me recordó su puesto como embajador en Londres al retiro dorado (también para quitarle de en medio) del que disfruta Federico Trillo anteriormente.
Como crítica negativa a veces el libro puede resultar espeso, se atranca con muchos nombres, repite algunas explicaciones de un capítulo a otro, como si no hubiera sido debidamente editado. Quiero pensar que es deliberado y que está pensado para poder ser leído por capítulos separados o para ayudar al lector con mala memoria. Es uno de esos libros con asterisco, como cuenta Charlie DeTar en su repaso a los libros que ha leído y podcast que ha escuchado en 2015: books with a “*” are those that, relative to the others, had a very deep impact on me, transforming my world view. They might not be as special to you, but they were to me. La lectura de su revisión de libros anual me animó a publicar por fin este artículo.
El libro de Morán me animó a seguir con otro libro suyo Los españoles que dejaron de serlo (Euskadi, 1937-1981), donde relata la historia del País Vasco centrada en tres protagonistas principales: ETA, la oligarquía vasca y el Partido Nacionalista Vasco. Escrito a principios de los años ochenta nos cuenta los primeros años de ETA, la formación de la oligarquía vasca y el papel del PNV. De paso descubrí que también había pasado unos años en Bilbao. Pero esa es ya otra historia.
La medida de la importancia que un libro tiene para mi es cuántas veces lo cito y vuelvo sobre sus temas. En los últimos meses me ha surgido comentar El cura y los… en muy diversos contextos y charlas y no paro de recomendarlo.
No terminé otro libro que me regalaron: A mis amigos del Comité Invisible. A ver si lo acabo y os cuento.
Este es un experimento para medir la masa de papel de spam o correo no deseado que ha llegado a mi buzón durante el año 2015.
Durante el 2015 recibí 5,31 kg de publicidad en mi buzón.
Si en Bilbao hay 160.283 viviendas (según eustat), podemos extrapolar y calcular que serían 851 toneladas de papel/año solo en Bilbao.
Considerando que no todos los barrios y viviendas reciben la misma cantidad de propaganda, podemos minorar este resultado. Pensemos que 100.000 viviendas han acumulado la misma cantidad que mi buzón: serían 531 toneladas de papel al año. Casi 1,5 toneladas de papel por día.
En 2015 recibí 5,3kg de publicidad en papel en mi buzón. En Bilbao hay 160.283 viviendas, esto hacen 851 toneladas de papel/año #BuzónSpam
He recogido los datos porque no había otra forma de evaluar la cantidad de spam de otra manera ¿Te animas a pesar la publicidad en tu buzón durante este año para hacer un estudio comparativo?
Así ponemos un grano de arena en forma de datos para acabar con el correo indeseado.
Nota: He incluido los 412 gramos de las páginas amarillas y los 362 gramos de un catálogo de juguetes.
Durante el caso Zapata hice un inicio de experimento de captura de datos de los telediarios de TVE que no llegó muy lejos. El tuit de @MatthewBennett de más arriba me recordó la necesidad de tener los datos accesibles. Ahora algunos de los telediarios de TVE están minutados, incluso algunos disponen de la transcripción completa, valía la pena probar el experimento de nuevo. Una duda ¿por qué no todos los telediarios disponen de la misma información: transcripción + minutaje? Misterio.
En un rato libre me puse manos a la obra para corroborar los datos de Matthew. Mi estudio es sobre los datos del telediario de medio día, los suyos, creo que del de las 21h:
He montado unos sencillos gráicos de barras para mostrar el tiempo dedicado a las noticias. El fútbol gana (7:49 min), aunque también es cierto que no he sumado en el gráfico el tiempo dedicado a los pactos para formar gobierno, que anda cerca de los 9 minutos (8:41). El caso de los titiriteros se lleva 5:40, la bolsa 2:42 y los casos de corrupción Taula 1:23 y Nóos 1:02.
La duración no solo es lo importante, por eso he incluido un gráfico para ver en qué orden se emitieron las noticias. Abrieron sobre el caso de los titiriteros. Más tarde fue el tema que siguió la crónica política de los pactos.
Habría que analizar también qué y cómo se contó la noticia, se lo dejo a otros. Aquí un avance:
@paaq 2 veces 4 segundos del vídeo. Han usado imágenes de archivo y lo mejor: renders del auto de ingreso en prisión pic.twitter.com/QhSCmNB6tm
La idea primigenia surgió a seis manos, una noche en una cena en la calle Iturribide. Hacía poco iempo que me habían concedido una beca de producción dela Fundación Bilbao Arte.
Lo que podía haberse quedado en una idea de bar sobre una servilleta fue refinándose y rehaciéndose en una cadena de emails hasta plasmarse con una serigrafría tricolor sobre una camiseta.
¿Qué significa ser artista vasco? ¿Qué significa se oteiciano o postoteiziano en el siglo 21? ¿para qué sirven el arte? ¿y la broma?
–
Como solamente imprimí 12 camisetas me he ido encontrando con gente a la que le gustaría tener una y no puede obtenerla (ni comprármela). Por eso, como les he ido diciendo a todos, comparto aquí el archivo vectorial para imprimir (.pdf) para que cualquiera pueda imprimírsela y modificarla como quiera.
En este post iré recogiendo diferentes fotos y reacciones a este ARTISTABASCO. Ponte en contacto conmigo si la re-utilizas o deja un comentario en este post. Si te animas a hacer de nuevo una impresión a serigrafía en tres colores ¡avísame! hay otra gente que querrá una.
Gracias a todos los que colaborasteis en el desarrollo de la camiseta.
Boceto previo de cómo quedaría.
Boceto previo de cómo quedaría.
En tamaño más pequeño que las camisetas originales, aquí nos llega el primer clon.
Recopilo en este post los diferentes análisis que voy realizando sobre la cobertura en portada de prensa de los principales periódicos generalistas en España (El País, El Mundo, ABC, La Razón y La Vanguardia) durante el periodo electoral de las elecciones generales del 20 de diciembre de 2015.
Hoy comienza en la universidad de bellas artes de la UPV en Leioa, cerca de Bilbao, una serie de charla-mesa redonda-taller sobre cómo trabajar en colectivo que organiza el colectivo Dooroom. Yo llevo todas las camisetas/grupos a los que pertenezco: Basurama, Montera34, Wikitoki, PublicLab o Cadáveres Inmobiliarios. Los hay que son colectivos, otros asociaciones de asociaciones o redes de investigación asociadas a organización sin ánimo de lucro. Cada una con sus maneras diferentes de trabajar. También estarán en las jornadas Jon de Todo por la Praxis y Leónidas de Enmedio.
Espero que abra un espacio para hablar de lo que significa trabajar en colectivo: con todas sus alegrías y problemas.
POWER RANGERS
Trabajo en colectivo y transformación social
Martes 24/11/2015
16h-20h. Antiguo plató de audiovisuales. Facultad de BBAA de la UPV. Leioa. Presentación
Presentación a cargo de Dooroom y Fundación Rodríguez.
Después, Jon Garbizu (Todo por la Praxis) , Pablo Rey Mazón (Basurama, Montera34, Publicalb, Cadaveres Inmobiliarios, Wikitoki.org) y Leonidas Martín (Colectivo Enmedio) presentarán su trabajo.
Miércoles 25/11/2015
10h-14h // Antiguo plató de audiovisuales. Facultad de BBAA de la UPV. Leioa. Desayuno y mesa reonda Formación de grupos de trabajo para los talleres.
Los asistentes formarán, junto con los invitados, tres grupos de trabajo para trabajar durante la tarde y el día siguiente.
16h-20h // Okela Sormen Lantegia, Espacio Puerta, Histeria. Bilbao Talleres Cada grupo trabajará en uno de los tres espacios de Bilbao (Puerta, Okela, Histeria)
Jueves 26/11/2015
10h-18h // 10h-18h // Okela Sormen Lantegia, Espacio Puerta, Histeria. Bilbao Talleres (Okela, Puerta, Histeria) en BIlbao
19-21h // en Wikitoki. Bilbao. Presentación y fin de las jornadas.
Merienda y puesta en común de lo sucedido en los talleres.
Si has llegado hasta aquí puedes ver el descacharrante vídeo que ha preparado Dooroom remezclando a los Power Rangers, que a su vez es un remezcla de las Super Sentai Series ¡viva la remezcla!
Se muestran aquí las primeras pruebas que hemos desarrollado desde Montera34 de cara al festival Arquinset 2015 que tendrá lugar en noviembre 2011 con los datos existentes en Cadáveres Inmobiliarios. Esto engloba las bases de datos previas que han aportado diferentes colaboradores y la base de datos de cadáveres inmobiliarios. Los mapas están desarrollados con cartoDB.
Cadáveres (inmobiliarios) adoptados vs Cadáveres desenterrados
Mirad los puntos negros, que son los cadáveres detectados (“desenterrados”) y los amarillos, que son los cadáveres que han sido adoptados. ¡Aún nos quedan muchos muchos puntos por adoptar!
El proceso de adoptar consiste en ampliar la información de cada uno de los puntos y estructurarla según la base de datos de Cadáveres Inmobiliarios. Continue reading →
Este jueves 8 de octubre 2015 a las 19.30h se presenta en Okela (Bilbao) una exposición sobre el tema “Tecnología” en la que han seleccionado mi mapa de paseos por Bilbao.
Para la ocasión he traducido a papel todos esos vectores a partir de las trazas de GPS. He impreso con un pilot y ayudado por una impresora de control numérico los mapas de los cursos 2013-2014 y 2014-2015. Estará abierta hasta el 22 de octubre. Mirad en la web de Okela cuándo abren.
Con motivo de la inauguración habrá performances y charlas a cargo de los otros participantes: Patxi Araujo y Pau Figueres. En mi turno aprovecharé para compartir en un formato charla algunas cuestiones sobre tecnología a raiz de los mapas que expongo. Tunipanea actuará con sus instrumentos a modo de cierre.
Este es el texto sobre el proyecto en el libreto que acompaña a la exposición:
Bilbao caminado
Me interesa hablar de la tecnología (o mejor, de tecnologías) como el conjunto de herramientas para trabajar de un modo “ampliado” sobre la realidad. Esto puede significar casi cualquier cosa: un pincel, un lápiz, un papel, un ordenador, pero me gustaría asociar el relato a las tecnologías que todavía no han sido enteramente asimiladas por la sociedad o no son, todavía, del todo conocidas en profundidad. Entiendo que es una línea difícil de trazar, sobre eso también habrá que hablar.
Bilbao caminado es el resultado de pasear por Bilbao con el GPS encendido con el objetivo de pasar por todas sus calles. Un proyecto que está a mitad de camino entre lo nada tecnológico (caminar) y su documentación a través de tecnologías contemporáneas: Global Positioning System (GPS) y una impresora de control numérico con un pilot como cabezal. Cada año produzco un mapa de todos los lugares donde he estado en Bilbao. Para ser más exactos: todos los lugares donde he ido con el GPS encendido y tenían cobertura para satélites.
El mapa generado, sin base cartográfica detrás, es el resultado de todos los caminos recorridos. Cuanto más líneas hay quiere decir que más veces he pasado por allí. Tardé un año en pasearlo y una hora y pico en que el pilot recorriera esos caminos sobre el papel. La pieza que se expone es el resultado de traducir a un objeto físico todos estos paseos. Un mapa por cada año. Es el último paso de una cadena de transformaciones tecnológicas entre caminar, documentar y producir.
El mapa representa los datos que he acumulado yo mismo, pero también otra pregunta ¿cuántos datos más tiene sobre mi compañía de teléfonos?
Mapa realizado durante el taller Cartografía aérea de Barrio (2015) junto con el Casal dels Infants.
El sábado 25 de abril 2015 spresento los resultados de “Cartografía de Barrio”, unos talleres de fotografías aérea con globo que realiamos a mediados de mes en El Raval, Barcelona.
La presentación tendrá lugar a las 19.00h en el MACBA (Museu d’Art Contemporani de Barcelona) dentro del marco del Festival de Ciència, Tecnologia i Innovació de Barcelona, NOVUM. Se podrá ver los mapas realizados y hablar de las motivaciones y preocupaciones de los participantes sobre el espacio público.
La semana pasada, de entre la basura de Bilbao Arte, encontré esta oración:
Oteiza Nuestro
Tito Jorge,
que estás en el cielo.
santificadas sean tus maclas;
llegue a nosotros tu conocimiento;
hágase tu arte
en la escuela como en el museo.
Danos hoy nuestra caja vacía;
perdona a Chillida,
como también nosotros perdonamos
a quienes admiran a Koons;
no nos dejes caer en la ornamentación.
y líbranos de Hirst.
Quosque tandem?
Un buen aviso para navegantes cuando está todo el año por delante en Bilbao Arte.
La Indagación es el modelo más lúcido del que Peter Weiss denominó como Teatro-Documento. Peter Weiss es tajante en sus Notas sobre el Teatro-Documento. Nos dirá por ejemplo en la nota 5: “El Escenario del Teatro-Documento no muestra ya la realidad momentánea, sino la copia de un fragmento de realidad, arrancado de la continuidad viva”. O en la nota 8, subraya:
El Teatro-Documento no se sitúa en el centro del acontecer, sino que adopta la posición del que observa y analiza. Con su técnica de montaje, hace resaltar detalles claros entre el caótico material de la realidad exterior. Mediante la confrontación de detalles contradictorios, llama la atención sobre un confilcto existente.
Ignacio Amestoy. Extracto del texto “Literatura e historia”. El testimonio del teatro.
La ficción de la verdad. Literatura e historia. Revista Anthropos número 240. Editor Jorge Urrutia. Cuadernos de cultura crítica y conocimiento.
A través del texto conocí la obra Die Ermittlung (La investigación) de Peter Weiss, basada en los juicios sobre Auschwitz y puesta en escena poco después de su conclusión en 1965. En ella se usa la palabra de testigos en el juicio (no sé hasta qué punto saca de lo que se dijo en él) para mostrar las contradicciones de los acusados.
Me vino a la cabeza la validez e importancia de la obra Ruz-Bárcenas, de la que aún tengo pendiente escribir una crítica. Se usa directamente el texto -editado- del interrogatorio del juez Ruz a Luís Bárcenas sobre la supuesta contabilidad b del Partido Popular. Digo supuesta, aunque cada vez menos supuesta y más verificada, contabilidad b del Partido Popular, de la que está a punto de cumplirse dos años desde que conocimos los “papeles de Bárcenas”. Es un buen ejemplo de cómo mostrar al público la complejidad de las tramas de corrupción y los textos o interrogatorios judiciales.
Y justo en los últimos días me he encontrado, o reencontrado, con otros textos literarios, no ya teatrales, que se adhieren a la realidad como A sangre fría de Capote o El adversario de Carrere, gracias a una crítica sobre la última novela de Javier Cercas: El Impostor. El libro, según parece, narra la vida, entre la verdad y la mentira, de Enrique Marco. Lo más conocido es que se hizo pasar por prisionero del campo de exterminio de Mauthausen y llegó a presidir Amical de Mauthausen, la principal asociación de españoles deportados a los campos nazis. Su periplo como impostor no se detiene ahí, también inventó un pasado como resistente antifascista que le llevó a presidir en 1977 el sindicato anarquista CNT. La realidad era otra: “porque Marco sí había estado en Alemania durante la guerra, pero como trabajador voluntario prestado por Franco al III Reich para devolver las deudas de la Guerra Civil”.
La realidad, aparte de ser perfecta, como enunciaba Joseph Hunter, es una fuente inagotable para la creación y la transformación. Escuchemos, veamos. Creemos.
La Fototeca digital del Instituto Geográfico Nacional no funciona muy bien, pero permite acceder a las imágenes aéreas de los vuelos “americanos” de 1945-46 y 1956-57. No he podido resistirme a hacer un gif animado sobre mi barrio madrileño de La Prospe.
El barrio madrileño de Prosperidad en fotos aéreas 1946-2014. Fuentes: http://fototeca.cnig.es/ y googlemaps.








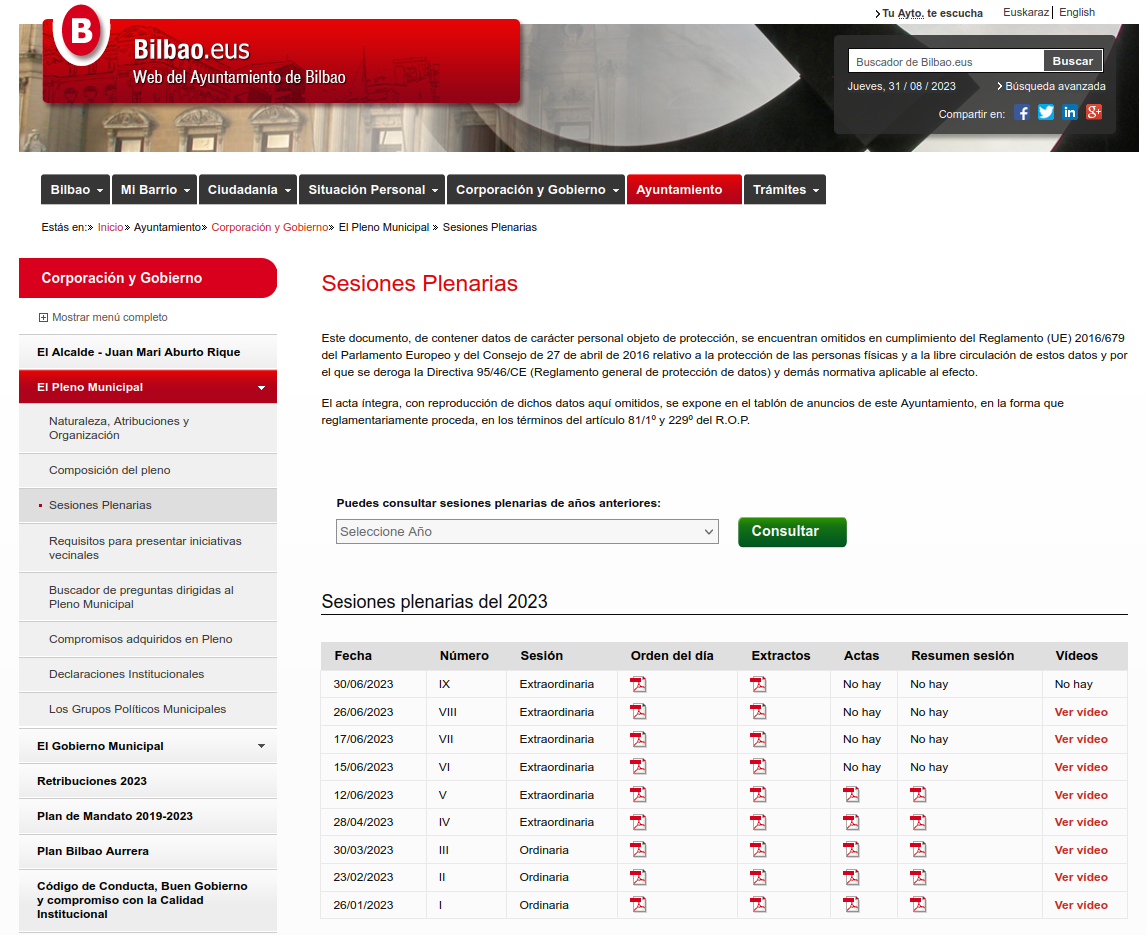
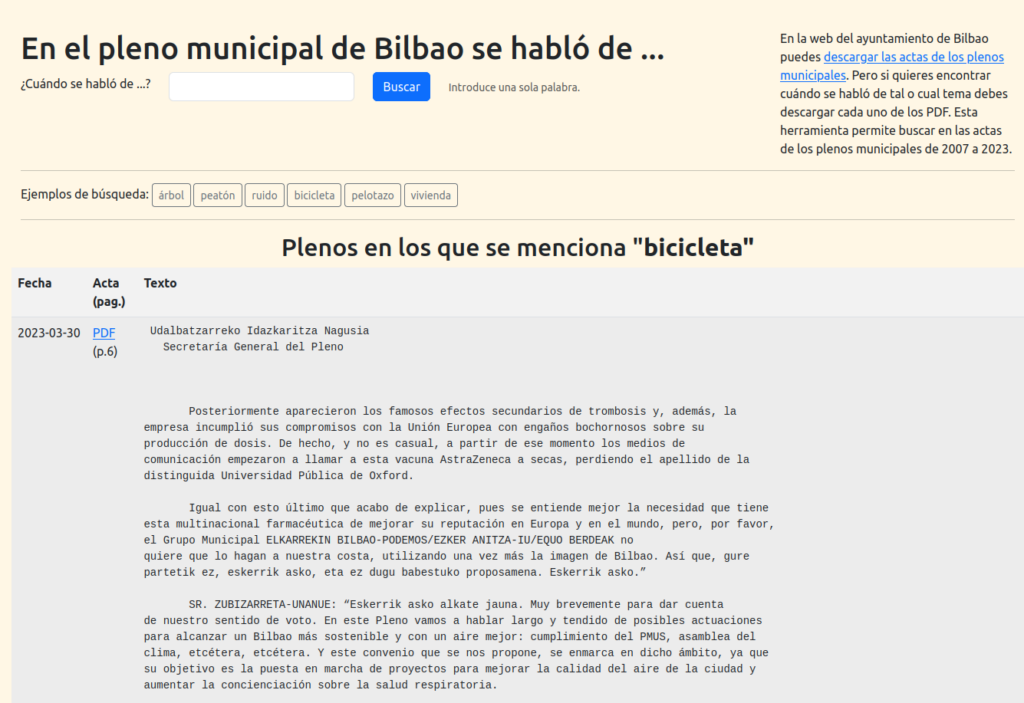







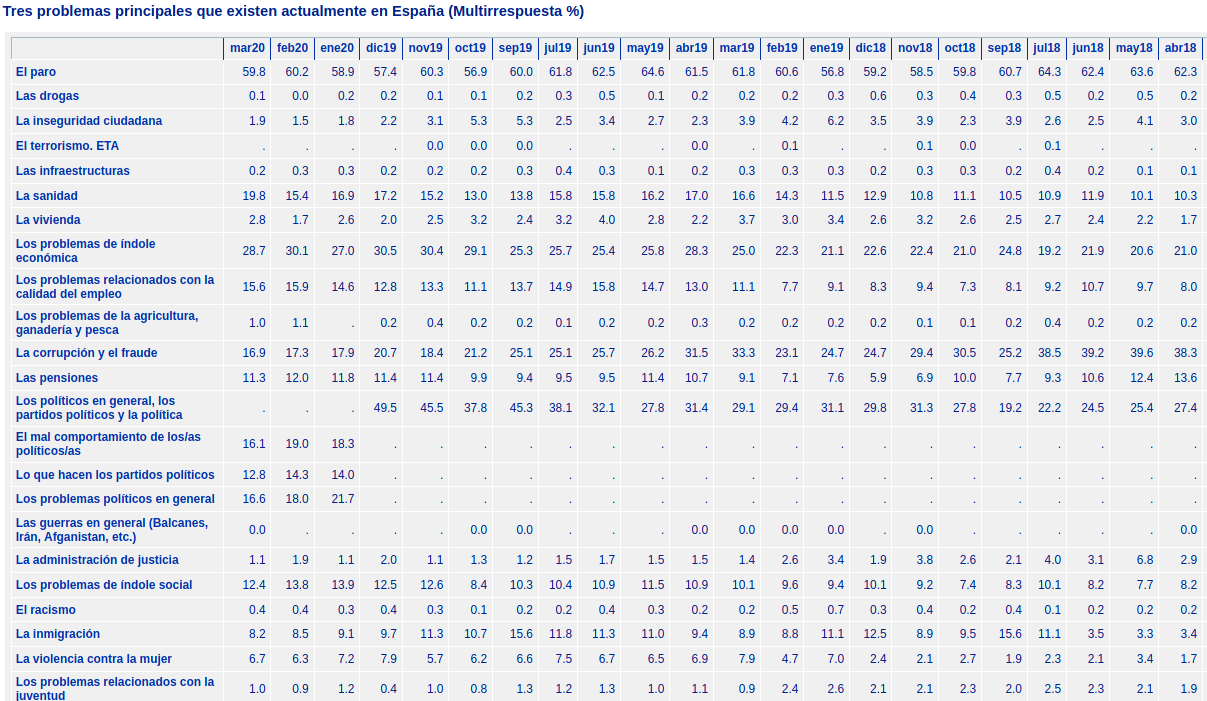



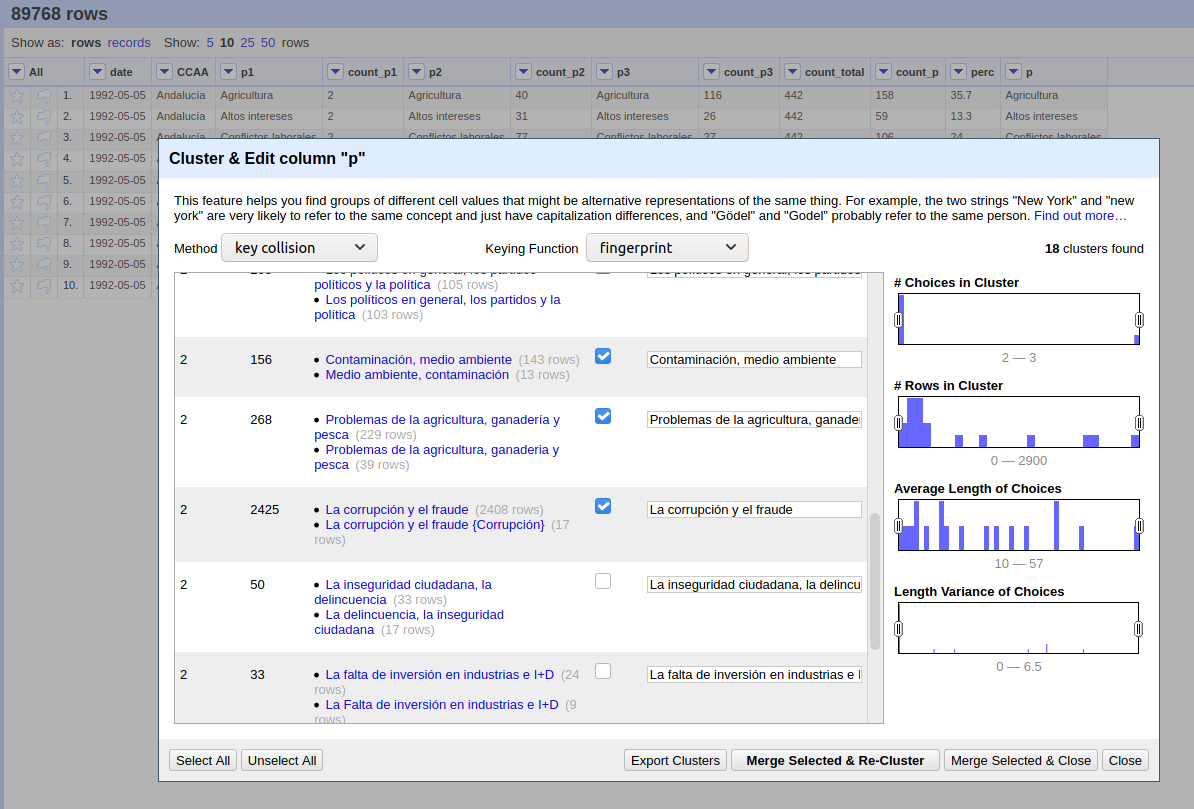

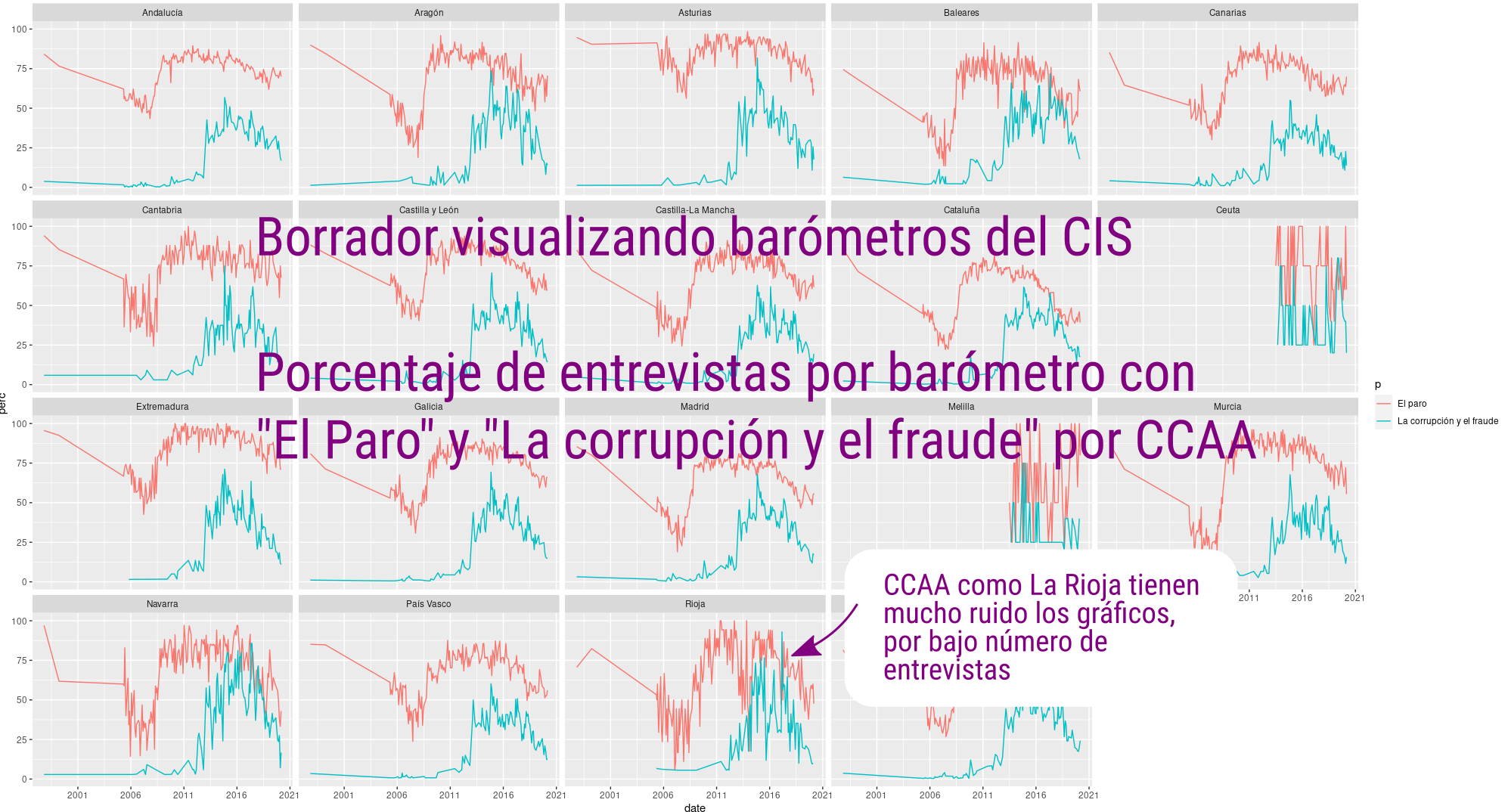

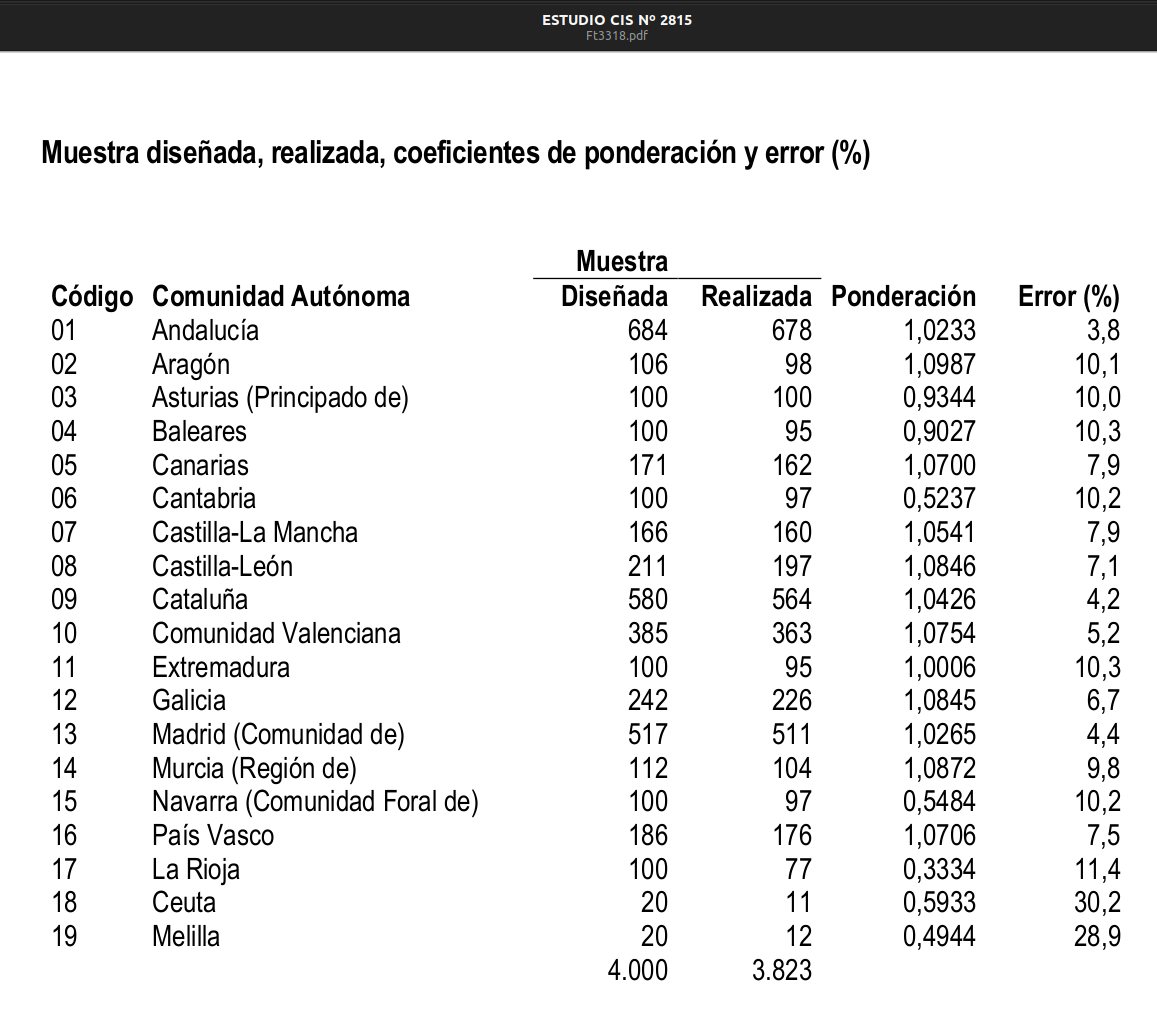

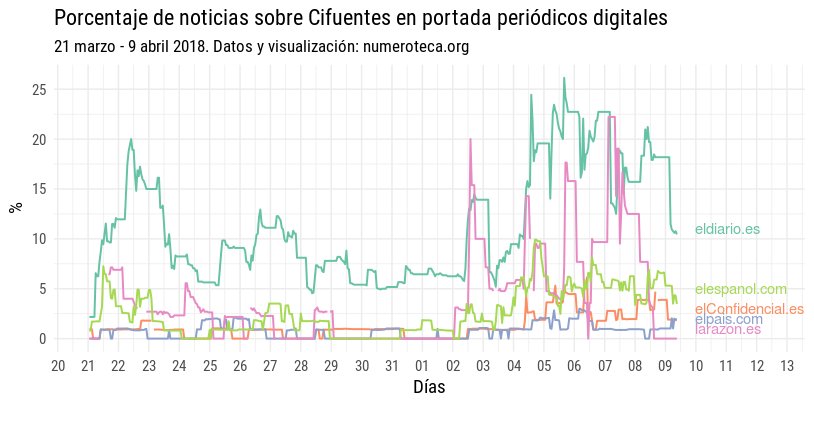

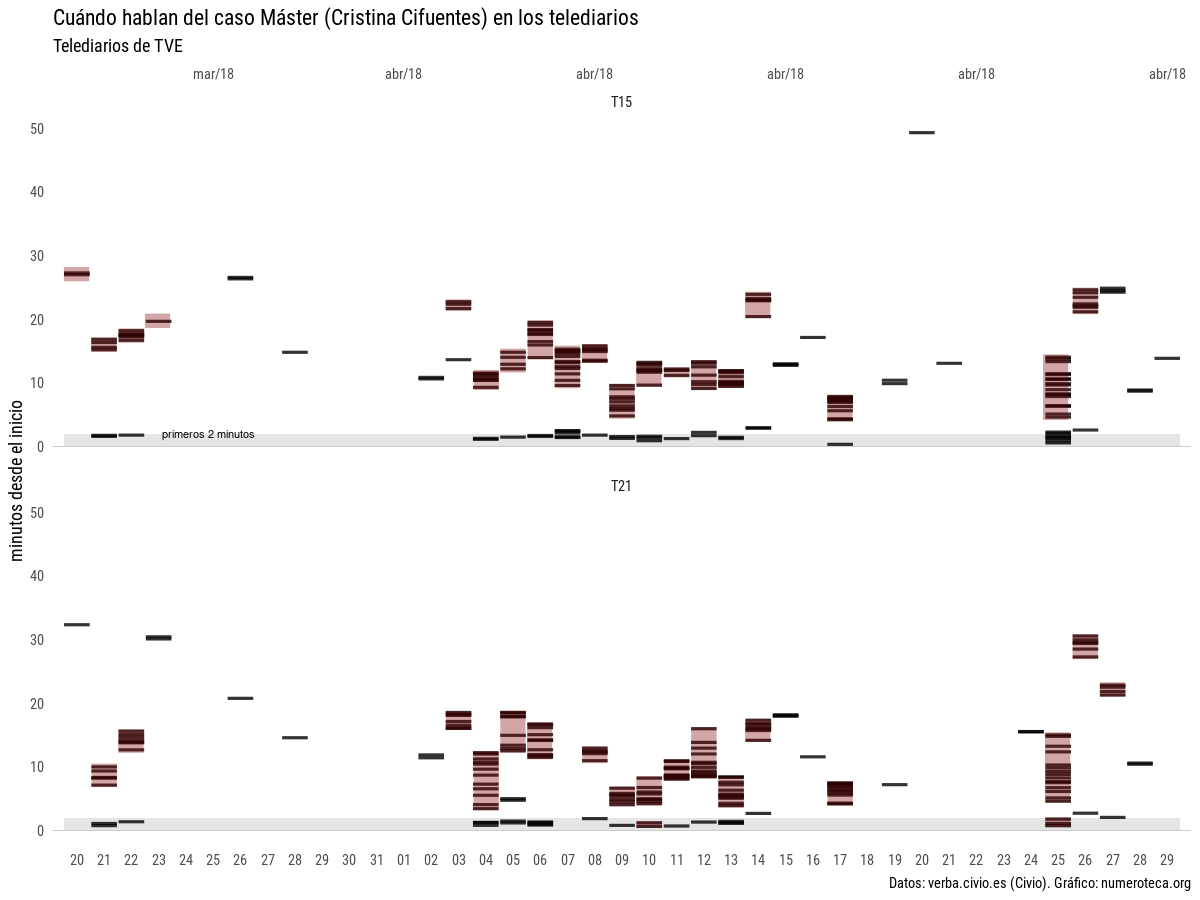


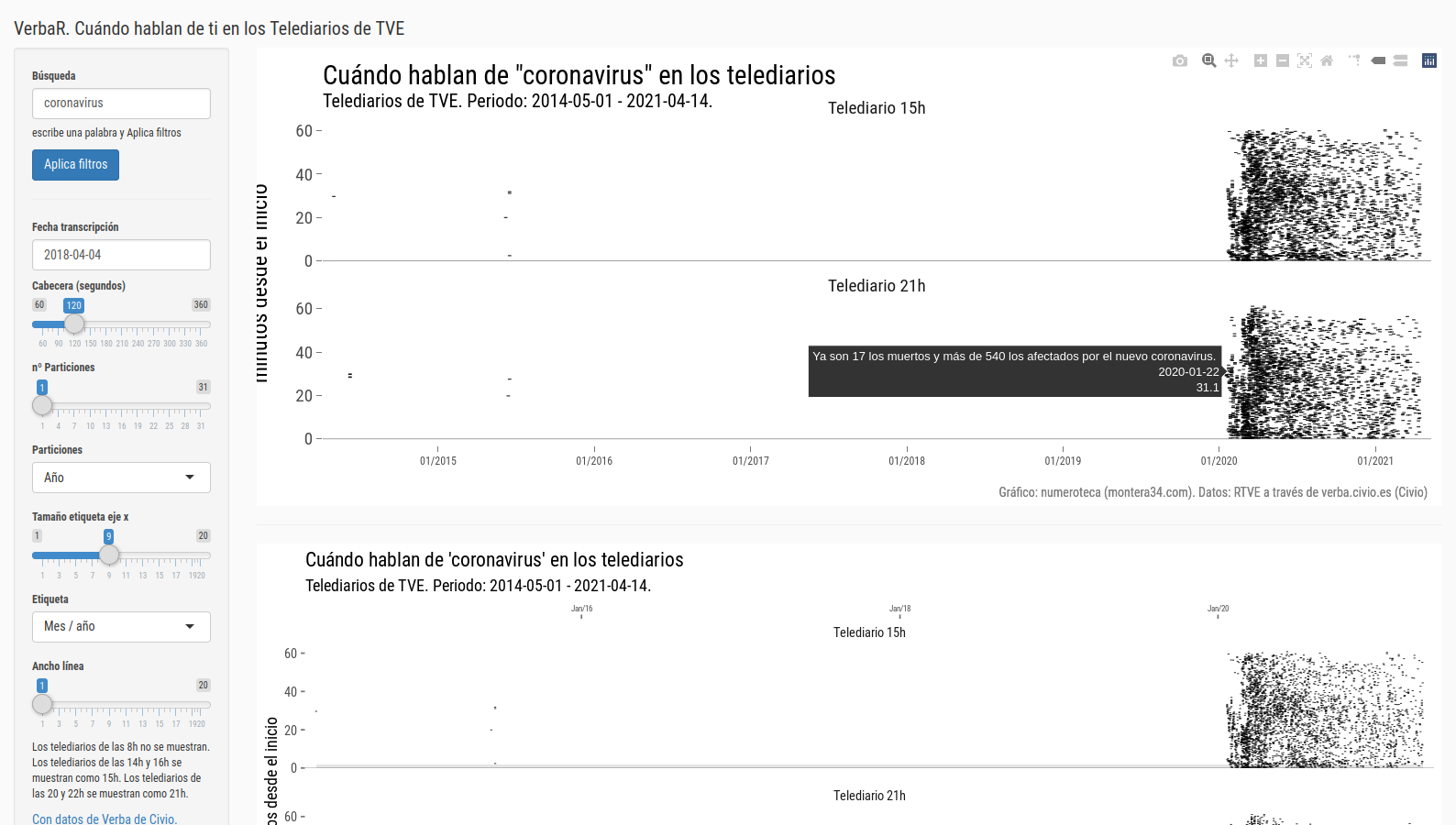

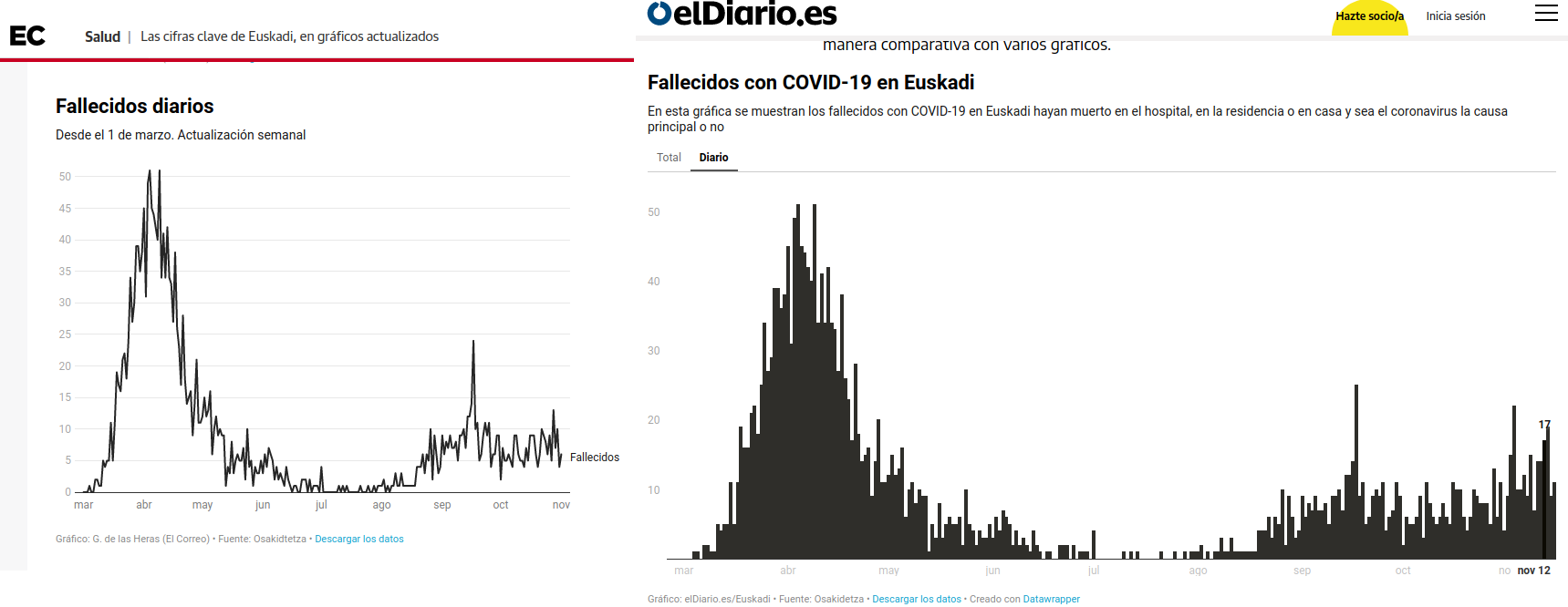
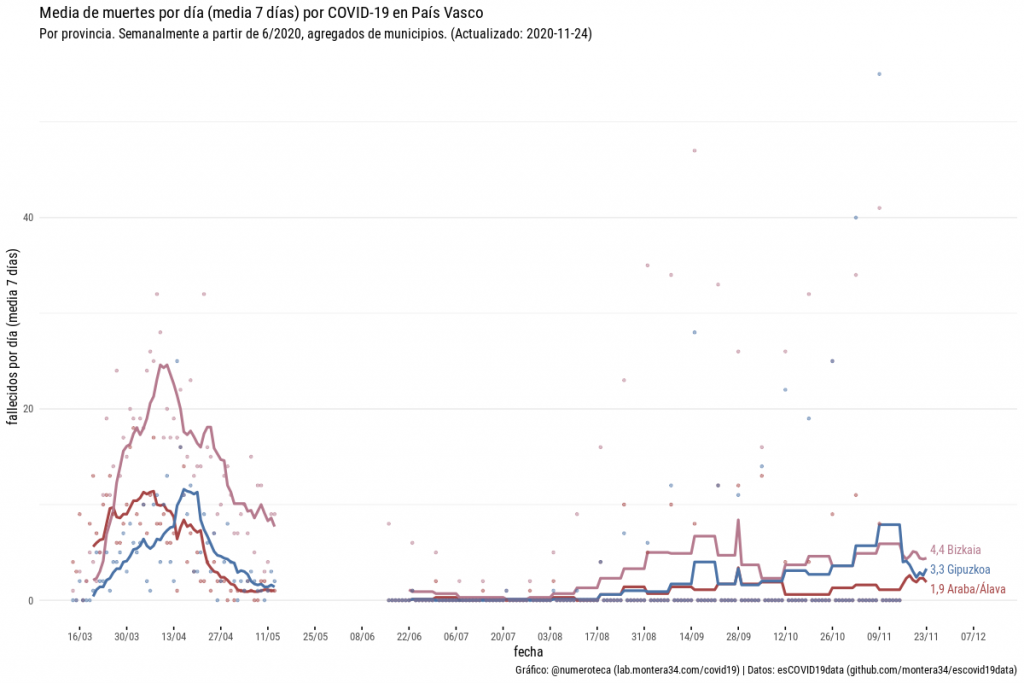
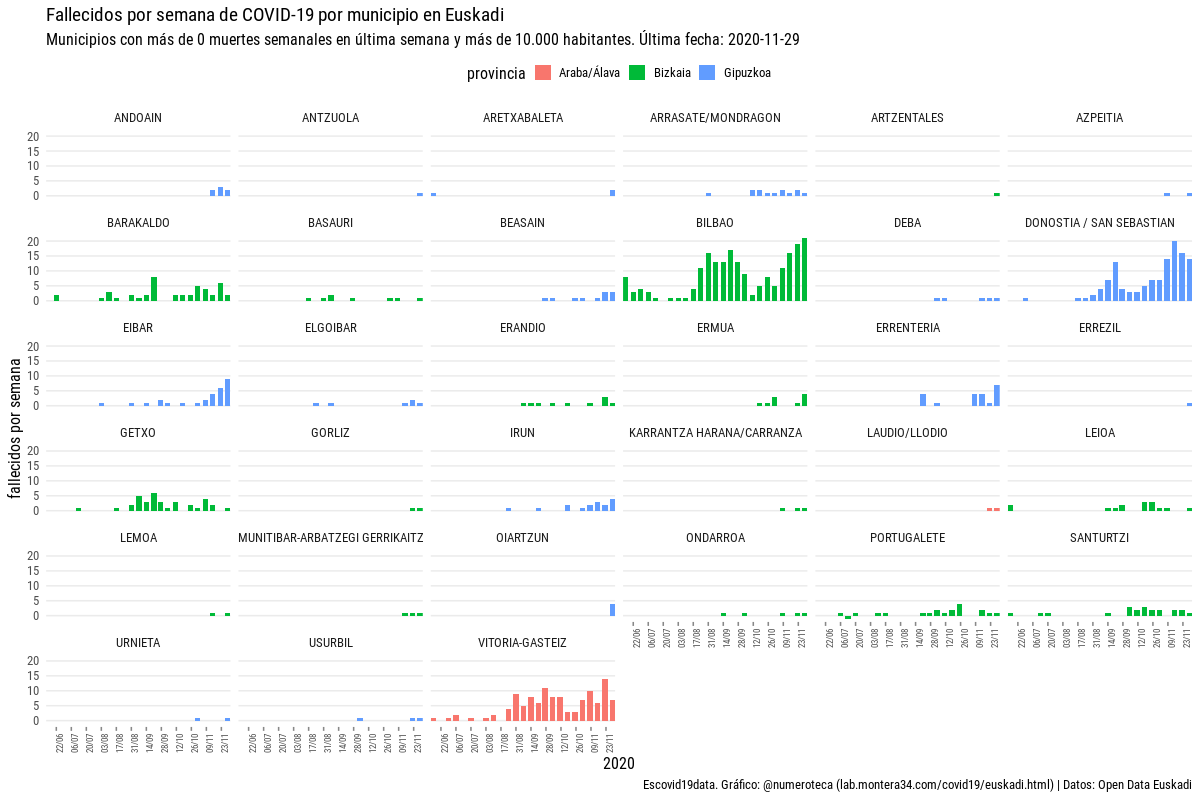

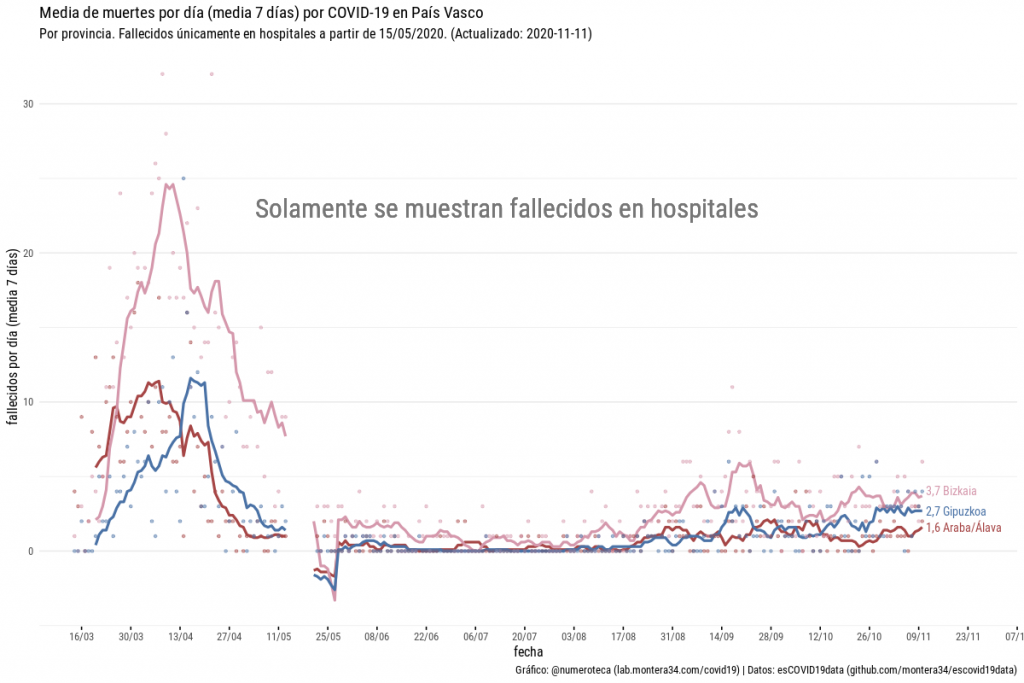

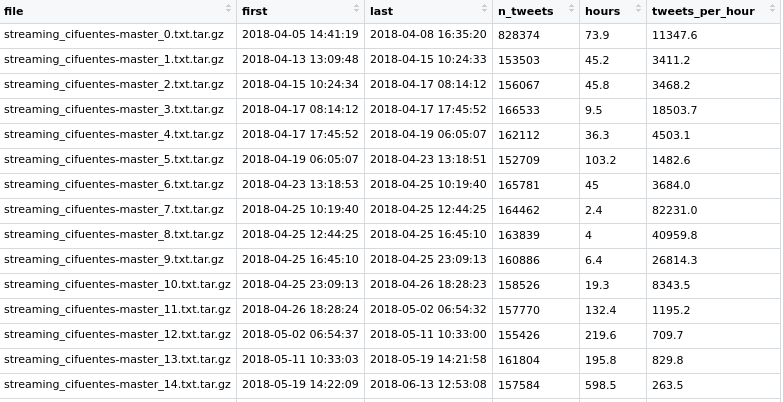
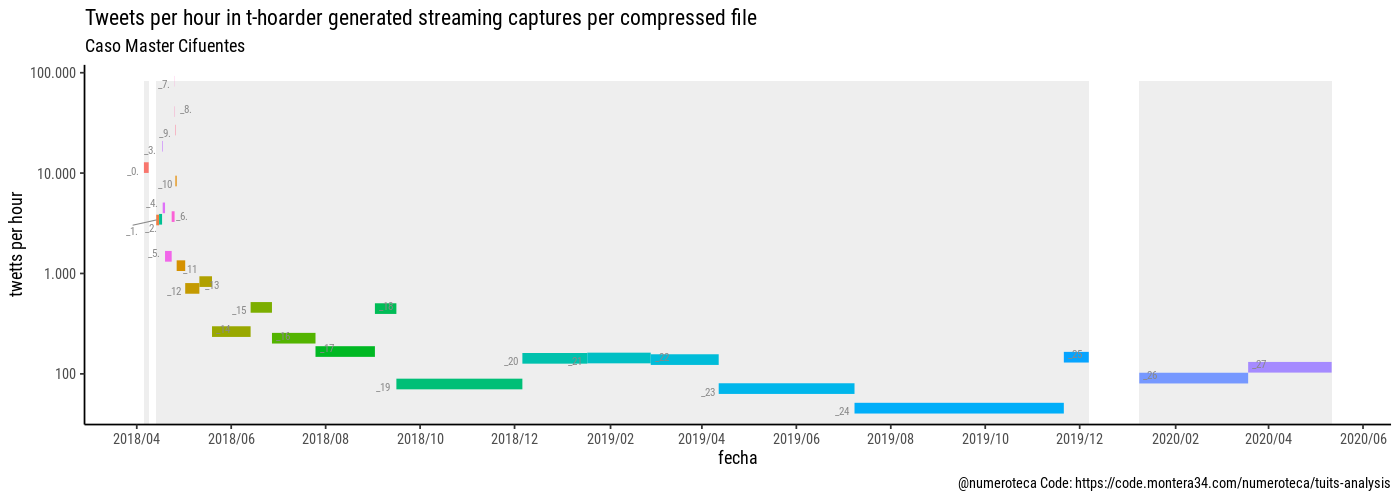
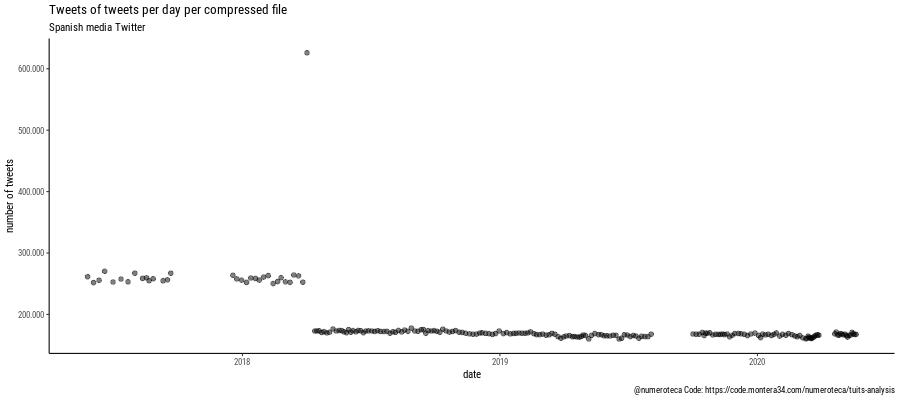


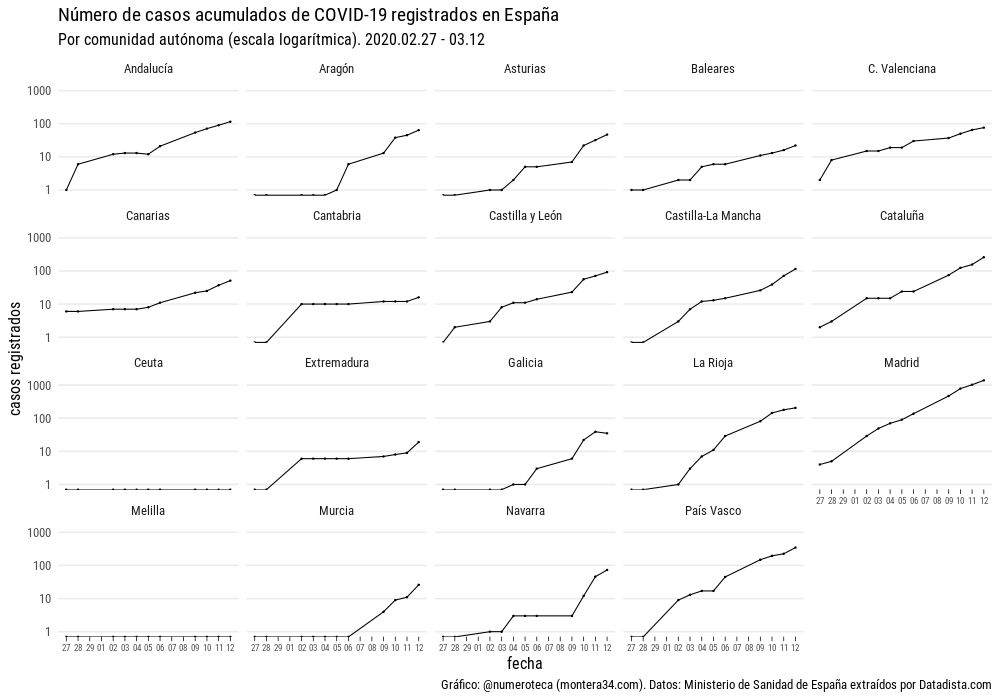
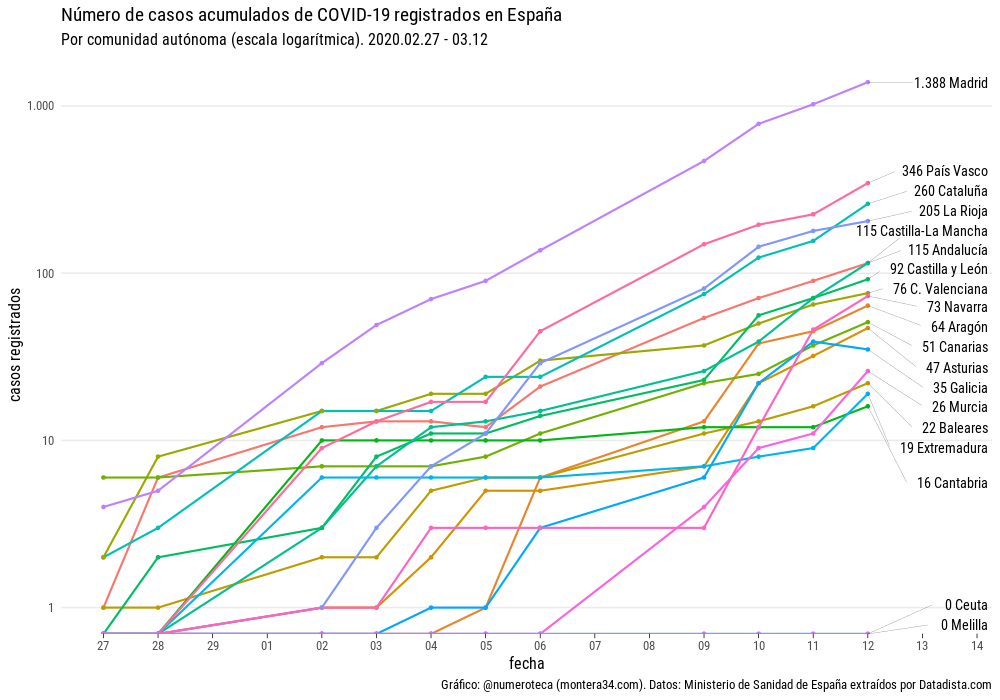
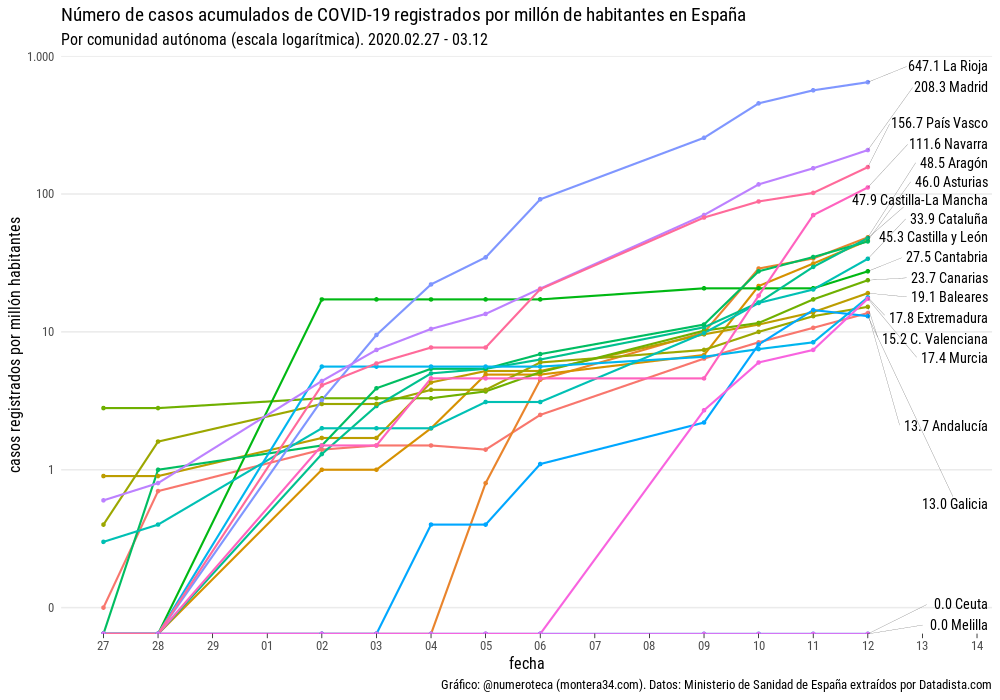
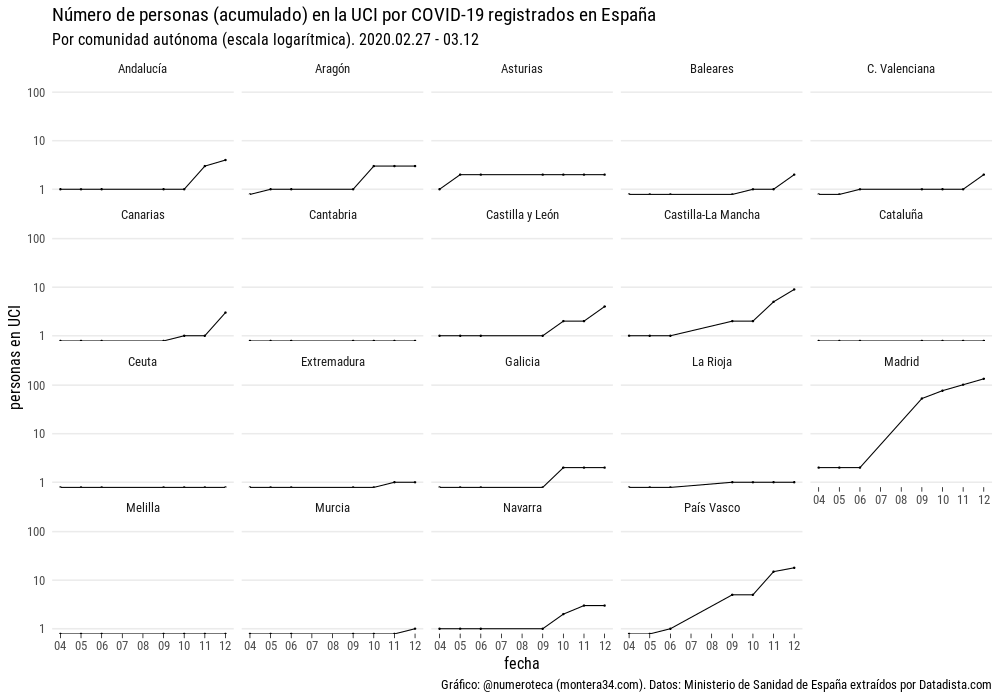
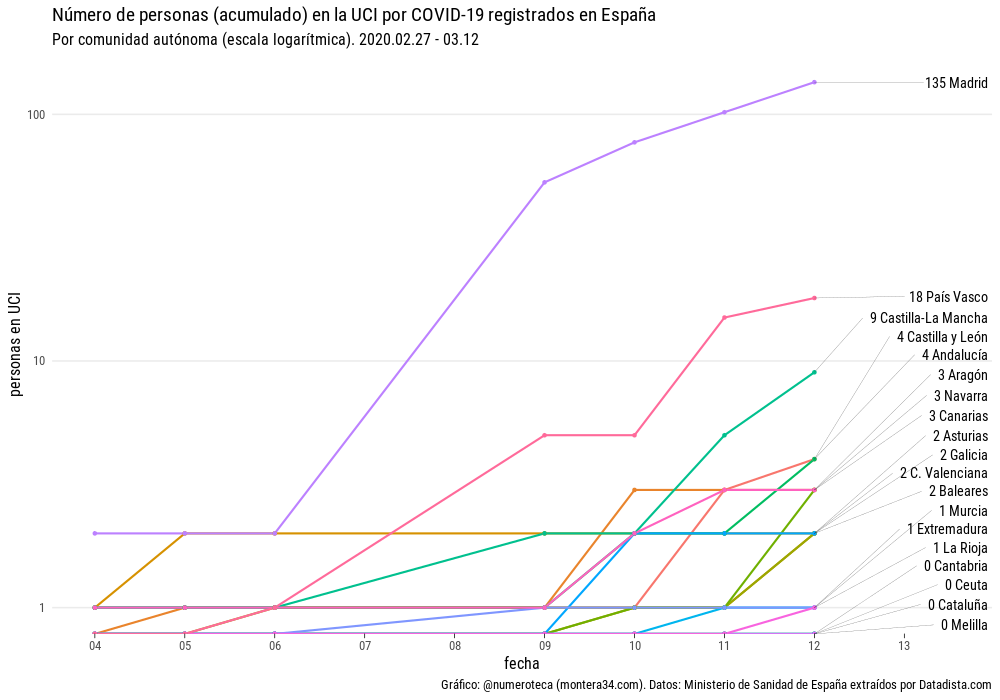
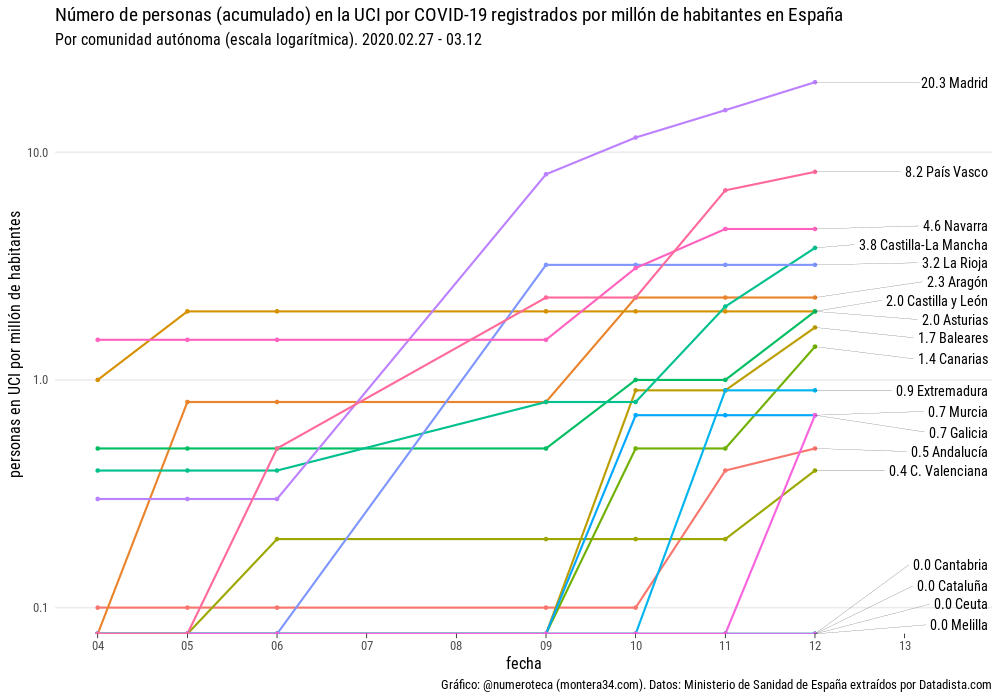
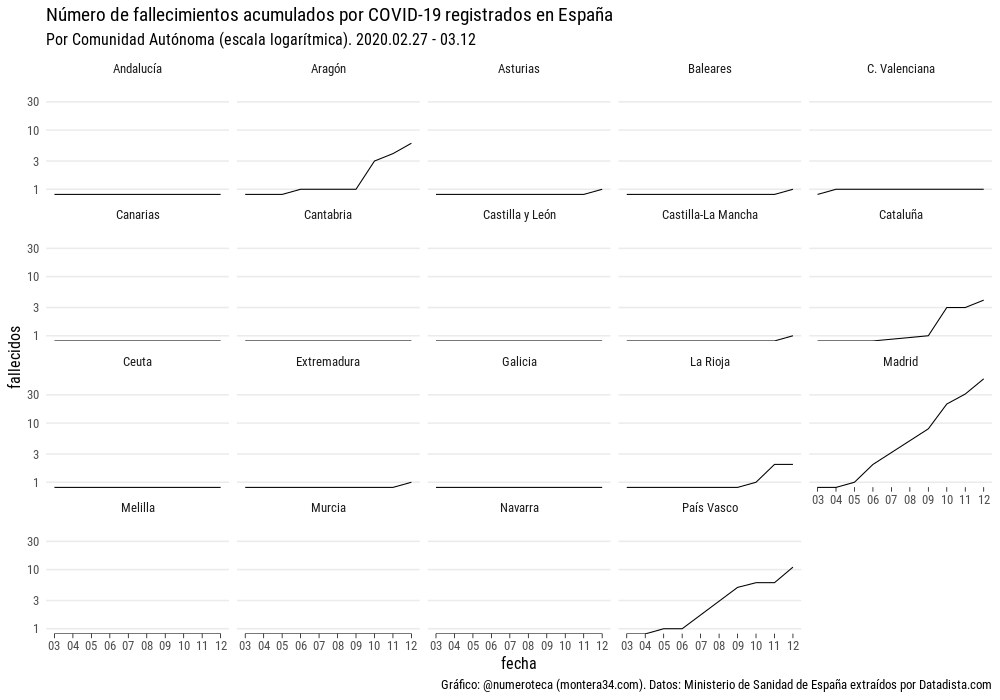
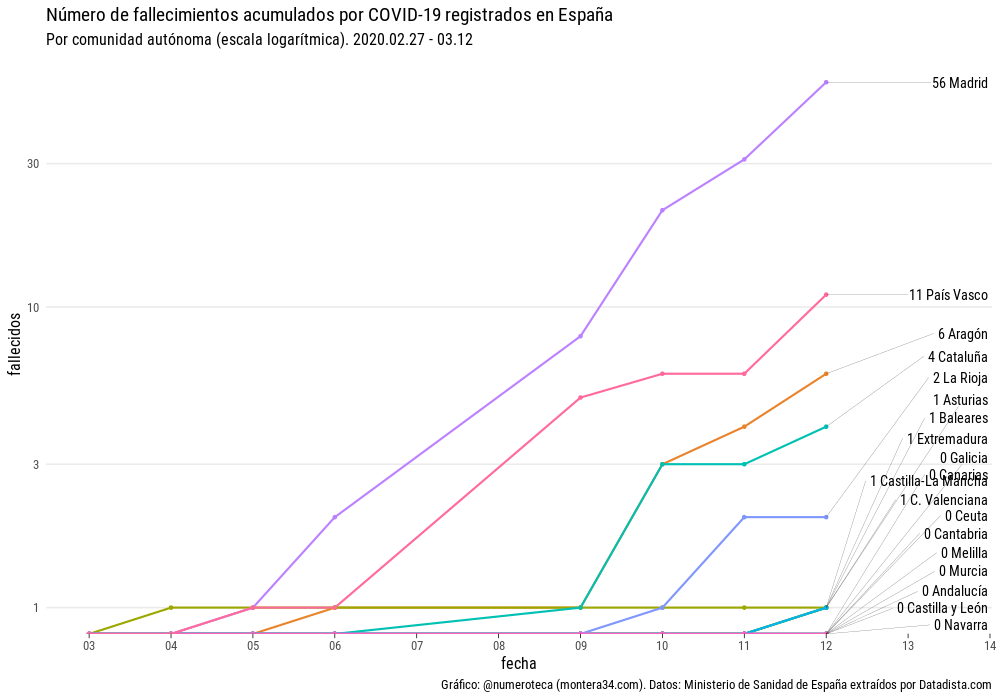
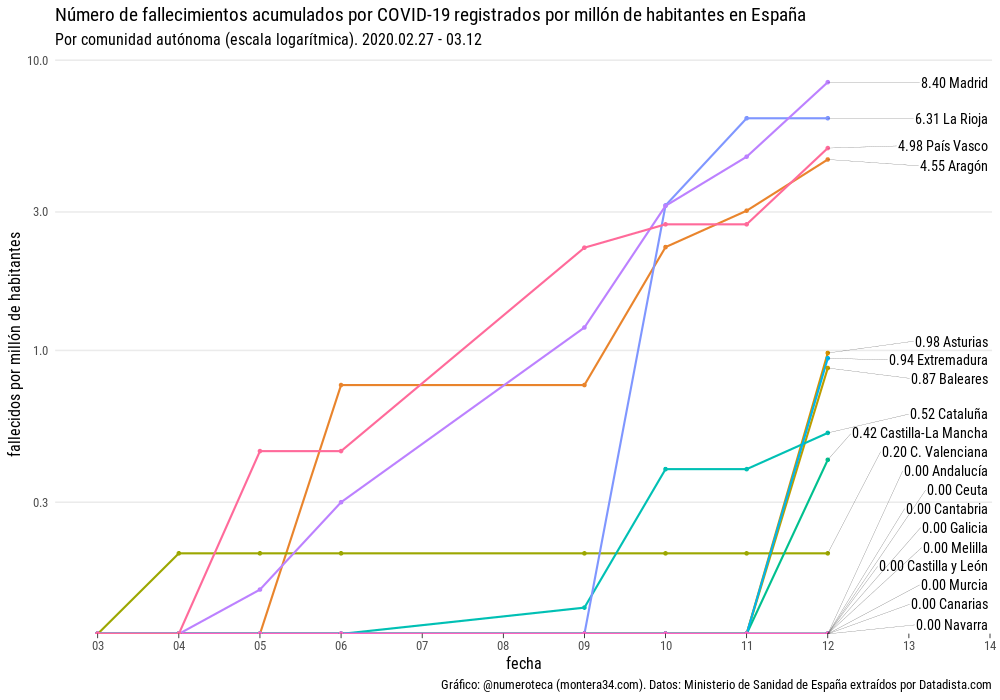
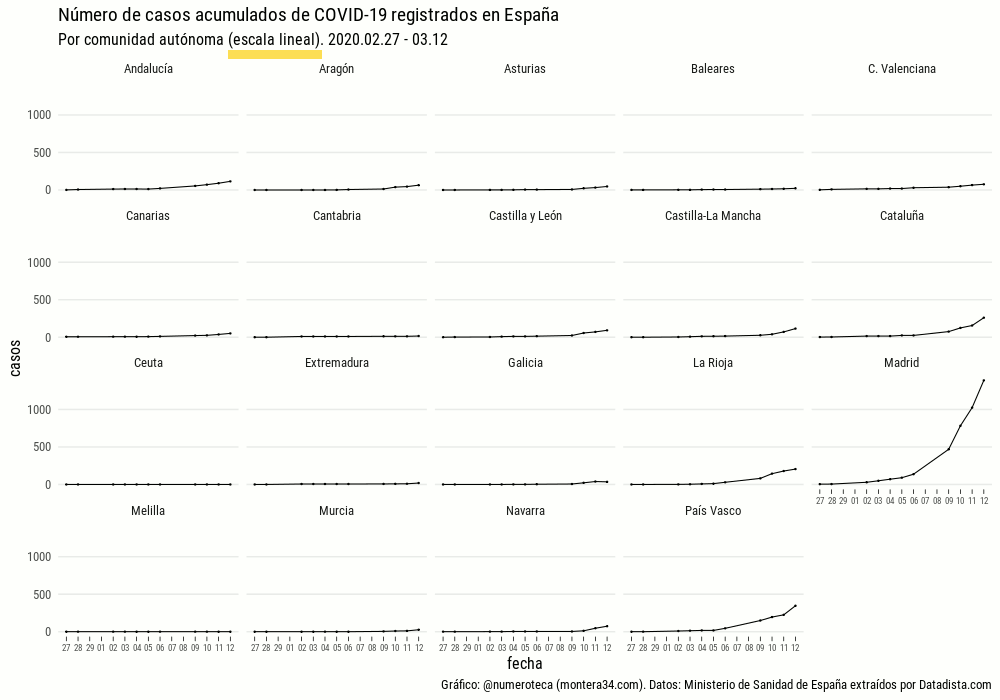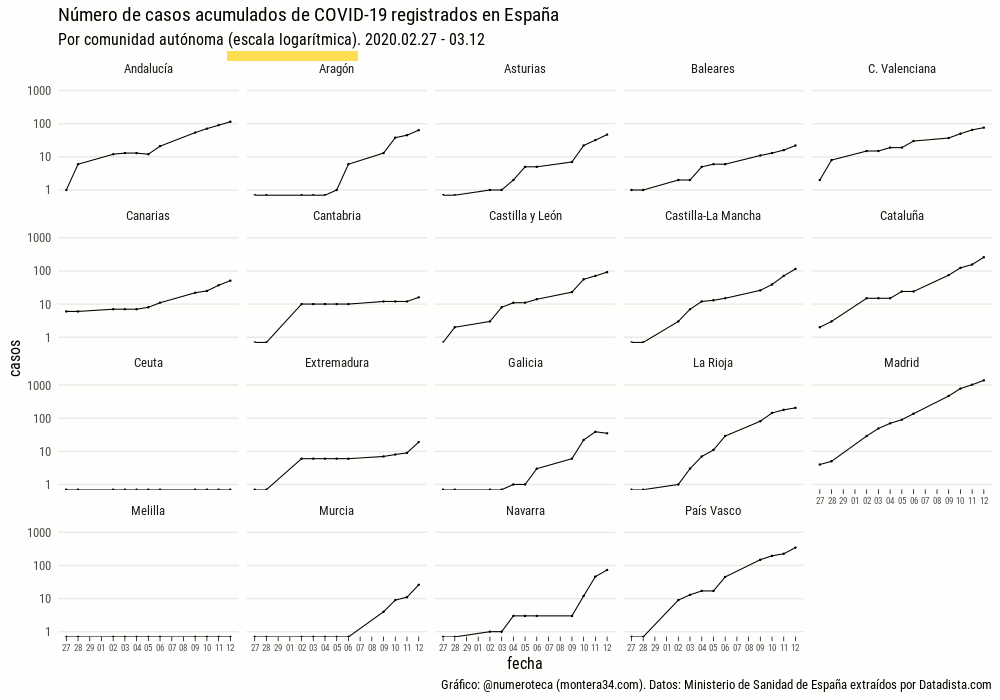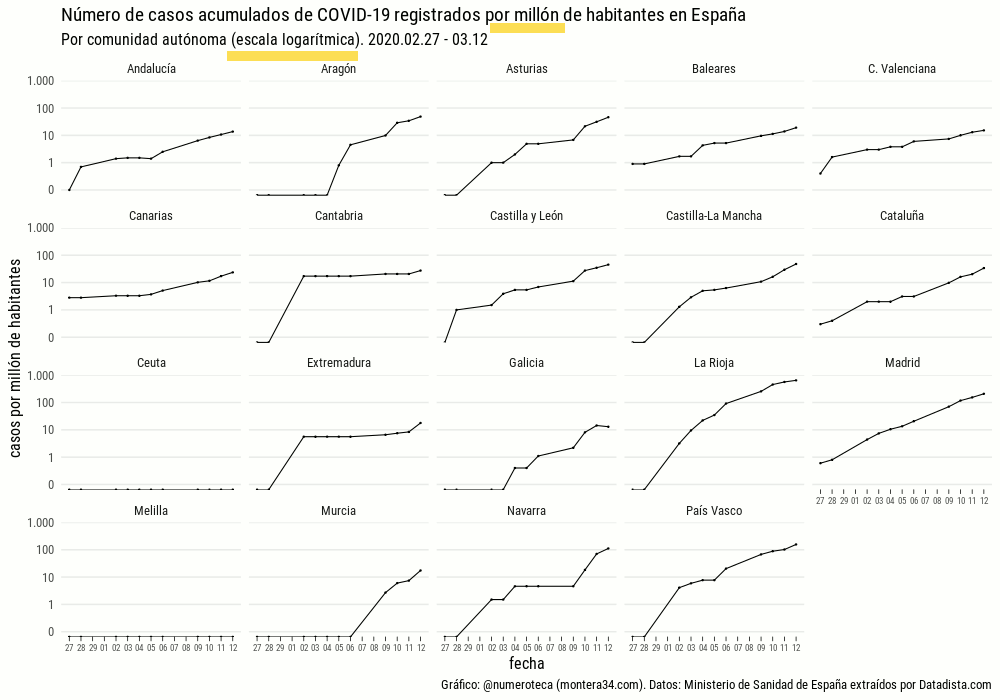
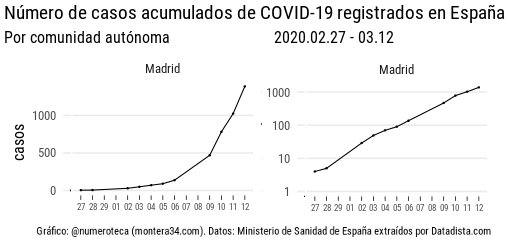
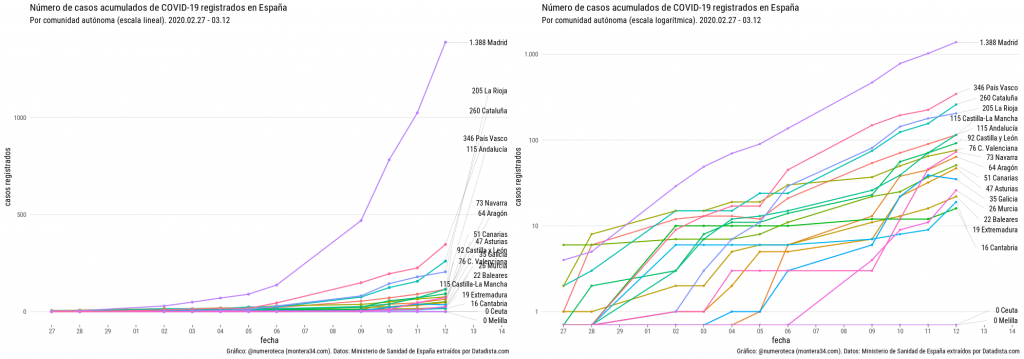
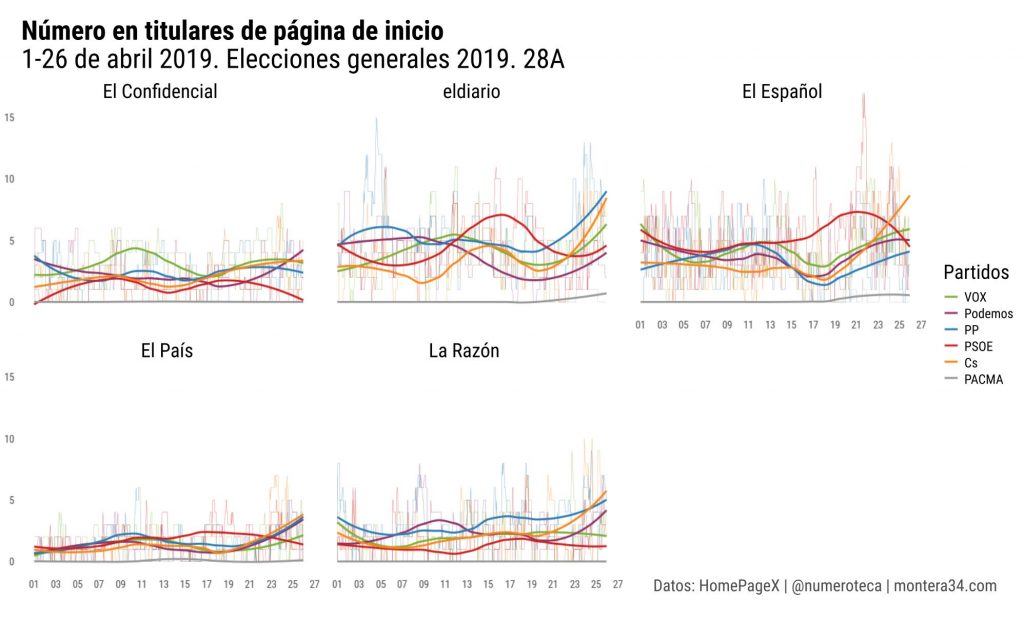
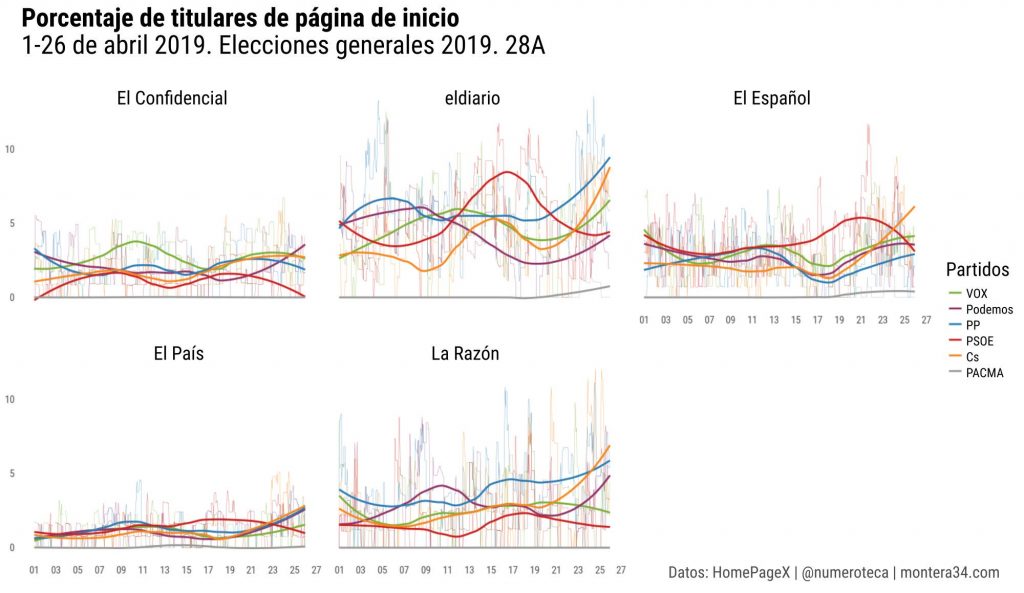
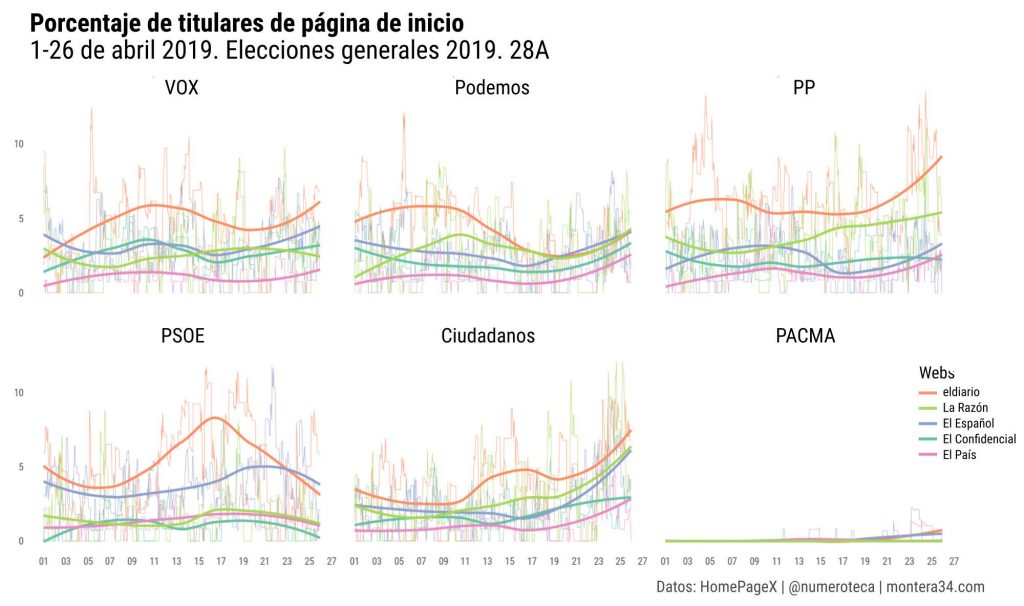













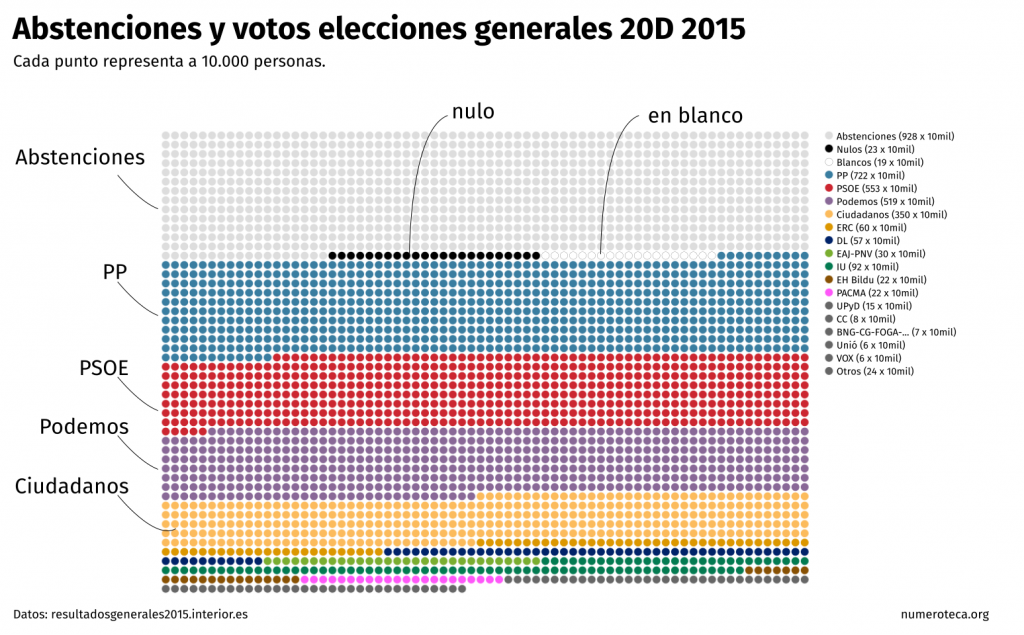
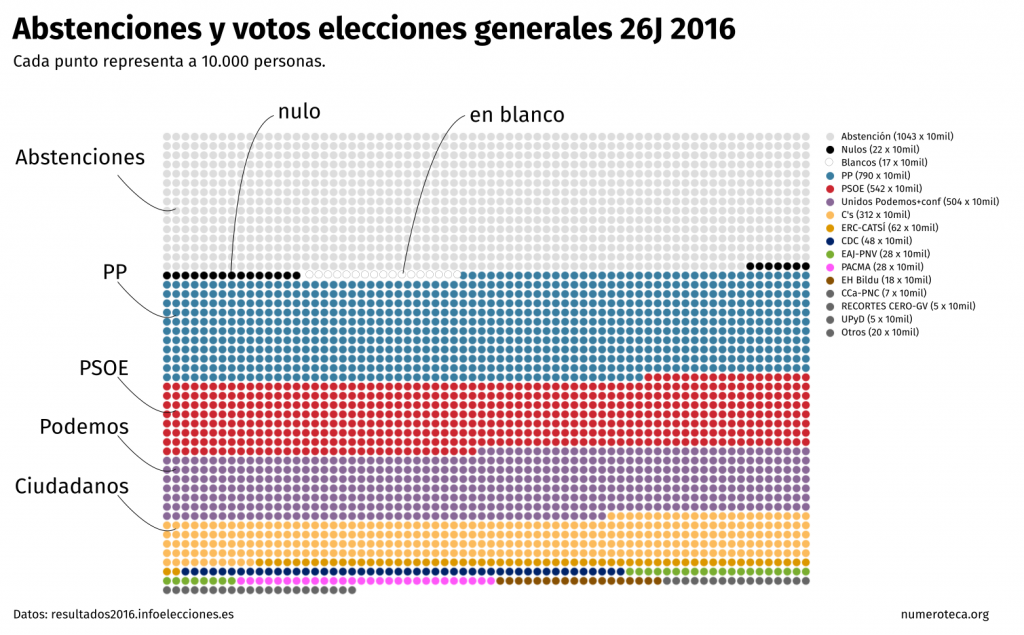
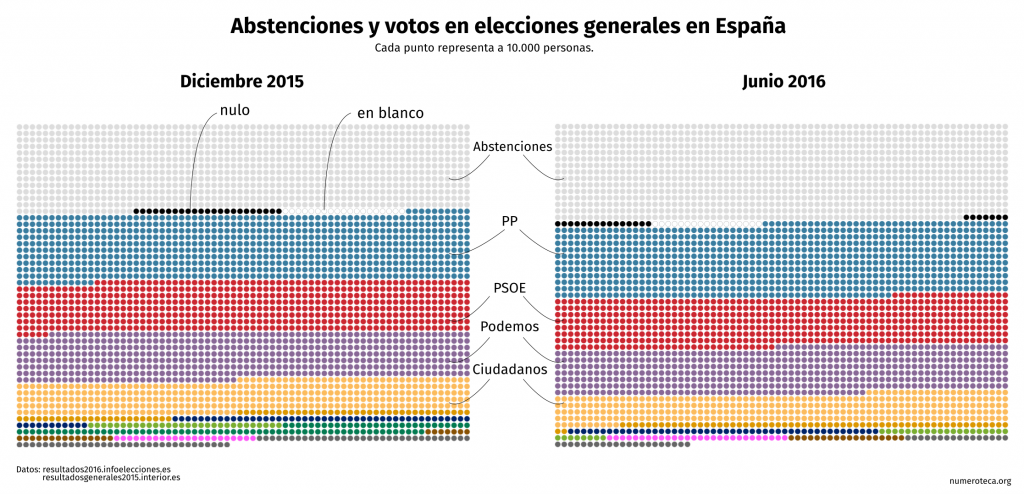
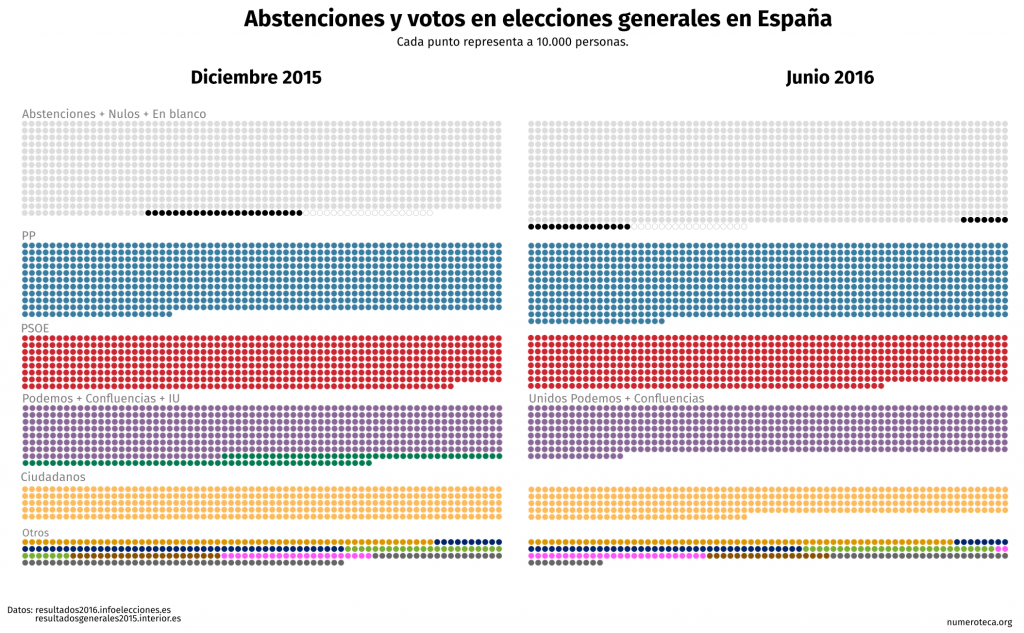
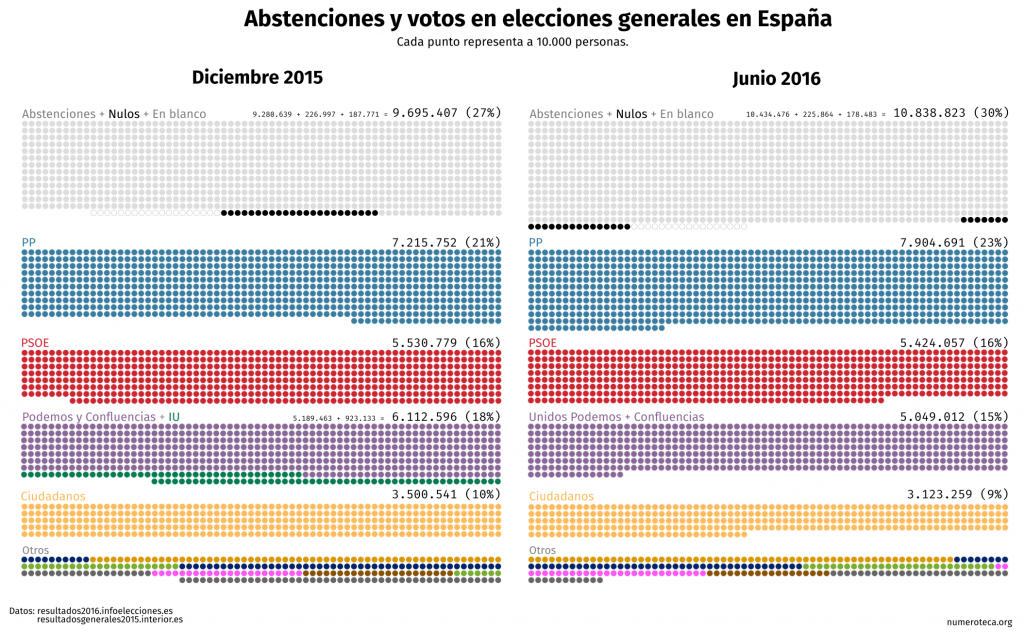
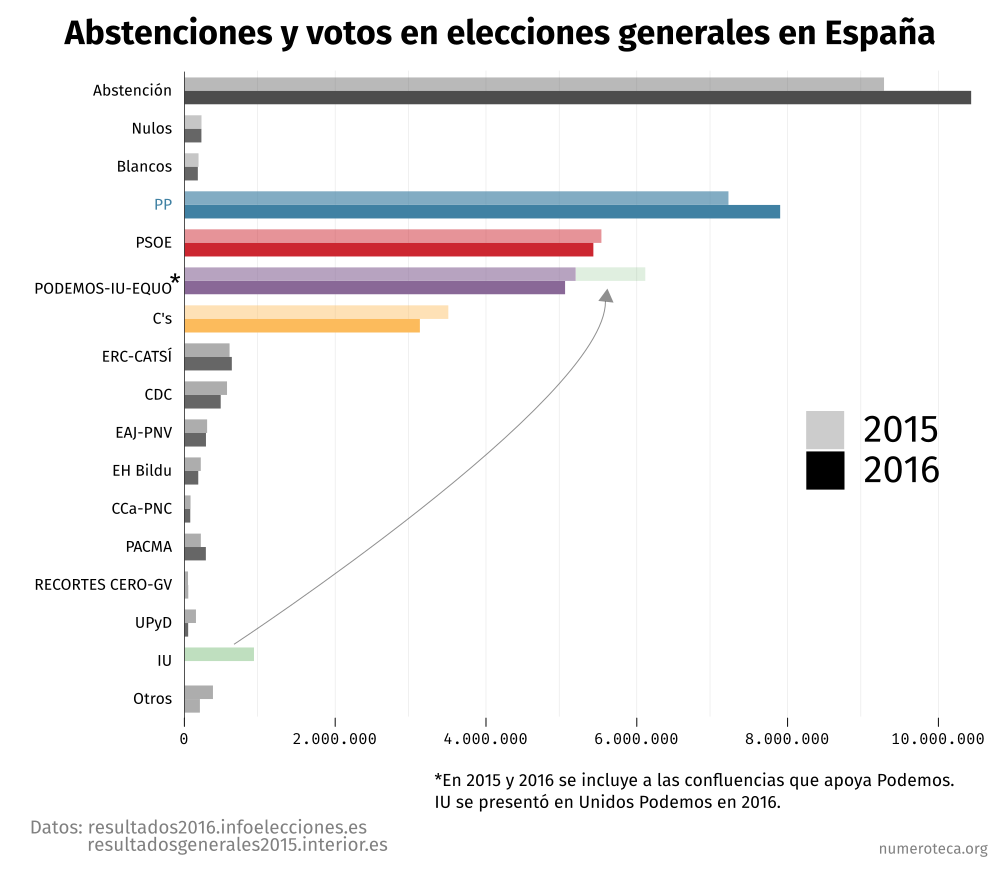

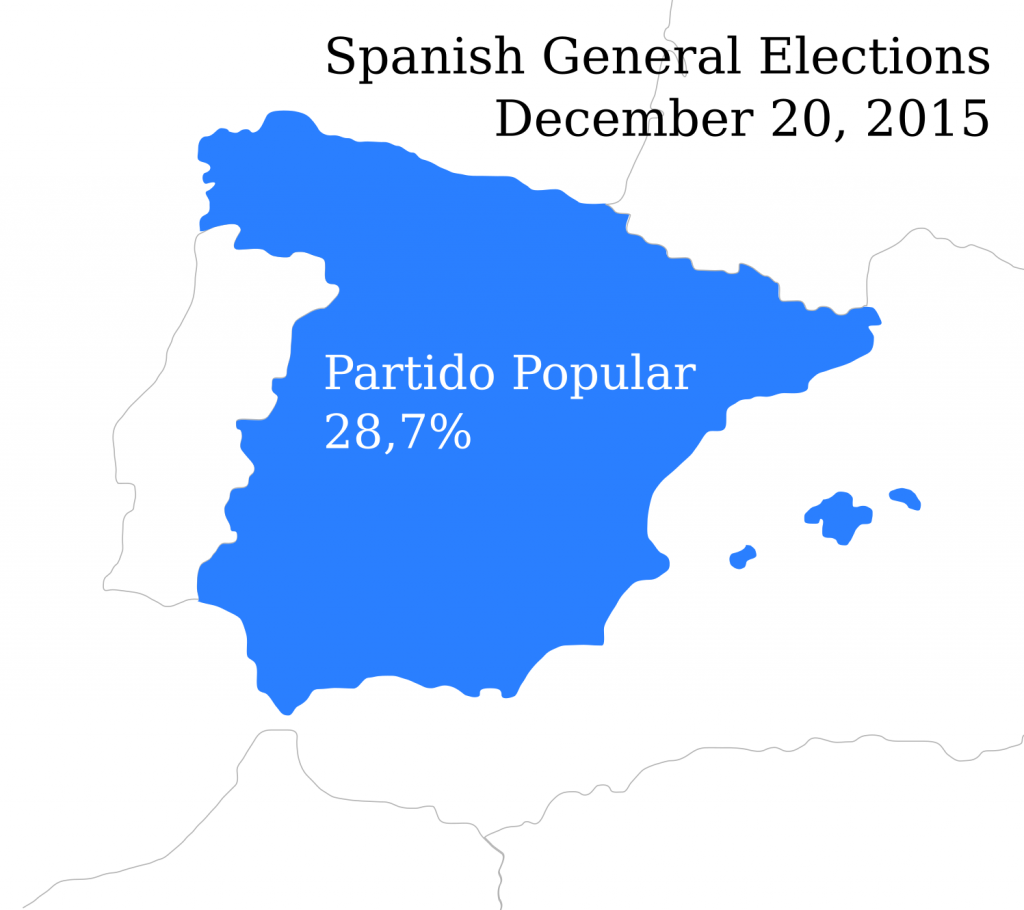
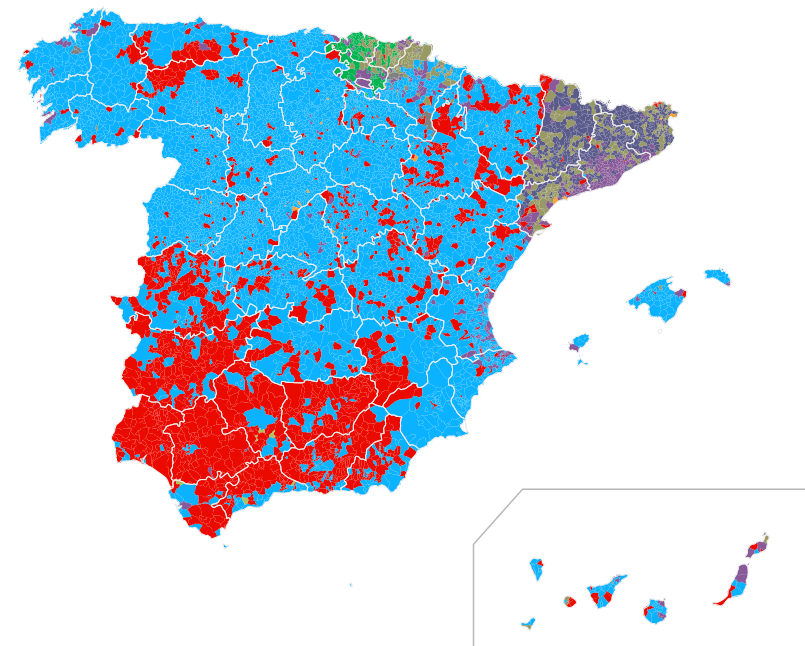
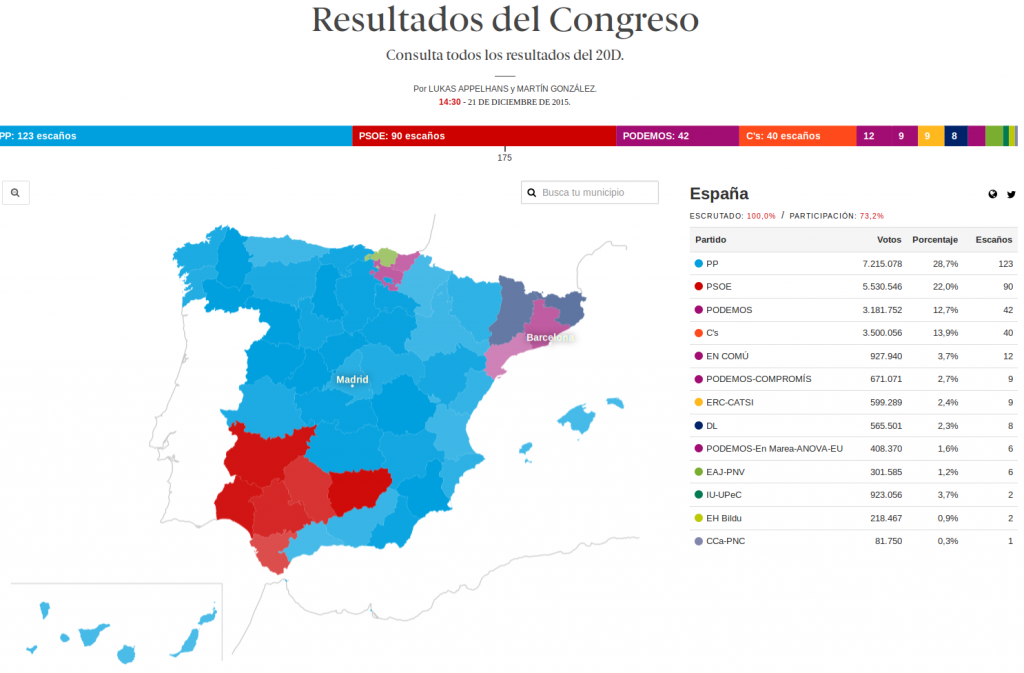
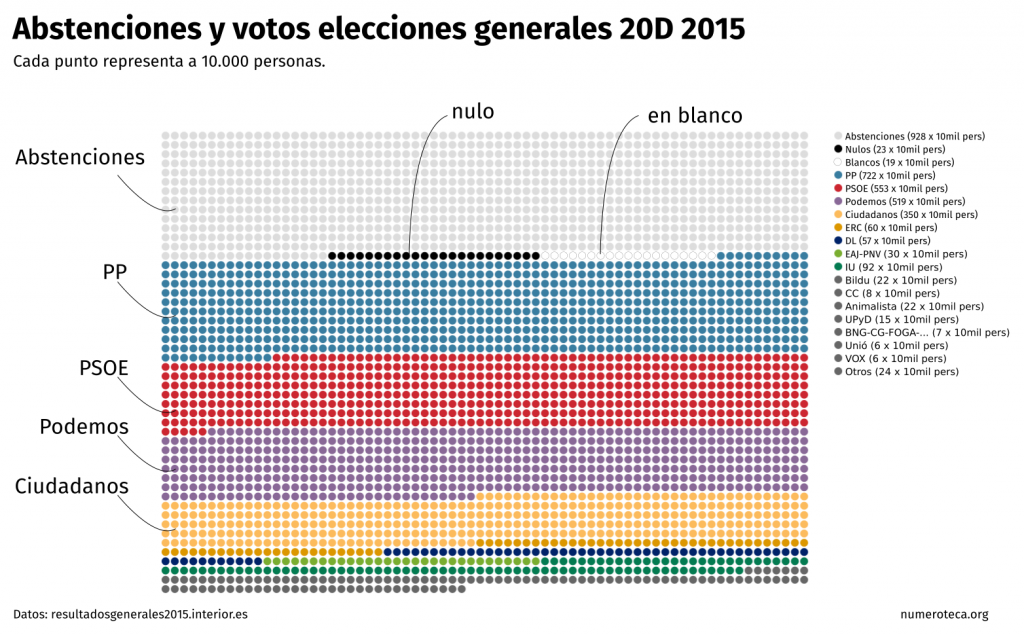
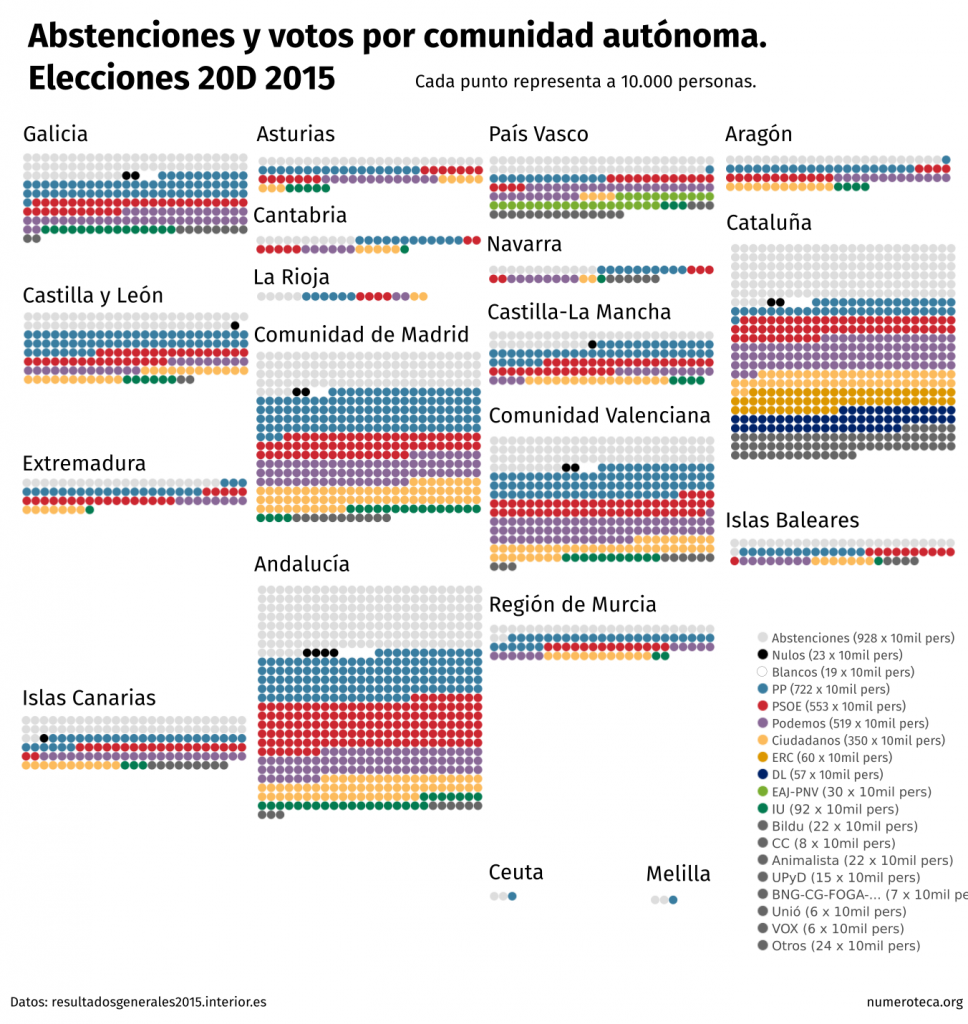
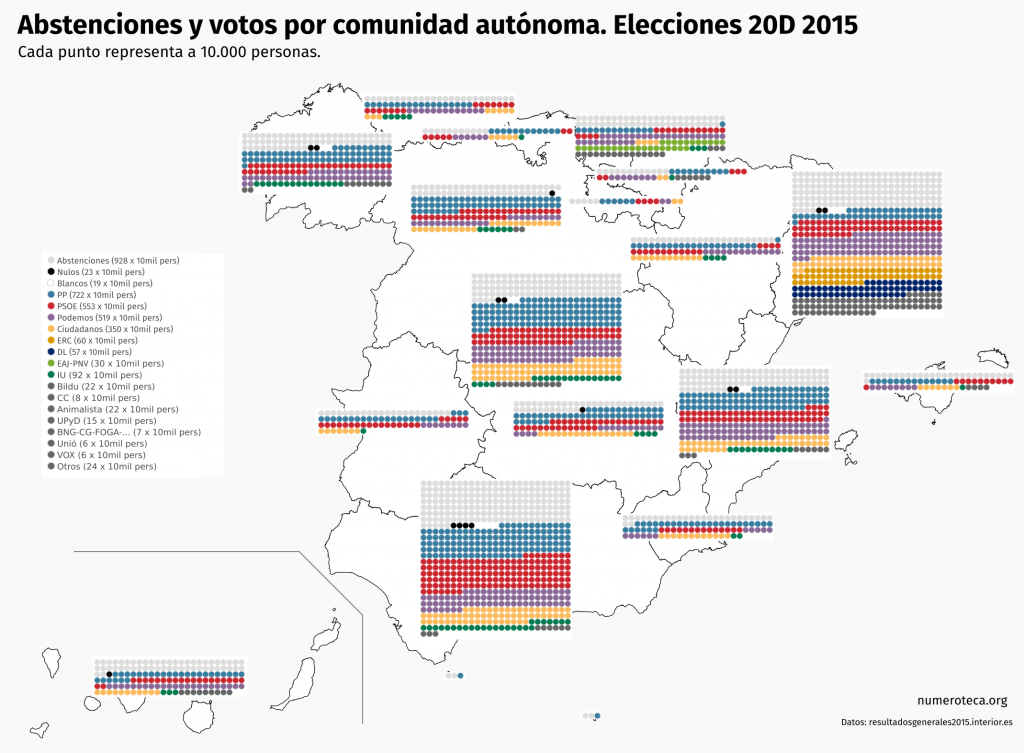






")





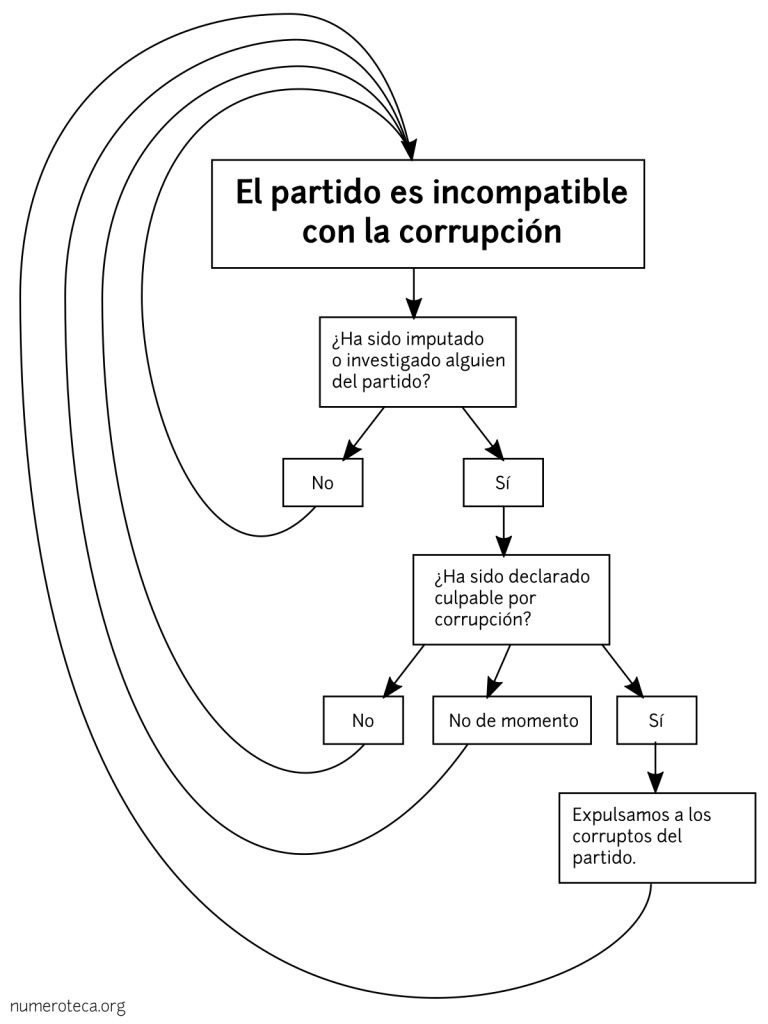

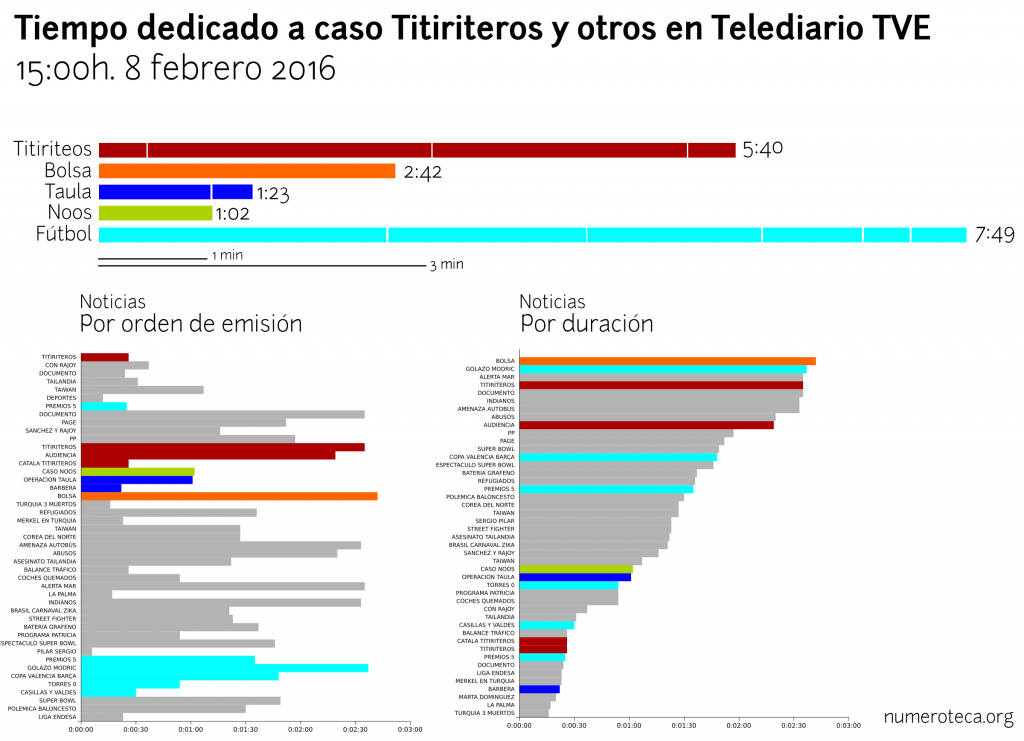









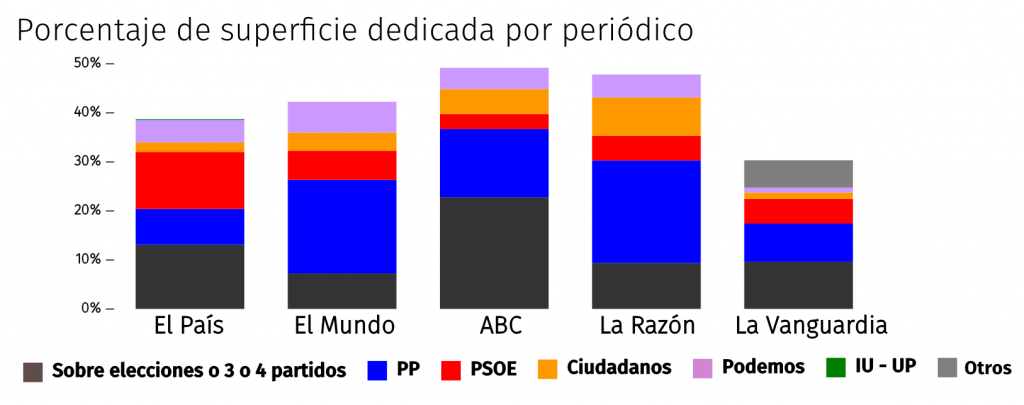
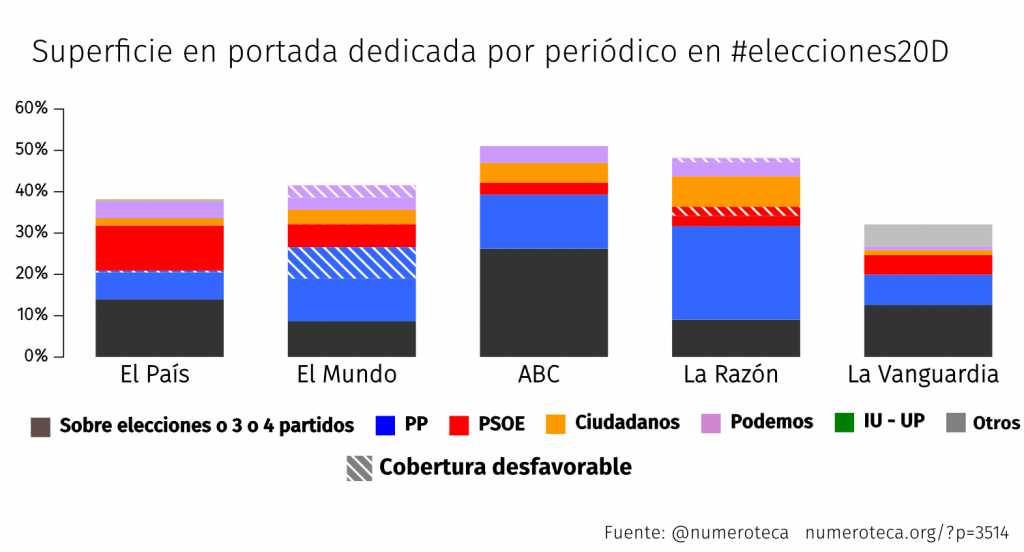
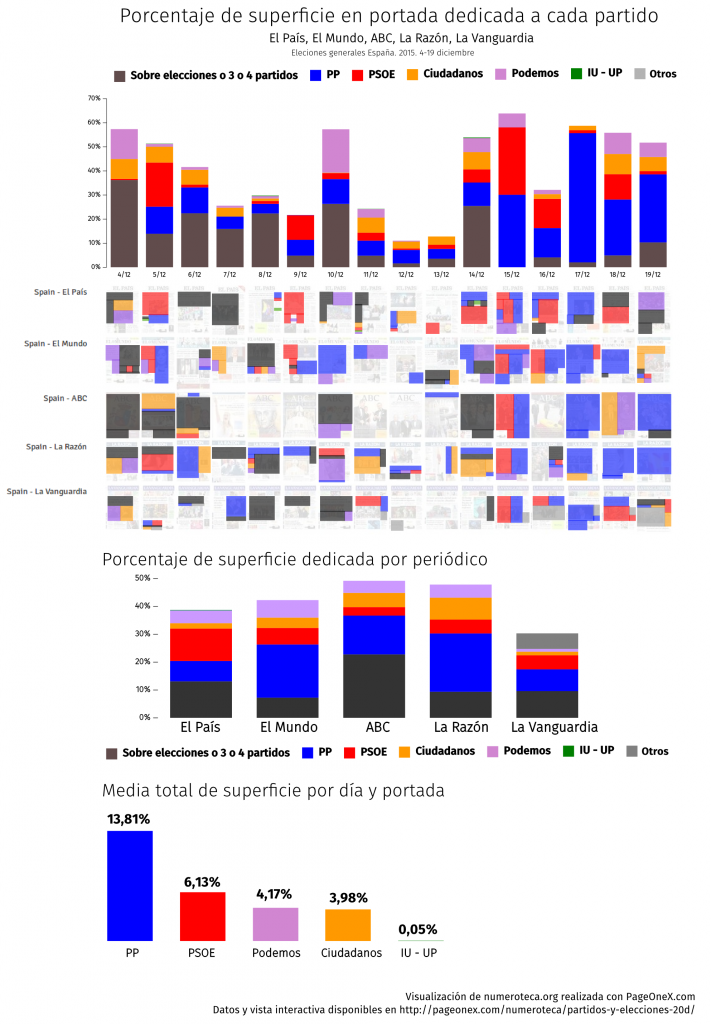
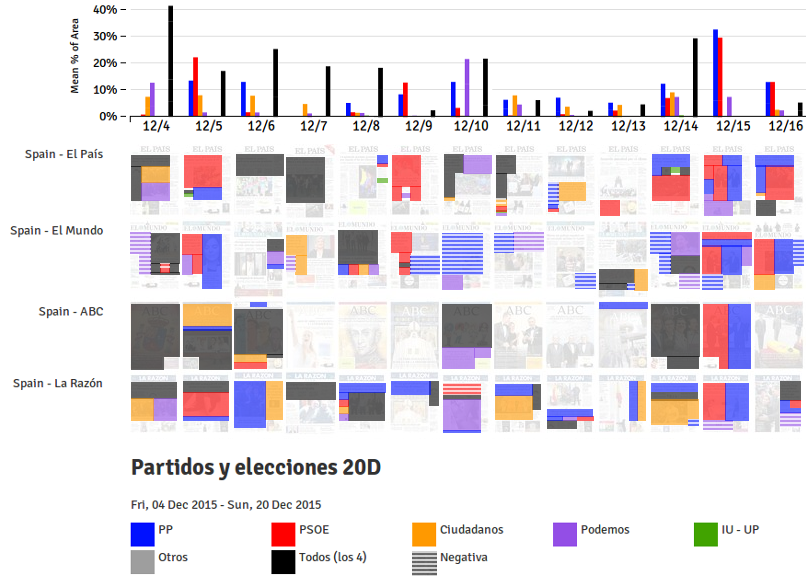





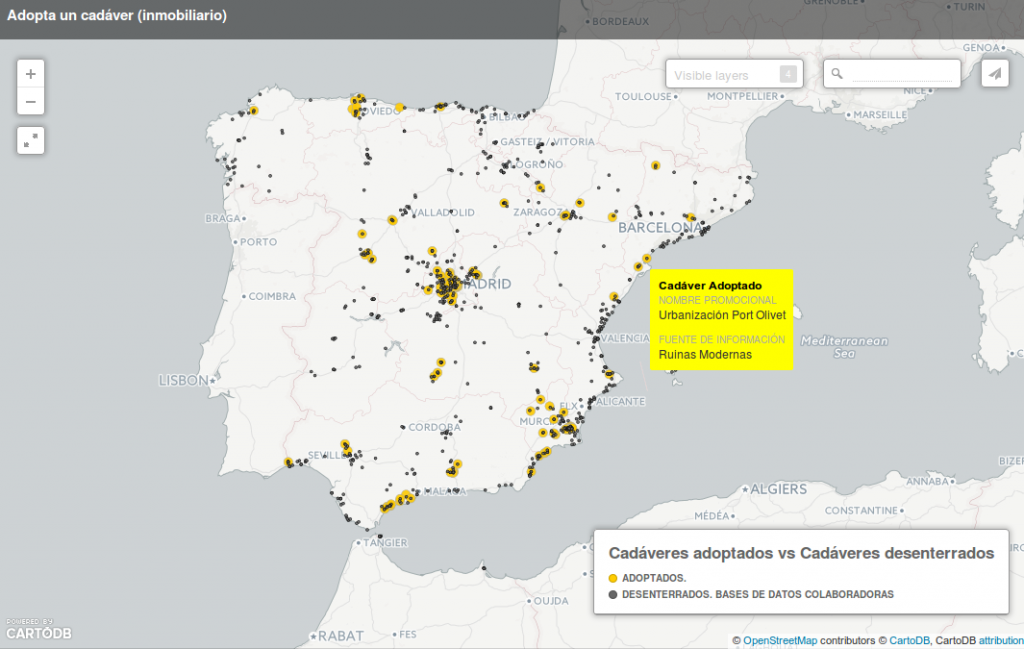




















{kind=link}
{kind=link}