Nota de junio 2020: hay una funcionalidad del t-hoarder que permite el procesado de todos los tuits almacenados. Estoy ayudando a documentarla en la wiki de t-hoarder. Estoy teniendo algunos problemas para que me funcione, tema de CGI.
Para mi tesis sobre cobertura de corrupción en España llevo tiempo recopilando tuits. Llevo el seguimiento de mensajes de Twitter relacionados con algunos casos de corrupción, para luego poder compararlos con cómo los medios de comunicación han hablado del tema.
Utilizo t-hoarder, desarrolllado por Mariluz Congosto, para capturar tuits según se van publicando. Lo tengo instalado en un servidor remoto que está continuamente descargándose tuits que contienen una determindad lista de palabras. Con un interfaz en la línea de comandos desarrollado en python permite interactuar de manera sencilla con la API de Twitter para obtener y procesar tuits descargados (ver este manual que escribimos hace un tiempo para aprender a usarlo).
T-hoarder guarda los tuits en archivos .txt en formato .tsv. Cada cierto tiempo comprime el archivo streaming_cifuentes-master_0.txt en uno comprimido streaming_cifuentes-master_0.txt.tar.gz que contiene entre 150.000 o 250.000 tuits.
En el servidor se van acumulando estos archivos comprimidos que me descargo periódicamente con rsync:
rsync -zvtr -e ssh numeroteca@111.111.111.111:/home/numeroteca/t-hoarder/store/ .
Con ese sistema tengo un directorio con múltiples archivos de los diferentes temas que voy capturando:
El primer paso consiste en entender de forma básica qué he conseguido recopilar. Hay múltiples razones por las que puedo tener agujeros en los datos: el servidor se llenó, el acceso a la API de Twitter se interrumpió por algún problema de permisos, etc.
Para ello he desarrollado este pequeño script en bash para obtener la información básica que contiene cada archivo de tuits:
for f in ./*cifuentes-master*.txt.tar.gz;
do
echo "$f" >> mycifuentes.txt;
gzip -cd $f | (head -n 1) | awk 'OFS="\t" {print $4}' >> mycifuentes.txt;
gzip -cd $f | (tail -n 2) | awk 'OFS="\t" {print $2}' >> mycifuentes.txt;
gzip -cd $f | wc -l >> mycifuentes.txt;
doneEste script lee todos los archivos como streaming_cifuentes-master_20.txt
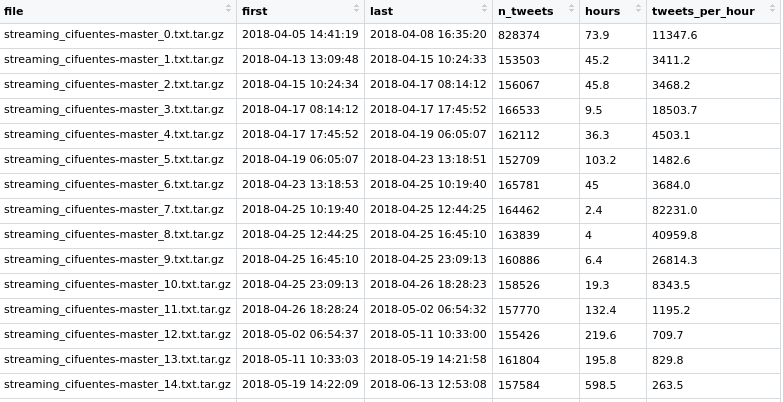
y va guardando en cada línea del archivo mycifuentes.txt en líneas separadas: el nombre del archivo tar.gz, la fecha y hora del primer tuit (head) y del último (tail) y por último el número de tuits. Con eso obtengo un archivo como este:
./streaming_cifuentes-master_11.txt.tar.gz
2018-04-26;18:28:24
2018-05-02;06:54:32
;
157770
./streaming_cifuentes-master_12.txt.tar.gz
2018-05-02;06:54:37
2018-05-11;10:33:00
;
155426Que proceso a mano en gedit son sustituciones masivas (me falta generar mejor el tsv donde cada campo esté en la línea que le corresponde):
Actualización 8 junio 2020: Gracias a @jartigag@mastodon.social que me llegó por Twitter no me hace falta el procesado manual ya que cada dato va a su propia columna:
for f in ./*cifuentes-master*.txt.tar.gz;
do
printf "$f\t" >> mycifuentes.txt;
gzip -cd $f | (head -n 1) | awk '{printf $4"\t"}' >> mycifuentes.txt;
gzip -cd $f | (tail -n 2) | awk '{printf $2"\t"}' >> mycifuentes.txt;
gzip -cd $f | wc -l >> mycifuentes.txt;
doneEste es el resultado en formato tabla:
| file | start | end | number_tweets |
| streaming_cifuentes-master_0.txt.tar.gz | 2018-04-05 14:41:19 | 2018-04-08 16:35:20 | 828374 |
| streaming_cifuentes-master_10.txt.tar.gz | 2018-04-25 23:09:13 | 2018-04-26 18:28:23 | 158526 |
| streaming_cifuentes-master_11.txt.tar.gz | 2018-04-26 18:28:24 | 2018-05-02 06:54:32 | 157770 |
| streaming_cifuentes-master_12.txt.tar.gz | 2018-05-02 06:54:37 | 2018-05-11 10:33:00 | 155426 |
Proceso este archivo mycifuentes_processed.tsv, sin cabecera con este otro script de R:
mylist <- read_tsv("../../data/t-hoarder-data/store/mycifuentes_processed.txt", col_names=FALSE, quote="")
names(mylist) <- c("file","first","last","n_tweets")
mylist <- mylist %>% arrange(first) %>% mutate(
hours = last - first, # tweets per hour
tweets_per_hour = round( n_tweets / as.integer(hours), digits=1)
)lo que hace es leer el archivo (read_tsv) y cuenta las horas entre el primer y último tuit y calcula los tuits por hora:
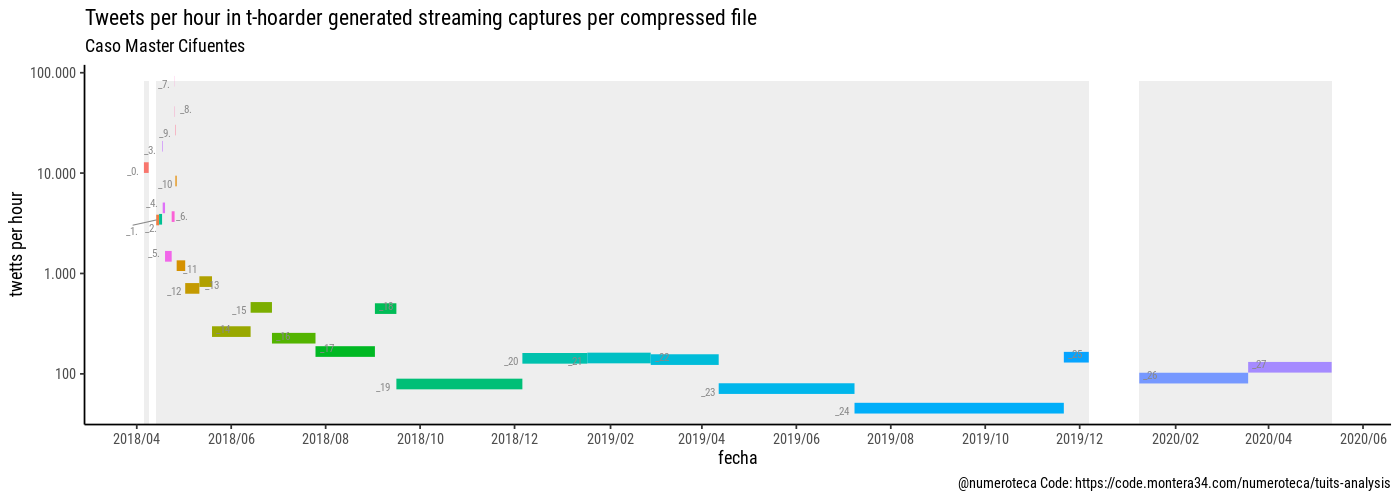
Ahora ya podemos hacer las primeras visualizaciones para explorar los datos. En este primer gráfico cada línea es un archivo que va del primer al último tuit según su fecha. En el eje vertical se indica el número medio de tuits por hora. En el caso del master de Cifuentes el primer archivo no se comprimió por error y contiene 828.374 tuits. el fondo gris indica cuando no hay tuits descargados. Hay un periodo en blanco la inicio del caso y otro en diciembre de 2019, la escala vertical es logarítmica, para que se puedan ver todos los archivos incluyendo los primeros.
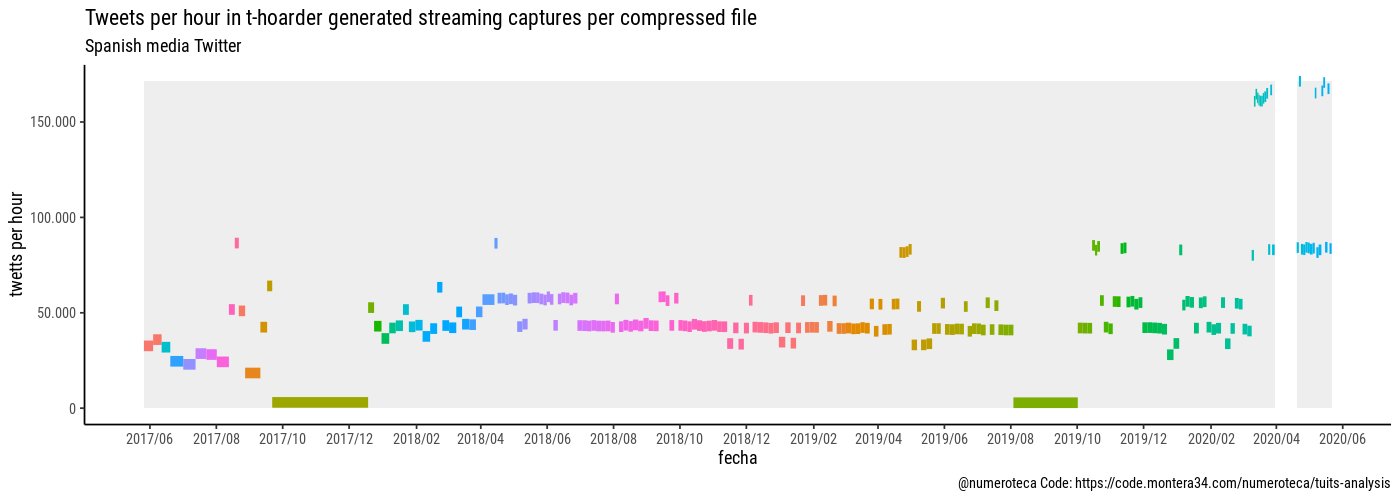
En este otro gráficos (escala vertical lineal) muestro los archivos de tuits que he capturado de unos cuantos medios de comunicación españoles, para luego poder comparar las diferentes coberturas, vuelvo a tener agujeros para los que todavía tengo que encontrar explicación.
En este otro gráfico comparo la fecha del archivo con el número de tuits que contiene:
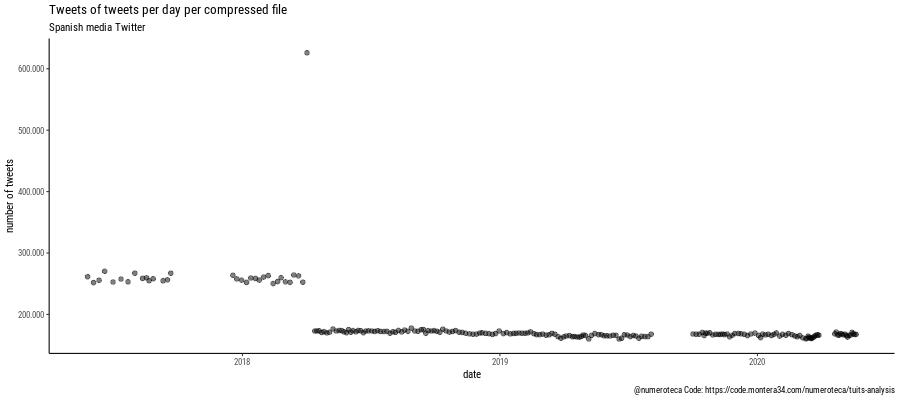
Este es un primer análisis muy “meta” que no entra ni de lejos a analizar el contenido de los tuits pero me sirve como primer paso para entrar en faena a analizar los datos que tengo. Tenía que haber hecho esto hace tiempo. En cualquier caso bueno es ponerse en marcha y documentar. Mis conocimientos de bash son escasos pero creo que merece la pena y es más rápido en este caso que usar R. Inspirado por este libro que estoy a medio leer Data Science at the Command Line de Jeroen Janssens.
5 Easy Facts About https fortnite com 2fa Described buy testosterone cypionate 250mg ski-in/ski-out hotel sport, saas-almagell: find the best priceEl código de R para procesar los datos está disponible en este script: https://code.montera34.com:4443/numeroteca/tuits-analysis/-/blob/master/analysis/index-tweet-containers.R