Recientenemente me han ocurrido varios hechos, que de por sí podrían ser meros errores o bugs en el sistema, pero que todos juntos evidencia que algo falla en las herramientas de transparencia y rendición de cuentas.
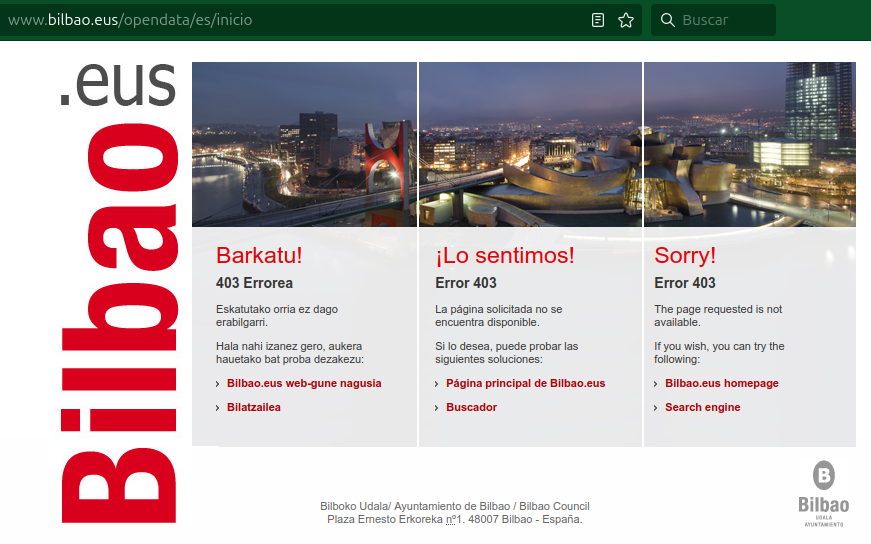
La página web con las Solicitudes de acceso a la Información Pública, no funciona
Al hacer click en cualquier de los años se abre por una fracción de segundo la tabla con las solicitudes, pero se vuelve a cerrar, haciendo imposible navegar por la información. A ver, se puede trucar el css y html para poder verlo, pero supone una barera inslvable para acceder a la información para practicamente todo el mundo que visite esta página. Aquí un poco de contexto, de una investación en la que colaboré hace años, sobre la Comisión Vasca de Acceso a Información Pública, que es quien publica estas resoluciones sobre las solicitudes. Pongo el link porque es el que uso para llegar a la web que lista todas las solicitudes, que no suele ser fácil de encontrar. Por otro lado, en este listado no siempre se publican los datos que reclamaban las solicitudes de información pública que tuvieron éxito, pero esa ya es otra historia. Esta página lleva sin funcionar, al menos según la captura de Archive.org, desde el 18 junio de 2025.
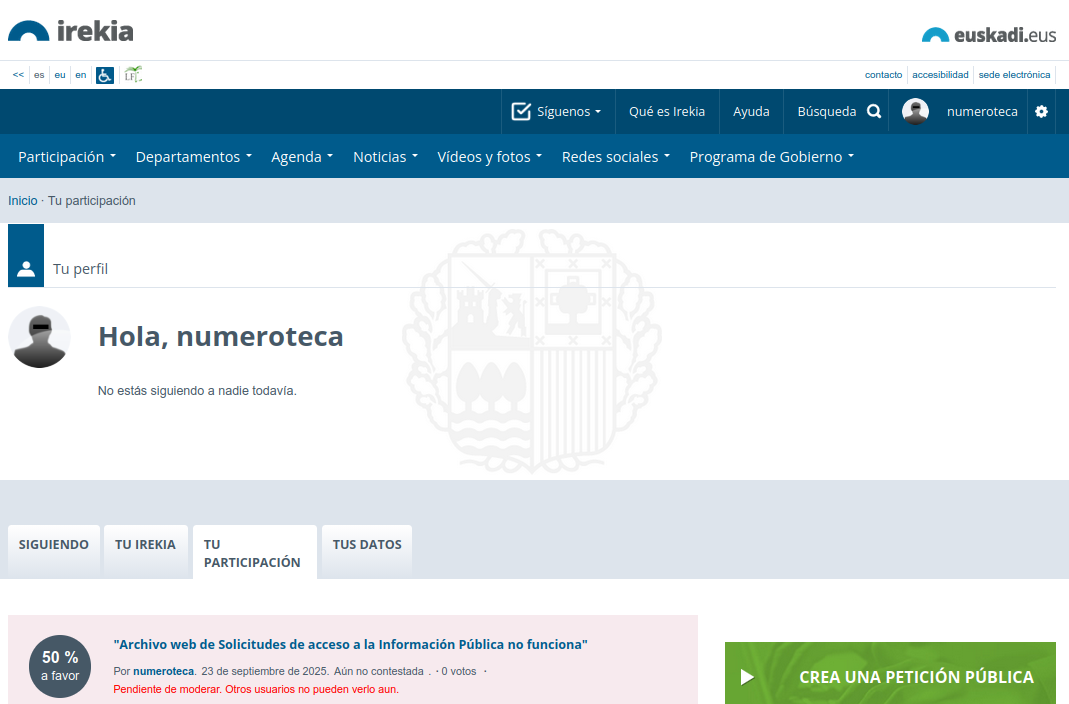
Al ver que la web no funcionaba, creé una petición pública en Irekia, que canaliza las peticiones ciudadanas, para ver si podían repararla. De esto hace un mes (23 de septiembre de 2025) y sigue esperando aprobación ¿aprobación de quién? ¿qué más hace falta? Seguimos sin poder acceder a las solicitudes.
El Ayuntamiento de Bilbao consiguió evitar el juicio que iba a celebrarse hoy jueves para no tener que dar explicaciones sobre la aplicación de la normativa. El juzgado condenó simbólicamente al Ayuntamiento en costas.
Apatruyando la ciudad Por el parque con su coche Apatruya la ciudad (Foto tomada minutos después de que me pusieran la multa).
En mayo de 2023 me multaron por ir con mis hijos en bici por el parque de Doña Casilda en Bilbao. Recurrí la multa y el Ayuntamiento de Bilbao desestimó mis alegaciones. Recurrí entonces ante los juzgados de lo contencioso-administrativo para que se aclarara si era acorde a la normativa o no circular en bicicleta por el parque. Tras varios aplazamientos, se fijó el juicio para el 19 de septiembre.
En agosto de 2024, el gobierno municipal intentó mediante la anulación de la multa evitar el juicio y así no tener que dar explicaciones sobre la normativa que regula la circulación en bici. Su argumento, 16 meses después de poner la multa, era que el expediente no había sido “debidamente tramitado” y solicitaba el archivo por satisfacción extraprocesal. Esto de “satisfacción” es un eufemismo, porque seguimos sin aclaración de cuál es la correcta aplicación de la normativa, que era y es el principal objetivo.
Presentamos alegaciones, porque no habían anulado la multa conforme a los procedimientos requeridos en el derecho administrativo, ni la habían motivado ni notificado correctamente. Hoy ha llegado la notificación del juzgado que anuncia el archivo definitivo del juicio, pasando por alto las alegaciones. Se condena en costas al Ayuntamiento a pagarme 50€ en costas: “Se impone a la parte demandada las costas causadas en el presente recurso, por importe de 50 euros sin incluir el IVA”.
El importe es simbólico, porque imaginad lo que habría podido suponer pagar a un abogado, si no fuera porque apoyó esta causa gratuitamente desde el principio. Donaré esa cantidad a la Asociación Biziz Bizi, Asociación de ciclismo urbano de Bilbao, que me ha apoyado en todo este proceso. Un dinero, que, por otra parte, lo hemos pagado entre todos.
Nos toca buscar otros caminos para que la normativa se aclare. Seguiremos informando. Hablo en plural, porque en el proceso hemos aunado fuerzas la buena gente Biziz Bizi y Aitor Anchía, el abogado que ha hecho posible este proceso judicial. Una alegría encontrar nuevos amigos mientras intentamos hacer el mundo un poco mejor. Han pasado más cosas positivas en este proceso. Por ejemplo, que al principio de todo esto monté una web donde poder buscar en las ordenanzas municipales, porque la web del Ayuntamiento solamente te permite descargar cada PDF por separado. Y más tarde, siguiendo con esta idea de “abrir” lo que contienen los PDF y hacerlos buscables, hice otra web para buscar en las actas de los plenos municipales y los de distrito desde 2007.
Ahora puedo circular de nuevo en bici por Doña Casilda cuando la concurrencia de personas así lo permita, aunque no tenga la sentencia que me hubiera gustadoa enseñar a la policía si me paraba. De momento he ido a probar hoy, de camino a la inauguración-protesta del carril bici de Biziz Bizi. No me han puesto multa.
PD1: Publicaremos todos los documentos de este litigio, convenientemente anonimizados, por si pueden servir a otras personas en sus luchas contra la Administración.
PD2: El Ayuntamiento vio que iba a tener que responder en el juicio a este listado de preguntas que el juzgado había aprobado:
1. ¿Es cierto que el Ayuntamiento de Bilbao, a través de sus Ordenanzas permite que adultos circulen en bicicleta u otros medios de transporte similares en zonas peatonales cuando la concurrencia de personas así lo permita, extremándose en todo caso las medidas de seguridad por parte de la persona usuaria de tales artilugios?
2. ¿Es cierto que el Ayuntamiento de Bilbao, a través de sus Ordenanzas permite que adultos acompañen en bicicleta u otros medios de transporte similares, a menores hasta ciertas edades, ya sea 7, 10 o 12 años?
3. ¿Es cierto que la Policía Municipal de Bilbao tenía un dispositivo de vigilancia especial en la fecha de la multa en el parque de Doña Casilda? Si la respuesta es afirmativa, ¿en qué consistía ese dispositivo y qué motivo el mismo?
4. ¿Existen informes que justifiquen la actuación de ese dispositivo impidiendo a un adulto acompañar en bicicleta u otros medios de transporte similares a menores en bicicleta hasta ciertas edades, ya sean 7, 10 o 12 años?
5. ¿El Ayuntamiento ha realizado la evaluación de las Ordenanzas Espacio Público y de Espacios Verdes que indica el artículo 130 LPAC desde su aprobación hasta la actualidad? Si la respuesta es negativa, ¿por qué no se ha realizado?
6. ¿El Ayuntamiento ha publicado las evaluaciones de las Ordenanzas Espacio Público y de Espacios Verdes que indica el artículo 130 LPAC desde su aprobación hasta la actualidad? – Si la respuesta es afirmativa, ¿dónde las ha publicado? Si la respuesta es negativa, ¿por qué no las ha publicado?
7. ¿El Ayuntamiento ha realizado a través de la policía municipal cursos para aprender a hacer uso de la bicicleta? Si la respuesta es afirmativa, ¿en esos cursos se ha transitado por zonas que luego la policía municipal ha sancionado a personas desplazándose en bicicleta como el paseo de Deusto junto a la ría?
¿Os acordáis de la multa que me pusieron por ir con mis hijos en bici por Doña Casilda? Eso fue en mayo de 2023. La recurrí en julio y su desestimación me llegó en octubre. En diciembre presenté una demanda contra el Ayuntamiento de Bilbao para recurrir la multa mediante un recurso contencioso-administrativo en los juzgados. Tras varios aplazamientos, el juicio será el jueves 19 de septiembre, justo en mitad de la Semana Europea de la Movilidad. No creo que hubieran podido escoger mejor fecha. Pero, para ser rigurosos, ya no es seguro que haya juicio, porque el Ayuntamiento ha anuladola multa, al menos aparentemente, para intentar evitarlo.
En un principio me ofrecieron un procedimiento abreviado, pero elegí la vista oral,
porque el objetivo de todo esto es esclarecer para mi, para mis hijos y para todos mis compañeros, que si alguien vuelve a ir en bici por el parque no le pondrán una nueva multa. Queremos saber qué implican, en la práctica, las confusas normativas municipales sobre ir en bici por el parque de Doña Casilda. Y ya que estamos, sobre todos los parques y otras zonas peatonales donde también han puesto multas a ciclistas, como en el paseo junto a la ría entre el puente de Gehry y Elorrieta.
Sin embargo, el gobierno municipal no parece estar interesado en esclarecer nada de esto. Ha propuesto al juzgado que no se lleve a cabo el juicio porque ha anulado la multa “al apreciarse irregularidades procedimentales en su tramitación” y que “se comprueba que no fue debidamente tramitado”. Me quitan la multa, pero por problemas en el trámite, sin especificar, así que nos quedamos como estamos. La dificultad, por no decir imposibilidad, de interpretación de las normas genera una inseguridad jurídica que lleva indirectamente a establecer un margen de arbitrariedad que no permite nuestro ordenamiento jurídico.
Y todo esto ha ocurrido unos días antes de celebrarse el juicio, 16 meses después de ponerme la multa. Precisamente justo después de que el juzgado haya aceptado una serie de preguntas que el Ayuntamiento debía contestar por escrito y unos requerimientos de información que debía aportar. Hacen un requiebro (una cobra) administrativa para evitar responder a esta sencilla pregunta: ¿Es cierto que el Ayuntamiento, a través de sus ordenanzas municipales, permite la circulación en bicicleta en zonas peatonales cuando la concurrencia de personas así lo permite?
A las 52 personas multadas por este motivo en Bilbao desde el 17 de junio de 2023, según lo publicado por el Área de Seguridad en febrero de este año, seguro que también les interesa conocer la respuesta. Como a mí, también les sancionaron por infracción grave, cuando la nueva Ley de Tráfico no lo permite.
En este viaje me he encontrado con Biziz bizi, asociación de ciclismo urbano de Bilbao, como apoyo. Hemos lanzado una encuesta para conocer otros casos similares al mío. Personas multadas por ir en bici por zonas peatonales y así poder denunciar colectivamente esta situación. Ayudadnos a difundirla.
Porque, en definitiva, ¿de qué va verdaderamente el discurso de apoyo a la movilidad urbana sostenible si multan a un padre por ir con sus hijos en bici por un parque para luego quitarle la multa 16 meses después solamente porque ha sido capaz de recurrirla en un juicio?
¿Por dónde íbamos? Ah, sí, me habían puesto una multa por ir en bici con mis hijos, menores de edad, por un parque de Doña Casilda semivacío y estaba a punto de presentar mis alegaciones.
El Órgano sancionador competente por razón de la materia, en función de los datos, antecedentes y circunstancias existentos en el expediente administrativo debidamente comprobados, en ejercicio de las atribuciones que le corresponden, ha dictado la siguiente: RESOLUCIÓN
1º.- DESESTIMAR las alegaciones presentadas en el expediente sancionador de referencia por la persona interesada, en razón de las siguientes consideraciones:
El artículo 121.5 del Reglamento General de Circulación establece que la circulación de toda clase de vehículos en ningún caso deberá efectuarse por las aceras y demás zonas peatonales.
El párrafo quinto del artículo 21 de la Ordenanza de Espacio Público de Bilbao señala que los y las menores de 12 años, bajo la exclusiva responsabilidad de las personas que ostenten su patria potestad, podrán utilizar las zonas peatonales, plazas y parques de Bilbao, para circular en bicicleta, monopatín, patines y similares cuando el número de personas concurrentes en dichos espacios lo permita. En el caso que nos ocupa, la circulación con la bicicleta se realizó por una persona mayor de 12 años, no concurriendo por tanto, la excepción preceptuada en el referido artículo.
La referencia que el artículo 21 realiza a la utilización de bicicletas y otros elementos de desplazamiento fuera de las zonas habilitadas al efecto, cuando la concurrencia de personas así lo permita, refiere únicamente a zonas peatonales en sentido estricto, no entendiendo por éstas las plazas y parques de Bilbao.
2.- Enviadas las alegaciones al agente denunciante de conformidad con lo establecido en el art. 95.2 del RDL 6/2015 de 30 de octubre, las ha desestimado ratificándose en los términos de la denuncia.
2º.- ESTIMAR por el organo instructor no necesaria la apertura de período de prueba y audiencia en los términos previstos por el artículo 13 del R.D. 320/1994, por el que se regula el Reglamento del procedimiento sancionador en materia de Tráfico, Circulación de vehículos a motor y Seguridad Vial, para la averiguación y calificación de los hechos o para la determinación de las posibles responsabilidades, por haber resultado debidamente constatados los hechos denunciados en la fase instructora del expediente sancionador.
A los efectos procedentes, el órgano instructor pone a disposición de la persona interesada para su examen el expediente sancionador en las dependencias del Área.
Ahora voy a impugnar esta desestimación mediante Recurso contencioso-administrativo ante el Juzgado de lo contencioso-administrativo del Tribunal Superior de Justicia del País Vasco.
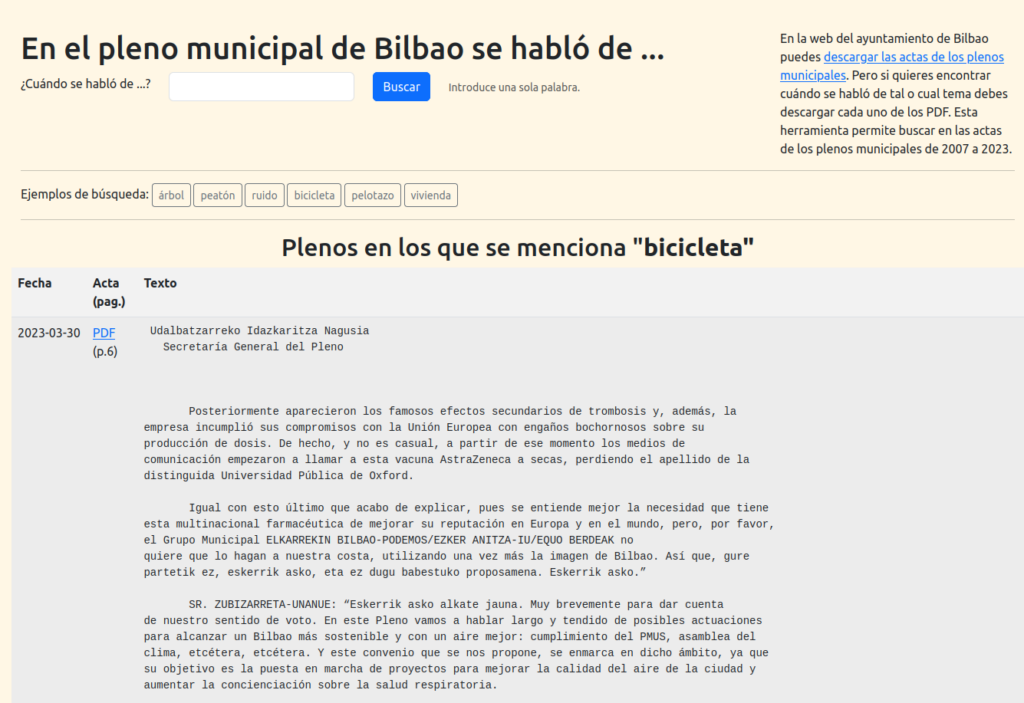
0. ¿De verdad no hay una forma sencilla de buscar en las actas de los plenos municipales?
Te ha pasado. Bueno, hagamos como si te hubiera pasado.
Quieres saber cuándo, en el pleno de tu ayuntamiento, han hablado de tal o cuál tema. Vas a la web del ayuntamiento y tras un rato navegando encuentras la página ¡bingo!
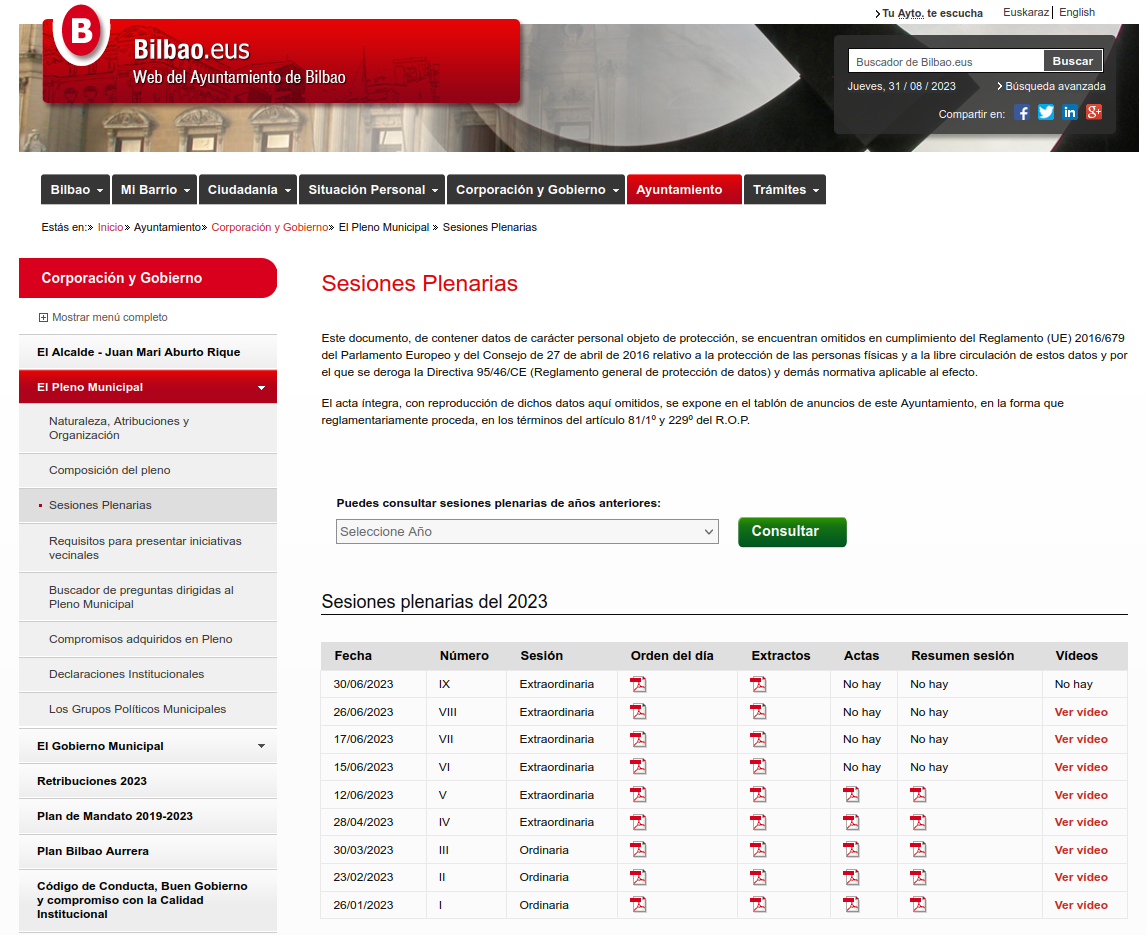
Una URL maravillosamente larga: https://www.bilbao.eus/cs/Satellite?c=Page&cid=3000015482&language=es&pageid=3000015482&pagename=Bilbaonet%2FPage%2FBIO_ListadoSesionesPlenarias. Puedes acceder a las actas en PDF. Todo bien.
Basta ahora con descargarlas una a una, abrir cada documento y buscar. Puede resultarte algo tedioso. Lo haces para el 2023, pero cuando llegas a 2022 ya te cansas ¿no existe una manera mejor para poder buscar en todas las actas? Y si las tuvieras descargadas ¿cómo buscar en todas ellas?
En la web del ayuntamiento hay disponibles actas de los plenos desde noviembre de 2007, pero descargarlas todas te llevaría más tiempo del que dispones. Son 193 a día de hoy (y eso sin contar con los extractos de las actas, que están disponibles desde 2002).
Las actas están ahí. Están publicadas. Cualquiera puede acceder a elllas. Otra cosa es que alguien tenga el tiempo para descargarlas y analizarlas.
¡Este es un caso para Abrir Datos Abiertos!
No es la primera vez que me pasa. Tener la información al alcance y no poder procesarla, porque no está publicada de una forma que pueda ser fácilmente consumida. Requiere demasiado trabajo.
Así que me puse manos a la obra.
Lo primero es 1) obtener la lista completa de actas; luego 2) descargar todos los PDF; y por último3) procesar todos los textos para poder hacer búsquedas.
1. Scraping
Para lo primero hace falta “escrapear” (de scraping, en inglés), esto es, descargar sistemáticamente la información de la web. Para ello le pregunté a Ekaitz si se le ocurría algo, porque el escrapeado no era imposible, pero tampoco trivial. En unas horas me mandó este código de python, que sirve para genera un archivo JSON que contiene la lista y URL de todos los documentos para poder descargarlos:
# Copyright 2023 Ekaitz Zárraga <ekaitz@elenq.tech>
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import requests
from bs4 import BeautifulSoup
from urllib.parse import urlparse, urljoin
import json
if __name__ == "__main__":
base_url = urlparse("https://www.bilbao.eus/cs/Satellite?c=Page&cid=3000015482&language=es&pageid=3000015482&pagename=Bilbaonet%2FPage%2FBIO_ListadoSesionesPlenarias")
r = requests.get(base_url.geturl())
soup = BeautifulSoup(r.text, "html.parser")
years = { i.text: i["value"] for i in soup.select("select#anioId option[value]") if i.text.isdigit()}
data = []
for year, id in years.items():
r = requests.post(base_url.geturl(), {"anioId": id})
soup = BeautifulSoup(r.text, "html.parser")
table = soup.find('table', class_='tablalistados')
headers = [ th.text.strip() for th in table.find("tr").find_all("th") ]
data_rows = table.find_all("tr")[1:]
print(year)
for data_row in data_rows:
line = { k: v for k, v in zip(headers, data_row.find_all("td"))}
line["Fecha"] = line["Fecha"].get_text().strip()
line["Número"] = line["Número"].get_text().strip()
line["Sesión"] = line["Sesión"].get_text().strip()
# Los que tienen archivo: guardar enlace (luego se puede hacer un GET)
for field in ["Orden del día", "Actas", "Resumen sesión", "Extractos", "Vídeos"]:
link = line[field].find("a")
url = urlparse(urljoin(base_url.geturl(), link["href"])) if link else None
line[field] = url.geturl() if url else None
data.append(line)
with open("plenos.json", "w") as f:
f.write(json.dumps(data))¡
2) Descargar los PDF
Para eso me fui a R, que es donde me encuentro más cómodo para trastear. Este archivo de R lee el JSON descargado, descarga todos los PDF y genera un archivo CSV en el que en cada línea guarda: el texto contenido en una página de cada PDF, el número de página, la URL al PDF original del acta y la fecha del pleno municipal.
# Cargar librerías
library(tidyverse)
library(pdftools)
library(tm)
library(rjson)
# Genera archivo .json con el código de plenos.py
# Archivo descargado plenos_230823.json
# Segundo archivo, en vista de que han cambiado las URL
data <- fromJSON(file= paste0("data/original/plenos_230823.json") )
# Apana (flat) el archivo json para operar más fácilmente --------
for( i in 1:length(data) ) {
print(i)
# for( i in 1:2 ) {
fecha <- data[[i]]$Fecha
num <- data[[i]]$Número
sesion <- data[[i]]$Sesión
orden <- data[[i]]$"Orden del día"
extractos <- data[[i]]$Extractos
actas <- data[[i]]$Actas
resumen <- data[[i]]$"Resumen sesión"
video <- data[[i]]$Videos
if( is.null(orden) ) { orden = NA }
if( is.null(extractos) ) { extractos = NA }
if( is.null(actas) ) { actas = NA }
if( is.null(resumen) ) { resumen = NA }
if( is.null(video) ) { video = NA }
if ( i == 1 ) {
plenos <- data.frame(fecha = fecha, num = num, sesion = sesion, orden =orden, extractos = extractos, actas = actas, resumen = resumen, video =video)
} else{
plenos <- rbind( plenos,
data.frame(fecha = fecha, num = num, sesion = sesion, orden =orden, extractos = extractos, actas = actas, resumen = resumen, video =video)
)
}
}
# Format date (pon en formato fecha)
plenos <- plenos %>% mutate(
fecha = as.Date(fecha, format="%d/%m/%Y")
)
# Descarga los PDF - Download ----
for( i in 1:nrow(plenos) ) {
# for( i in 1:22 ) {
print(plenos$actas[i])
if ( !is.na(plenos$actas[i]) ) {
print(plenos$fecha[i])
#Descarga el archivo
download.file(plenos$actas[i],
paste0("data/output/actas_230823/",plenos$fecha[i],"_acta_pleno-municipal-bilbao.pdf"))
}
}
# Read pdf -------
# Guarda el resultado de cada página en una celda, junto con fecha y número de página
for( i in 1:nrow(plenos) ) {
print( paste(i,"fila"))
print(plenos$fecha[i])
if ( !is.na(plenos$actas[i]) ) { # Que exista el acta
text <- pdf_text(paste0("data/output/actas/",plenos$fecha[i],"_acta_pleno-municipal-bilbao.pdf"))
if ( i == 5 ) { # TODO: Para el primer pleno que tiene acta (metido a mano, mejorar!) en este caso el 5
for( j in 1:length(text)) { # itera por todas las páginas de cada pdf
print( paste("row:", j, " ----------------------------------"))
if( j == 1) { # Para la primera iteración
print("j es 1")
all_pages <- text[j] %>% as.data.frame() %>% rename( txt = 1) %>% mutate(
pag = j,
fecha = plenos$fecha[i],
actas = plenos$actas[i]
)
} else (
page = as.data.frame(text[j]) %>% rename( txt = 1) %>% mutate(
pag = j,
fecha = plenos$fecha[i],
actas = plenos$actas[i]
)
)
if( j != 1) {
all_pages = rbind(all_pages, page)
}
}
} else {
for( j in 1:length(text)) { # itera por todas las páginas de cada pdf
if( j == 1) {
print("4")
all_pages_temp <- text[j] %>% as.data.frame() %>% rename( txt = 1) %>% mutate(
pag = j,
fecha = plenos$fecha[i],
actas = plenos$actas[i]
)
} else (
page = as.data.frame(text[j]) %>% rename( txt = 1) %>% mutate(
pag = j,
fecha = plenos$fecha[i],
actas = plenos$actas[i]
)
)
if( j != 1) {
all_pages_temp = rbind(all_pages_temp, page)
}
}
all_pages = rbind(all_pages, all_pages_temp)
}
} else {
print("No existe acta")
}
}
# salvar archivo como CSV
write.csv(all_pages, "data/output/paginas-actas-plenos_230823.csv")
3. Página para buscar
A partir del CSV generado en el paso anterior monte un buscador básico (sólo se puede buscar por una palabra) desarrollado en PHP (ver código):
¿Qué le sobra, qué le pasa, qué le falta a esta web? ¿os resulta útil? ¿cómo podíais vivir sin ella? ¿encontrais algo interesante? Encantados de escucharos.
Me acaban de poner multa por ir con mis hijos en bici por el parque Doña Casilda (Bilbao) el agujero negro para las bicicletas. Parque semi vacío, dos agentes a la espera del ciclistas ¿alguien sabe si hay posibilidades al recurrir la multa?
Me ha pedido la documentación y empezado a escribir la multa sin decir nada más, sin siquiera explicar qué es lo que estaba haciendo mal. Esa es la imagen que mis hijos se llevan de la policía municipal
Tras pregutarle, el agente municipal citaba la ordenanza de bicis (no existe como tal) y no era capaz de indicar qué normativa en concreto había incumplido más alla de “la ordenanza de Bilbao” y el código de circulación. Aquí las ordenanzas municipales de Bilbao. Fuente del mapa.
Apatruyando la ciudad Por el parque con su coche Apatruya la ciudad. (Así estaban los policías minutos después de multarme)
Facilitar el acceso y búsqueda a las ordenanzas municipales
A raíz de la multa por ir en bici por un parque (y ante la imposibilidad de buscar en la web del Ayto. de Bilbao qué normativa trata sobre bicicletas y/o zonas peatonales) he montado esta web para buscar en las ordenanzas. Es un ejercicio rápido de transparencia para abrir datos (que deberían) ser abiertos.
Tuve que pasar las ordenanzas de PDF a html. En un caso tuve que hacer OCR (reconocimiento de caracteres en imágenes) porque la ordenanza estaba publicada como imágenes escaneadas. En otro casono pude usarla porque el link al PDF de la ordenanza daba error.
Como prueba de concepto de lo que debería ser una web municipal creo que vale.
Dejo anotado aquí el cómo se hizo, casi todo desde línea de comandos:
Un script en R para descargar todos los PDF.
Con el comando pdftohtml convierto los PDF en html. Algunos los tengo que limpiar ya que tienen demasiadas imágenes repetidas. Además, en la página no usaré imágenes. Lo hago con “sed -e ‘s/]*>//g’ input.html > output.html”
En el caso de la ordenanza del Casco Viejo no se puede copiar el texto, son imágenes: 3.1 Convertir PDF a imágenes con pdftoppm 3.2 OCR con tesseract con loop “for i in casco-??.png; do tesseract “$i” “text-$i” -l eng; done;” 3.3 Unir los textos “cat text-casco-*.png.txt > fin.txt” 3.4 Sustituyo los múltiples espacios juntos que genera tesseract “ ” por ” “.
Abro el html generado de cada ordenanza en navegador y copio el contenido y lo pego en una página de wordpress (una página por ordenanza). Cambio de fecha de la página a fecha de aprobación.
Retoques en wordpress mínimos y resaltar buscador.
Borrador de alegaciones
Publiqué en Twitter todo esto y con las sugerencias recibidas (y la ayuda de Bizi Bizi Bilbao) publiqué este borrador y recopilación de información para escribir las alegaciones. Pronto publicaré las alegaciones finales y actualizaré este post. El documento compartido también incluye una recopilación de toda la normativa aplicable en mi caso.
Esto no lo hago por mi solamente, para no pagar la multa, sino para que se reconozca que las bicis sí podemos circular por espacios peatonales.
Well, I know you are not going to read the entire PhD thesis and annexes, so I am publishing it little by little, chapter by chapter. I am transforming the content to html, so I can use all the hyperlinks features and make it easier to navigate. It will take months, but I’ll complete the job.
I’ve created a page that is a summary of all the extra content of the dissertation: Color of corruption. Visual evidence of agenda-setting in a complex mass media ecosystem submitted on December 2022 and defended successfully on June 2023.
I’ve already uploaded all the code for the data gathering and analysis as well as the data bases that I’ve used.
I haven’t posted as much as I wanted to tell what I was doing, but I hope this page will help introduce what I’ve been doing. It’s been a long very long journey.
A visual analysis of all the pages of the PhD dissertation.
PS: In the past I’ve also published my research online, see these two examples. The goal was to publish the process, not only the final results, and make them available for everyone else: