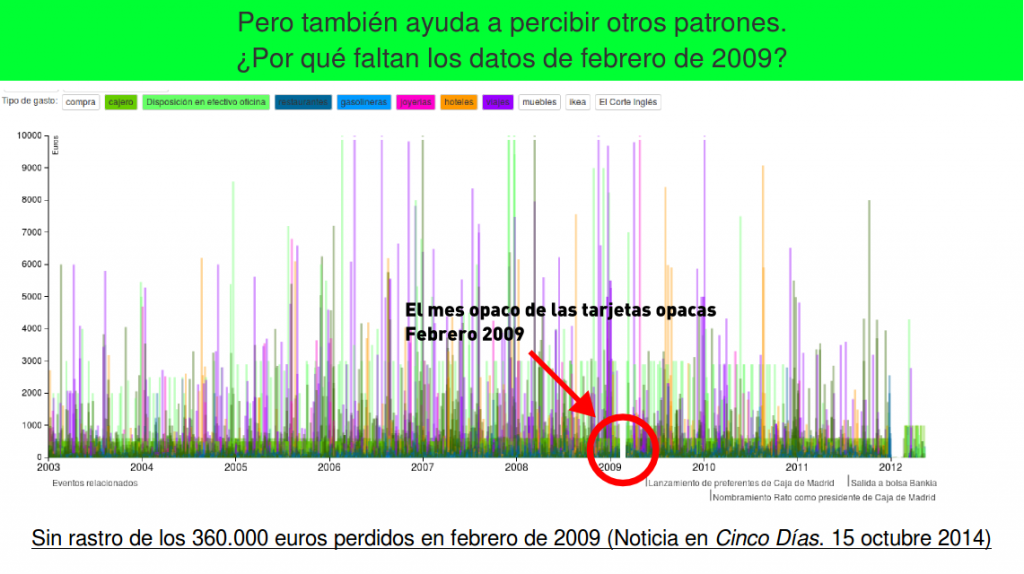
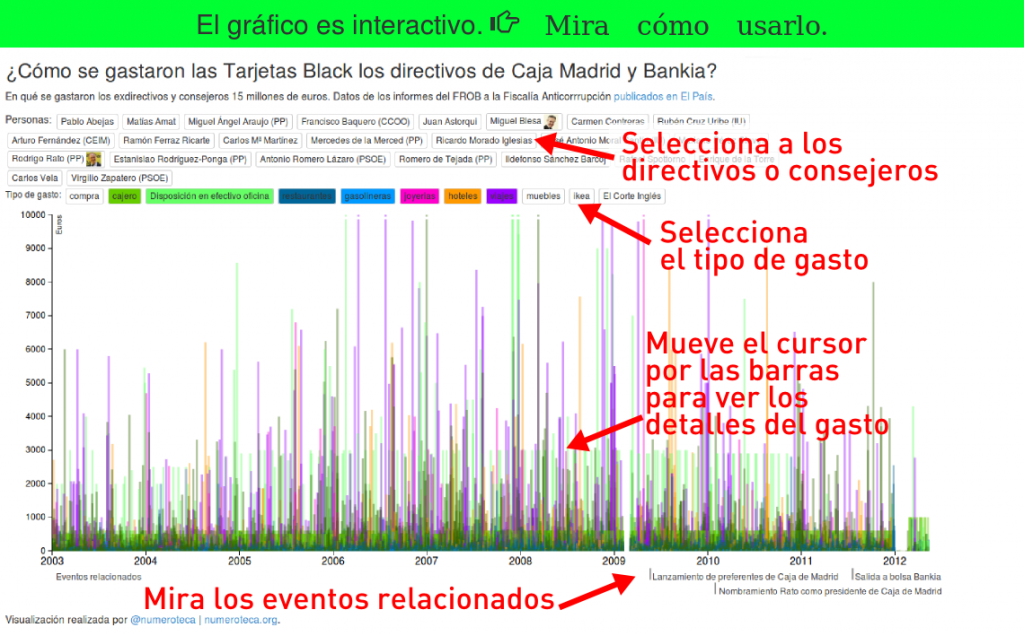
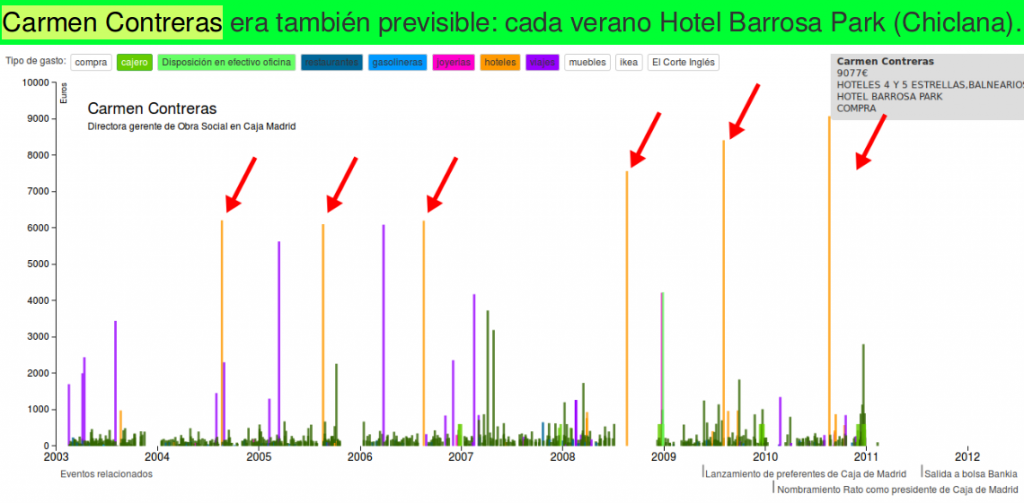
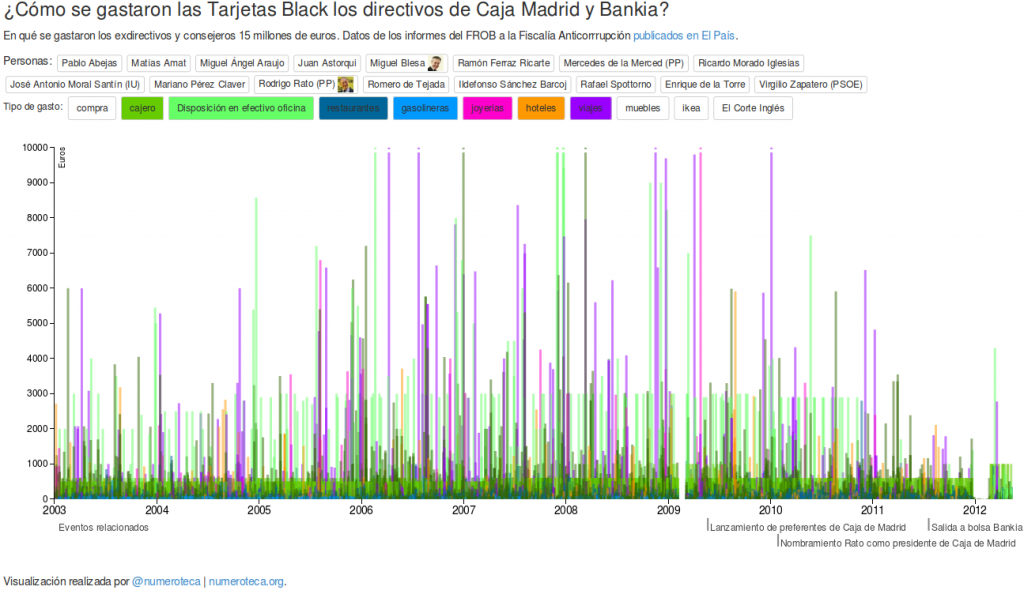
‘infans, infantis’ (in-fans) en latín significa literalmente ‘el-que-no-habla’ (participio presente del verbo ‘fari’= hablar, con el prefijo negativo ‘in’). Por eso se aplica a los niños pequeños o, en el ejército, a los infantes, que se limitan a obedecer y luchar, sin rechistar.
Vía Veterodoxia
Hace unas semanas escribí una crítica literaria sobre el auto del juez Castro que imputaba a la Infanta Cristina: Un auto para la hija del rey. Fascinado por el texto y el contenido, pensé que la mejor manera de compartirlo con el mundo era escribir un comentario de texto que sirviera de resumen e introducción para aquellos que no tuvieran tiempo para leer las 227 páginas que lo componían. El relato tuvo en general buena acogida. Alguno, emocionado con el texto, me pidió una segunda parte de “Un auto para la hija del rey”; otros me hicieron notar que no había cosa de qué sorprenderse: más o menos todos los autos judiciales tienen esa intertextualidad literaria o esa mezcla de voces que a mi me fascinaba.
En cualquier caso llegó la esperada declaración de la infanta el 8 de febrero de 2014.
Me dispuse a leer el interrogatorio a la Infanta como si de una pieza de arte dramático, o de improvisación teatral se tratara[ref]No podemos juzgar la calidad de los intérpretes ya que quedó prohibida la publicación de la grabación del audio de la declaración.[/ref], siguiendo el juego de analizar como literatura textos que no lo son. El resultado de la declaración ante el juez produjo una obra de muy baja calidad literaria, pero de todo se puede aprender ya que bien es sabido que “no hay libro tan malo, (…) que no tenga algo bueno”. A veces ver películas malas permite apreciar cómo de buenas son las buenas, donde no se ve cómo que están hechas o no se da uno cuenta de los trucos de cámara o el vestuario.
El interrogatorio fue por los derroteros que se esperaban: la INFANTA dijo desconocer, no recordar o no saber casi de nada. No sabía lo que hacía su marido con las empresas e instituciones con las que trabajaba (Aizoon, Instituto Noos), no sabía que en la primera planta de su vivienda estaba oficialmente la empresa Aizoon, no sabía qué hacía el servicio doméstico en su casa, no sabía que se había autoalquilado su propia casa, no sabía de dónde venía el dinero que se gastaba, no sabía de derecho tributario ni tenía conocimientos jurídicos, no leía los papeles que firmaba. Como muchos medios de comunicación han señalado, usó evasivas en cientos de preguntas para quedar ajena a los negocios y actividades de su marido. Puede que en este caso los guionistas (o dramaturgos) que prepararon con ella esta improvisación buscaran en la repetición un efecto artístico. Otras artes son ricas en este tipo de repeticiones (la nota repetida en Le gibet de Ravel, la misma imagen serigráfica en los cuadros de Warhol) y no se perciben como negativo o van en detrimento del autor, sino todo lo contrario. En un caso como este, que la INFANTA recurra a repetir 182 veces “no lo sé”, 55 “no lo recuerdo” y 52 “lo desconozco” habla mal de su capacidad de improvisación o de su equipo de guionistas[ref]Hay también ejemplos nefastos y aburridos de repetición en la cultura pop, como las insufribles canciones “Revolution Number 9” de The Beatles y “Bugs” de Pearl Jam.[/ref].
Sin embargo los problemas del personaje INFANTA Cristina no acaban ahí. Además de su monotonía, el personaje resulta poco creíble. Por decirlo de otra forma, se ve el cartón con los que se han preparado los diálogos y la psicología del personaje, no hay profundidad y riqueza, parece un personaje de ficción mal dibujado. Como en los cuentos infantiles o en muchas malas series de televisión: los malos son malos, los buenos son buenos y los tontos son tontos. En la vida real, y en el buen teatro, todo es algo más complejo.
La primera reacción es acusar al guionista que ha definido la personalidad del personaje, pero se ha quedado en caricatura. Por las respuestas de la INFANTA podemos reconstruir los mimbres con los que se había construido al personaje: mujer trabajadora, profesional, encargada de sus hijos, confía ciegamente en su marido, delega a su marido los asuntos económicos, algo tonta. Mejor leerlo de sus propias palabras, cuando contesta a su propio guionista, digo, al ABOGADO de la defensa: “yo me ocupaba de los niños, de sus actividades, de la escuela y de todo lo que tenía que ver con ellos, con médicos y demás, y mi marido se ocupaba de toda la parte de los gastos”. Pero claro, el relato de esta mujer ocupada en los asuntos del hogar choca con que sabemos que es la hija del Rey de España, que asiste a unos 100 actos de protocolo anuales y que trabaja como directora del área internacional de la Fundación La Caixa. Como aclara en otro momento del interrogatorio, se “marchaba por la mañana y volvía por la tarde-noche y a veces tenía que dormir fuera, y no estoy las 24 horas en casa”. No es que no se pueda ser profesional de alto nivel de día y madre amantísima de sus hijos por la noche, lo que resulta más inverosímil es sumar a la historia de este personaje su total desconocimiento en los asuntos económicos que le atañen. El personaje de una directora de área de una de las fundaciones privadas más importantes de España, que cuenta con un asesor personal para sus asuntos fiscales, hace aguas si se afirma que no sabe nada sobre su propio dinero o que no planifica el dinero que tiene para gastar. En ficción todo es posible, pero el principio de verosimilitud ha de respetarse para que el lector pueda creer la historia. Podemos echar la culpa a los guionistas o a la improvisación y los nervios; me inclino más por lo primero.
Por otra parte, la actriz que encarna a la INFANTA, que es ella misma, no está exenta de responsabilidad en este desastre teatral. En su pre-guion, lo que imaginamos que es un guion para una sesión de improvisación, probablemente venía escrito algo como “Decir que no controlo nada de Aizoon, que no llevé cuentas, que no he controlado gastos, que no tengo nada que ver”. Pues bien, llevado a la literalidad hace que el actor o actriz repita esas mismas palabras y se vea el pastel. Algo así le ocurrió a María Teresa Sáez en la comparecencia de la comisión de investigación del Tamayazo en la Asamblea de Madrid, cuando, interrogada por un diputado, contestó el famoso “no a todo”, lo más seguro porque dijo al aire lo que su abogado le susurraba al oído (“tú di que no a todo”). De un modo similar, y aconsejada previamente por sus guionistas, la INFANTA respondió hasta casi veinte veces seguidas de forma monótona con la expresión “no controlo”, algo rara en castellano para referirse a una empresa:
“no estaba yo en el día a día de Aizoon, no controlaba Aizoon”
“no tengo poderes en Aizoon ni tengo ningún control sobre Aizoon”
“nunca he controlado ni he gestionado nada de Aizoon”
“nunca se lo he preguntado, ni he controlado Aizoon, ni sé cómo han ido las cosas”
“no he controlado los gastos de Aizoon, ni he controlado las cuentas”
“no he entrado en los gastos, no tengo control sobre Aizoon, ni lo he tenido y no sé cómo se han hecho las cosas”
“no he controlado Aizoon”
“ya le digo que yo no he controlado”
“no tengo control sobre Aizoon”
“no he controlado Aizoon”
“no he controlado Aizoon”
“no sé, no controlo Aizoon”
“no he controlado Aizoon y por lo tanto no sé cómo se han realizado los gastos”
“no he controlado, yo no lo he hecho y siempre me he fiado de mi marido y sus asesores”
“no he tenido control sobre Aizoon, ni sé lo que se ha hecho”
“he tenido ningún control sobre las cuentas ni nada con, nada que ver con Aizoon”
“nunca he llevado el control de los gastos de Aizoon”
“nunca he tenido nada que ver con la gestión, ni con el control de Aizoon.”
sobre todo si se es propietario de esa empresa, Aizoon, al 50% por ciento. En cualquier caso, y aunque no se puede culpar únicamente a la INFANTA puesto que el JUEZ a través de sus preguntas también contribuyó a la monotonía, en una improvisación los actores tienen que cuidarse de no caer en este tipo de repeticiones dado que suelen aburrir al público. La repetición como recurso dramático puede ser usada convenientemente, como hacen muchos humoristas que repiten sus gags y muletillas hasta la extenuación, o como la genial escena de la serie The Wire donde dos detectives resuelven un asesinato y la única palabra que repiten hasta casi cuarenta veces es fuck y sus derivados. En una improvisación de acto único es más difícil que funcione.
Otro ejemplo de mala construcción del personaje puede observarse en la insistencia de la INFANTA en demostrar que no tiene nada que ver con Aizoon, que resulta algo descarada en las formas:
INFANTA: Mi marido me lo propone y con la confianza que le tengo, yo lo acepto, crea Aizoon para canalizar sus ingresos profesionales y a partir de ahí yo no he tenido nada más que ver, ya lo ha llevado él, yo no he intervenido en nada. (…)
INFANTA: Señoría, no recuerdo haber tenido ningún debate, a mí mi marido me pregunta si quiero ser socia al 50% y yo lo acepto y no hay nada más. (…)
INFANTA: Señoría no había una sociedad pantalla, y mi marido yo confío en él y en su buen quehacer, no puedo decir nada más. (…)
INFANTA: (…)nosotros en ese momento podíamos hacer frente a esta casa, era nuestra ilusión como proyecto familiar y en ese momento, nosotros no tenemos ni segundas residencias, ni colecciones de nada, ni… bueno, pensamos que podría ser nuestro proyecto como familia, y no hay nada más. (…)
INFANTA: Señoría no me consta que hubiese ningún revuelo, no lo sé, pero yo ceso como vocal, sí, porque así nos lo sugieren y nada más.
La repetición del “nada más” suena demasiado enfática. De tanto insistir en ella, el público puede llegar a entender que el personaje oculta algo, que involuntaria y negligentemente está revelando que en efecto “hay algo más”.
Queda la gran pregunta: ¿por qué los guionistas deciden pintar a un personaje tan plano y poco creíble como el de la INFANTA? Probablemente porque estén deseando que este capítulo piloto no tenga continuidad, cobrar sus honorarios e irse a casa. Cuando preparar un capítulo piloto no sale de corrido, mejor cerrar antes de abrir. Además, trabajar con un personaje del star system sin experiencia en la actuación no debe ser tarea sencilla.
Pero claro, tomar a los guionistas de la INFANTA por ineptos parecía algo torpe por mi parte: ¿no son uno de los mejores bufetes de guionistas de España? Es como si hubieran tomado la decisión de presentar a la INFANTA como alguien que no se entera de nada para luego poder eximirla de toda culpa. Estaba a punto de cerrar este apartado pero algo no me encajaba. Una segunda y tercera lecturas me revelaron la verdadera trama. Puede que la INFANTA se presentara como una mujer muy trabajadora, dedicada a sus hijos y totalmente despreocupada de los asuntos económicos familiares, pero ¿cómo explicar que no leía lo que firmaba, que no sabía lo que hacía?
FISCAL: No ha cuantificado a cuantas fundaciones pertenece, ¿se acuerda?
INFANTA: No, pero más de cien yo creo.
¡Muy fácil! La respuesta es obvia (como tantas soluciones una vez formuladas, que sin embargo no lo eran antes de que se le ocurrieran a alguien): la INFANTA, al pertenecer a más de cien fundaciones, patronatos y comisiones, no tiene control sobre cómo aparece su nombre en cada una de ellas, no tiene control sobre la forma en que aparece en cada una de ellas, no tenía control sobre cómo aparecía su nombre y cargo en el Instituto Noos cuando era vocal o sobre lo que hacía la empresa Aizoon de la cual era propietaria al 50%.
INFANTA: Sí, el mío, me lo trajeron, me debieron traer a la firma, y lo firmé, pero no, sin asistir a ninguna junta. (…)
INFANTA: Yo firmé donde me dijeron los asesores que tenía que firmar, no, debió ser un error, no lo sé, porque yo no tengo poderes en Aizoon ni tengo ningún control sobre Aizoon, entonces no entiendo porqué firmé ahí. (…)
INFANTA: Y la firmo, por confianza de la persona que me la presenta, sí.
INFANTA: Sí, pero no recuerdo haber firmado actas, pero si me traen algo a la firma, a la persona que tengo confianza, lo firmo, sí. (…)
INFANTA: No lo recuerdo, yo sé que me lo trajeron a la firma. (…)
INFANTA: Sí, si yo firmé es porque una persona de confianza, mi marido o el asesor, me dijeron que firmase ahí. (…)
INFANTA: Si me los trae persona de confianza de mi departamento o así, pues los firmo en aras del tiempo, y si tengo confianza, ya le digo si tengo confianza en la persona que me los presenta, pues los firmo, no me paro a leer todo lo que conlleva.
Por eso, para ella firmar sin leer es algo habitual en su vida como representante de la familia, la Casa Real. En los últimos tiempos hemos visto otras tácticas similares, si no puedes negar que lo firmaste, di que lo firmaste con desconocimiento, por coacción o por confianza, ¡qué poco vale una firma en estos tiempos! Dicho lo cual, lo que resulta más inverosímil, por no decir imposible de creer para el gran público, es que la INFANTA firmara sin darse cuenta un contrato ficticio de alquiler donde aparece simultáneamente como arrendadora y arrendataria. Vamos, que estampara una firma a izquierda y derecha de un mismo documento sin darse cuenta. El contrato servía para generar gastos ficticios a Aizoon y pagar menos impuestos. ¿Qué trucos de guion harán falta para explicar esta subtrama?
INFANTA: Sí, quizá me mandara estas copias, pero yo no recuerdo haberla recibido y mucho menos igual leído, porque tenía muchos otros emails, y algunos no los leía.
La misma técnica funciona para los correos electrónicos que ella recibía de su marido sobre temas de Noos: tenía tantos que o bien no los leía o no los recuerda. Da con uno de los zeitgeist de nuestra era: ¿cómo no empatizar con la INFANTA cuando todos tenemos la bandeja de entrada a rebosar y no damos abasto?
Ya vamos acabando, el autobús está a punto de salir, pero antes tengo que dar dos breves pinceladas sobre el otro protagonista: el JUEZ Castro. Su personaje tiene algo más de gracia y parece más realista, también es verdad que su papel es más sencillo y no expone nada, o casi nada de su vida privada: “recibí clases de baile hace 30 años y todavía me acuerdo”. Consciente de que la función quedará transcrita, pero sin notas que describan la escena, usa su primera intervención para dar algo de color y contar el ambiente “lamento la manifestación que hay, hemos tenido que elegir esta sala que da a la calle, porque las demaś no tenían cabida suficiente”. Su papel le permite leer la mayoría del texto, así que no le queda mucho espacio para la improvisación, salvo en alguna réplica que da muestra de su agudeza:
JUEZ: ¿Sabe usted si su marido recibió curso de Salsa y Merengue?
INFANTA: Lo desconozco.
JUEZ: Pero si lo hubiera recibido ¿lo sabría?
INFANTA: Sí.
JUEZ: Por la manera de moverse. (…).
El tono desenfadado y algo humorístico se repite en otros momentos, hasta con un poco de sorna, cuando hace mención al Rey de España:
JUEZ: (…) se está produciendo (…) un cierto retraso en el pago, me imagino que Su Majestad el Rey no les habrá apremiado con interposición de acciones judiciales ante esa situación.
INFANTA: Al final es mi padre y se fía de mi.
A continuación, el JUEZ sigue sobre el mismo tema del préstamo de 1.200.000 de euros del Rey al matrimonio de la INFANTA para la compra del palacete. Ahora se centra en el extraño caso del documento de 2005 incluido en 2004. Después de un momento de desenfado prepara el camino para una acusación velada:
JUEZ: Aquí tenemos el expediente de concesión del préstamo y hay una cosa a la que yo no le encuentro y creo que poca gente explicación, y lo pregunto por si usted puede ayudarnos. Hay un documento de 14 de junio del 2005, que está incorporado a un expediente de concesión de un préstamo del 2004. EI documento es este, mire la fecha del 2005, y aparece incorporado a un expediente del 2004. (…)Porque, podríamos pensar en un error de fechas, que alguien ha puesto 2005 donde tenía que haber puesto 2004, pero es que este modelo, esta modelación impresa, no existía en el año 2004, esto es el programa PADRE de la declaración de la renta y se elabora cada año y se pone ejercicio 2004, es decir, si hubiera sido del ejercicio anterior hubiera puesto ejercicio 2003. Por lo tanto este impreso no existía en el 2004, ¿puede usted intentar alguna explicación de porqué está este documento ahí?
INFANTA: No, lo siento Señoría no le puedo ayudar, y si es así, estaría revisado por los asesores, no tengo ni idea, lo siento, pero no le puedo ayudar porque no lo sé.
Una vez más la INFANTA no sabe nada, el JUEZ se enfrenta en solitario al error, lo paranormal o la alteración de documento público[ref]Hay muestras de situaciones similares a lo largo de todo el interrogatorio, pero comentarlas todas harían de este texto algo demasiado extenso.[/ref]. Nos quedamos con la última intervención del JUEZ en la que, por medio de una serie de preguntas a la INFANTA y a modo de cierre, responde al FISCAL, que ha usado antes palabras del propio JUEZ de un auto anterior en el que exoneraba a la INFANTA:
JUEZ: (…) Antes el Ministerio FISCAL le leyó unos párrafos y un texto, con los que usted dijo estar totalmente de acuerdo, ¿lo recuerda?
INFANTA: Sí.
JUEZ: (…) ¿Sabe usted de qué texto forman parte esos párrafos que se le han leído? Con los que estaba de acuerdo, ¿sabe de qué texto más amplio forman parte?
INFANTA: No, estaba de acuerdo con la parte que estaba señalada.
JUEZ: Forman parte de un auto que se dictó próximo a dos años (…) es obvio que usted estaba conforme, porque desestimaba una petición que se había cursado para que usted fuera citada a declarar en calidad de imputada. Un año después aproximadamente recayó otro auto, en el que se le citaba a usted, que luego no llegó a prosperar. ¿Leyó alguna parte de ese auto, que no llegó a prosperar, porque fue revocado o suspendido por la Audiencia Provincial?
INFANTA: No lo leí en su integridad, pero mis abogados han…
JUEZ: Usted en ese auto no estaría de acuerdo o sus letrados, puesto que fue impugnado y con relativo o cierto éxito. ¿Ha leído usted algún párrafo del auto de 7 de enero, por el que se la convoca precisamente para este acto?
INFANTA: He leído varios párrafos y mis abogados
JUEZ: ¿Hay alguno con el que usted esté de acuerdo o con el que no esté de acuerdo?
INFANTA: No le puedo precisar ahora con qué párrafos puedo estar de acuerdo y cuáles no Señoría.
JUEZ: Pues ya hemos terminado.
El personaje del JUEZ da muestras de su humor ácido y de un modo sutil, o no tanto, pone de manifiesto la pelea profesional con el FISCAL que ha roto su amistad de años de antigüedad. Está enfadado porque el FISCAL ha usado palabras de un auto suyo en su contra, obviando los dos autos posteriores en los que sí imputaba a la INFANTA. El JUEZ se guarda la última palabra para rebatir el desplante del FISCAL en un gesto de orgullo que ayuda a humanizar al personaje, y de paso ridiculiza un poco a la INFANTA. La INFANTA, en medio de esta batalla de titanes, responde sin mucho aplomo.
A la luz de estas últimas líneas podría interpretarse que toda la escena del interrogatorio no es más que una introducción para tratar el tema de la relación de amistad rota entre el JUEZ y el FISCAL. Puede que esta trama sea de hecho la trama principal de la obra, y no tanto la banal y previsible imputación de la hija del Rey por blanqueo de capitales y delito fiscal. Las grandes obras de arte no son lo que en apariencia muestran en su superficie: Casablanca no es una película sobre unos exiliados en busca de un salvoconducto; El club de la lucha no trata de unos chalados que se pegan entre sí y planean volar edificios. Los buenos escritores y guionistas se sirven de situaciones para tratar temas universales como la felicidad, los celos, el amor… Desde ese punto de vista la imputación de la INFANTA vendría a ser el MacGuffin y las tramas ocultas serían el amor ciego (de la INFANTA por su marido), y la amistad rota (entre JUEZ y el FISCAL). Porque, olvidando ya el acercamiento a esta declaración judicial como si fuera una pieza dramática, cabe preguntarse ¿se ha querido presentar esta imputación como el resultado del amor y la fe ciega que tiene una mujer por su marido llevada hasta sus últimas consecuencias? ¿no es la divergencia de opiniones profesionales entre dos amigos y la posterior ruptura de su amistad el principal obstáculo de este proceso de instrucción? Después de todo, parece ser cierto que no hay texto, por malo que parezca, del que no se pueda extraer algo bueno.
Ficha técnica
Duración aproximada: 6 horas.
Personajes por orden de aparición: JUEZ Castro, INFANTA Cristina, FISCAL Horrach, Abogado del Estado, Abogado Manos Limpias, Abogado Acusación popular frente Cívico Somos Mayoría, Abogado de la defensa.
Escena: mesas dispuestas en forma de U. Sillas de madera y terciopelo rojo. El público sustituye el lugar donde estarían todos los abogados. De fondo se oyen los ruidos de la protesta de la calle. No hay telón, los actores entran y salen de escena por el patio de butacas, menos JUEZ y FISCAL que no dejan el escenario en ningún momento.
–
pd: gracias a mis atentos correctores/comentadores Miguel, María, Elena, Marcus y Patricia.



")