
Muero por datos cuando la administraciones publican datos aparentemente muy detallados pero que impiden ver el bosque.
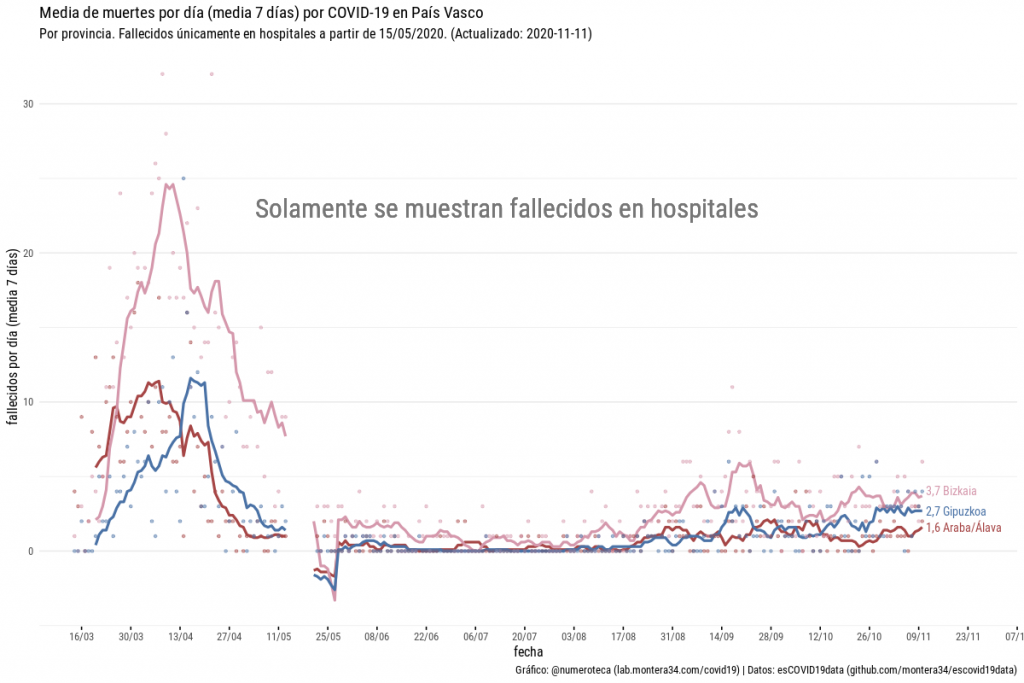
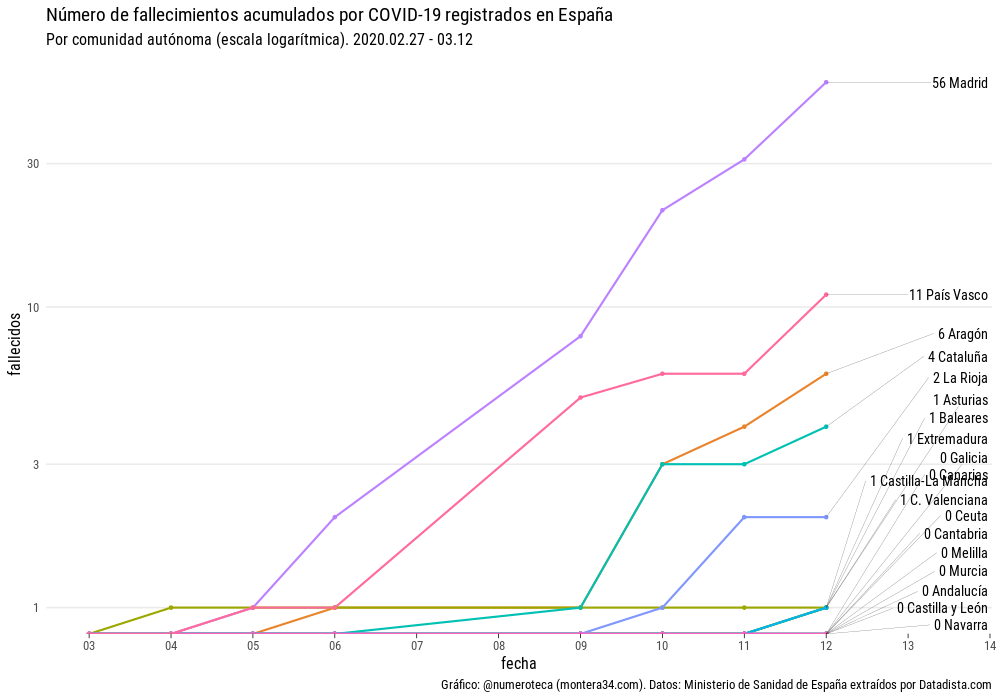
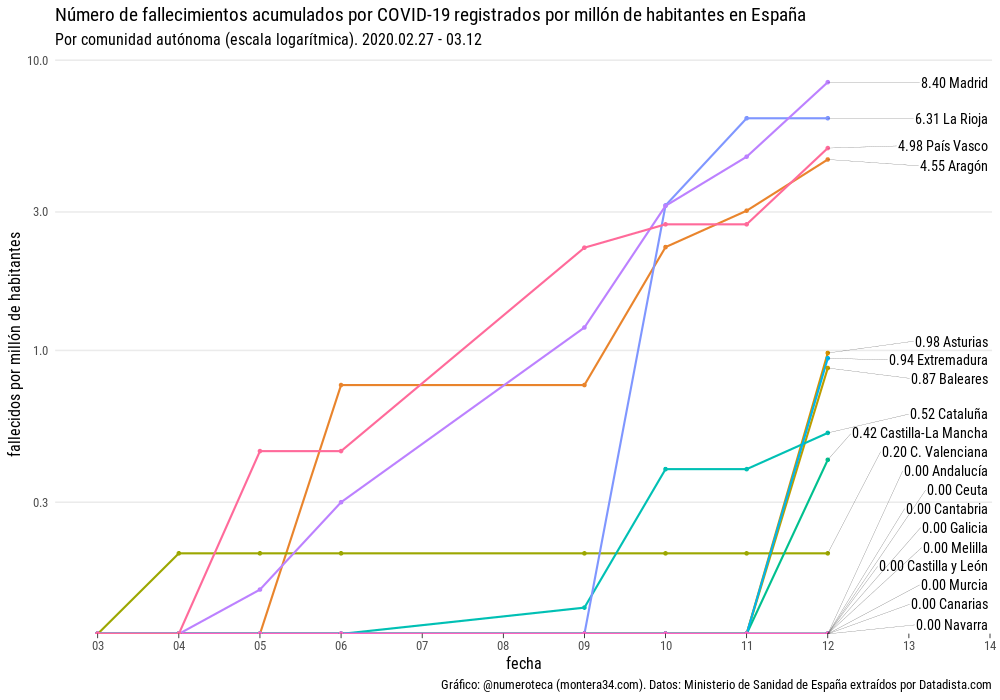
Un ejemplo lo tenemos con los fallecidos por COVID-19 en Euskadi.
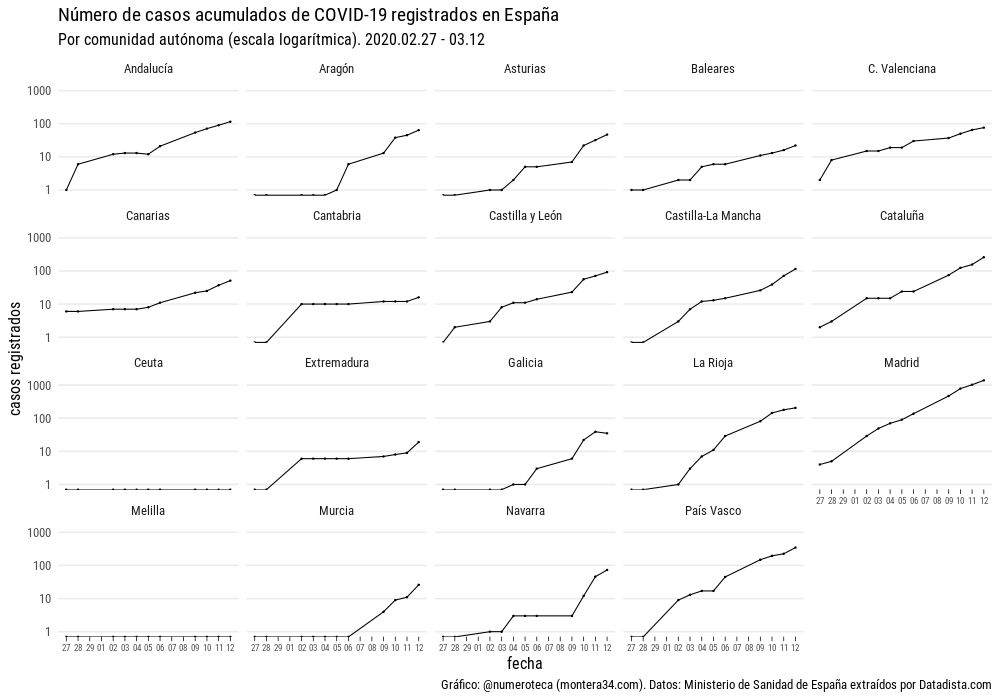
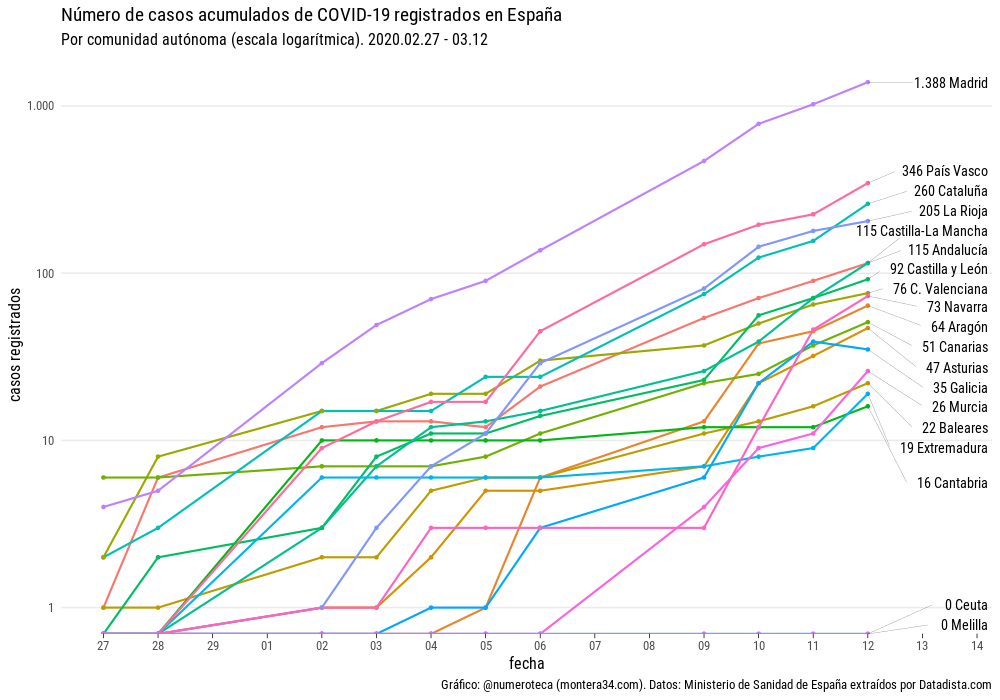
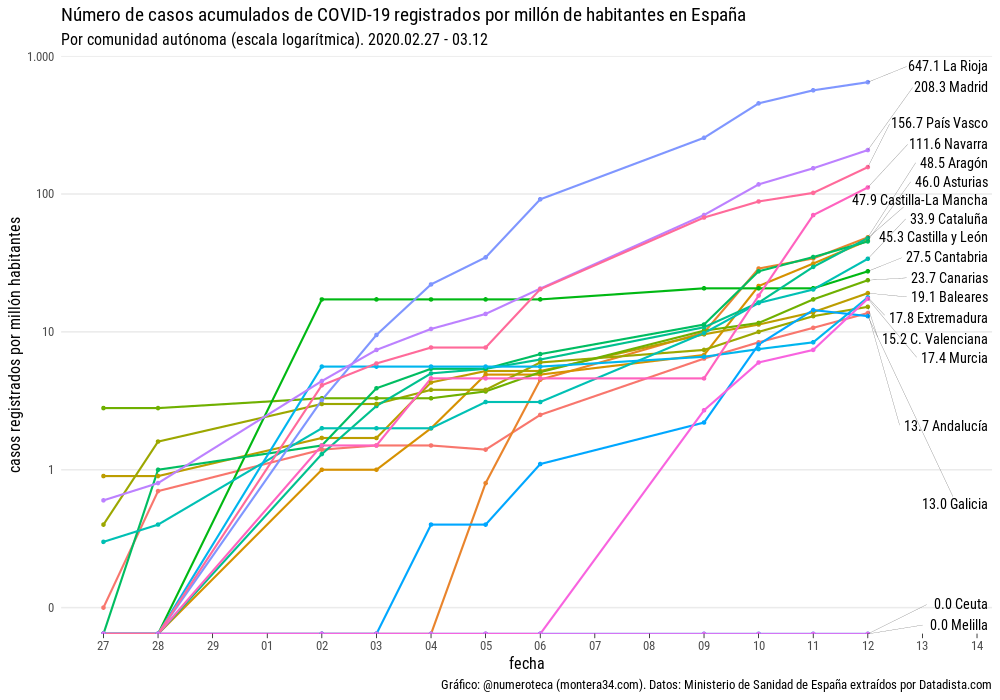
De primeras, si revisas las fuentes de datos que se publican, parece que hay muchos datos disponibles. Si miras un poco más en detalle parece imposible responder a una pregunta básica ¿cómo evolucionan los fallecidos por COVID-19 provincias en Euskadi?
Cada cuál llega con sus preguntas bajo el brazo e intentan que los datos le den la respuesta. En los medios de comunicación locales no he visto publicada la evolución de muertes por provincias.
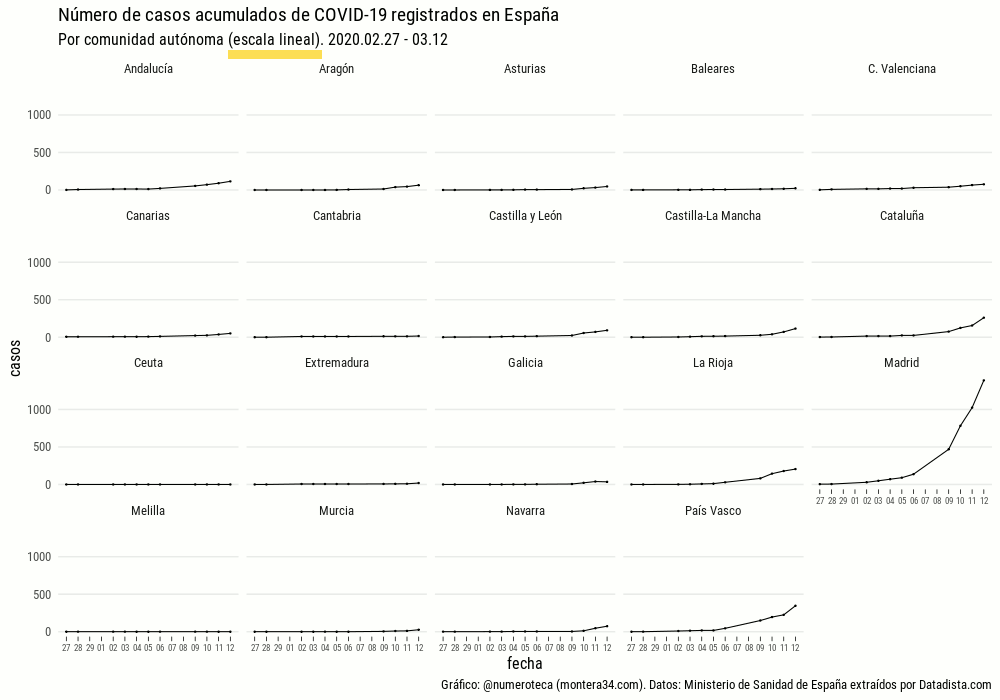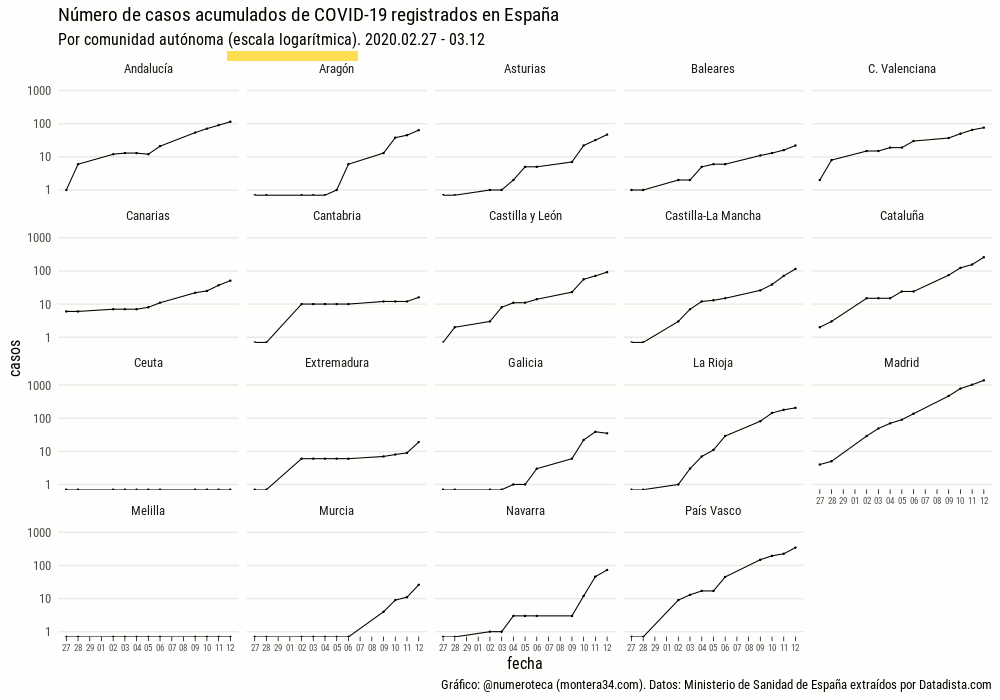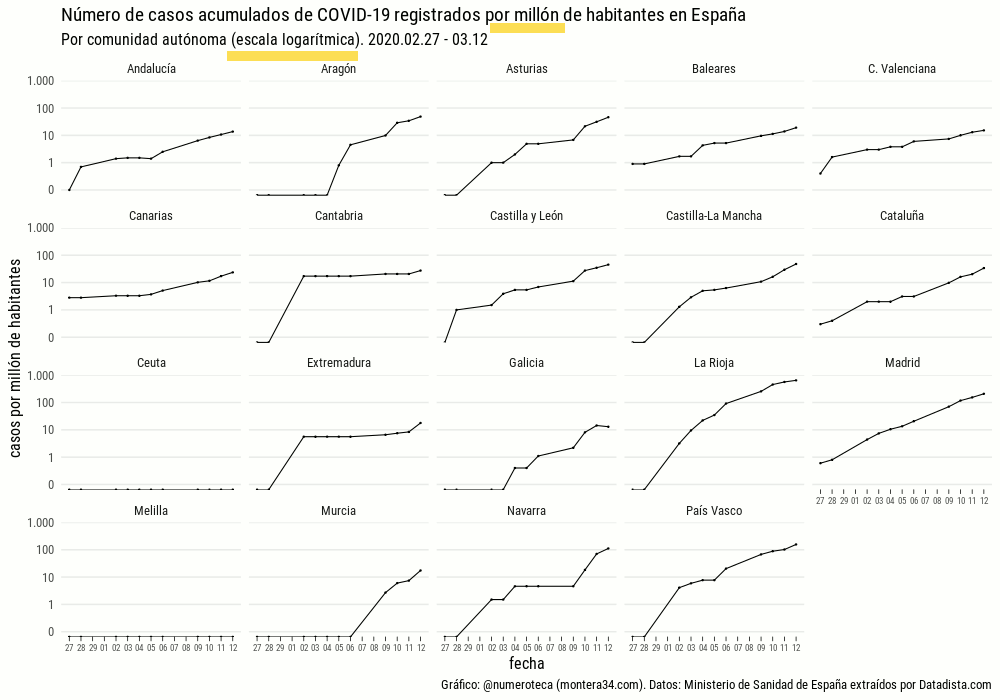
En mi caso la inquietud forma parte del proyecto de recopilación y visualicación de datos colaborativo Escovid19data, que recopila datos de 19 territorios en España.
Open Data Euskadi ofrece varias series de datos de fallecidos, pero ninguna es la que necesitamos. Este es el listado de los diferentes conjuntos de datos que ofrecen:
- Serie de fallecidos acumulados para todo Euskadi. Acumulados diarios del 24/02/2020 al 15/07/2020. Luego los datos pasan a publicarse semanalmente ¿por qué? Última fecha disponible 25/10/2020. Hace 16 días.
- Serie de fallecidos diarios para todo Euskadi: “Casos positivos fallecidos en Euskadi por fecha de fallecimiento”. Datos diarios del 01/03/2020 al 01/11/2020 (hace 9 días). [2.212 acumulados]
- Serie de fallecidos diarios por hospitales en Euskadi. Datos diarios del 01/03/2020 al 08/11/2020 desagregados por hospitales y el total diairo [1.528 acumulados].
- Acumulados de fallecidos en cada municipio de Euskadi. No se ofrece la serie de datos temporales, se da el dato de la última fecha disponible con periodicidad semanal. Última fecha disponible 2020/11/01, hace 10 días.
Este último conjunto de datos es el que nos puede proporcionar la serie temporal de fallecidos por municipio y, por tanto, por provincia, si los agregamos convenientemente. Solamente podremos reconstruir la serie temporal si antes hemos ido descargando los archivos semana a semana. (El histórico de archivos publicados por Open Data Euskadi solamente está disponible desde el 20 de octubre 2020. Es buena noticia pero insuficiente para nuestro propósito).
Por suerte, en Escovid19data, hemos descargado el archivo situacion-epidemiologica.xlsx todos los días que ha sido publicado, así que en nuestro repositorio de git tenemos el histórico completo.
Con un script de git es posible obtener todas las versiones de un archivo y poder reconstruir la serie temporal.
Esperamos que Open Data Euskadi se anime a publicar la serie completa de fallecidos por provincias, como ha hecho recientemente con la serie de casos por franjas de edad. Originalmente se publicaba exclusivamente en datos diarios sueltos en los informes en PDF y ahora es una serie más de datos abiertos.
¿Por qué publicar una serie de casos detectados por provincias y no la de fallecidos?
El términio “death by data” fue usado por primera vez en este artículo “Longitudinal Field Research on Change: Theory and Practice” de Andrew M. Pettigrew (1990). Me lo ha soplado David Rodríguez Mateos, que es quien me introdujo al término.






{kind=link}