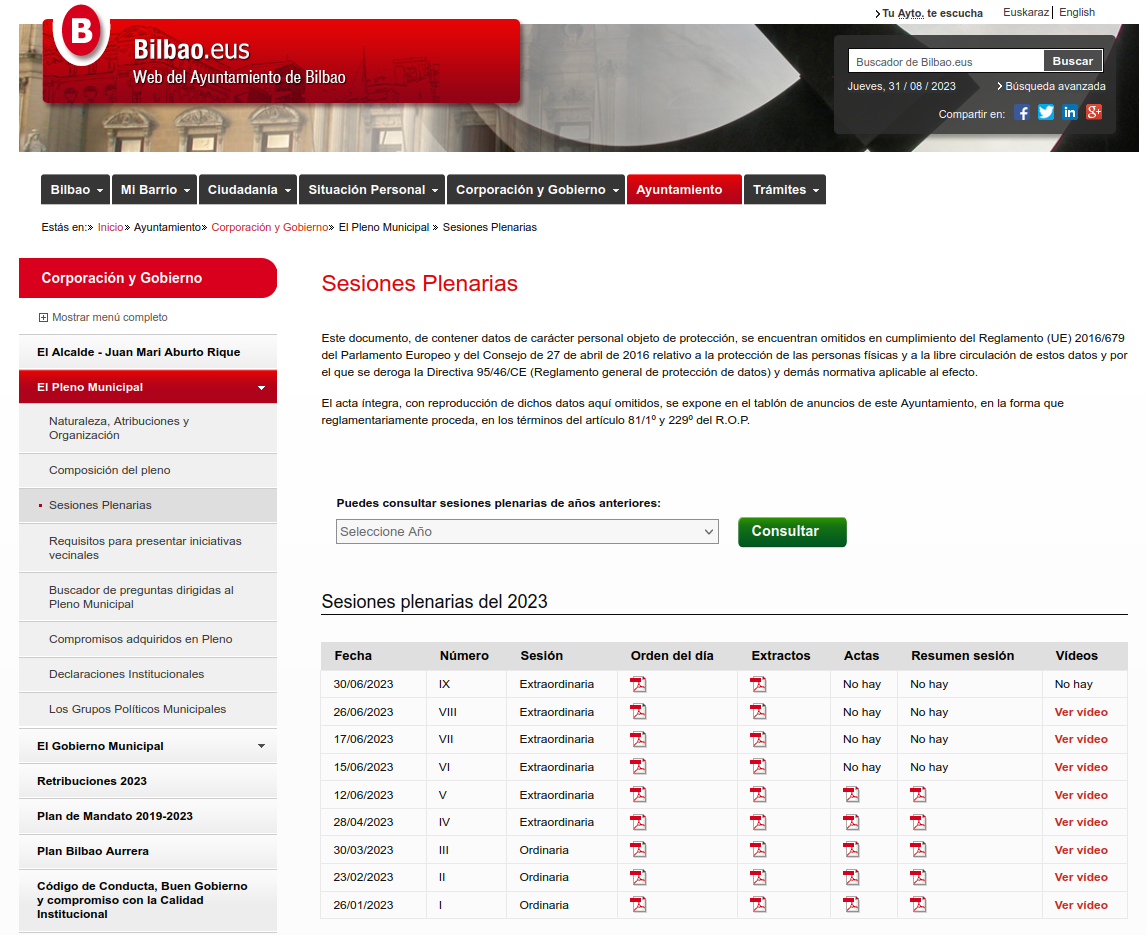
El Ayuntamiento de Bilbao consiguió evitar el juicio que iba a celebrarse hoy jueves para no tener que dar explicaciones sobre la aplicación de la normativa. El juzgado condenó simbólicamente al Ayuntamiento en costas.

Por el parque con su coche
Apatruya la ciudad
(Foto tomada minutos después de que me pusieran la multa).
En mayo de 2023 me multaron por ir con mis hijos en bici por el parque de Doña Casilda en Bilbao. Recurrí la multa y el Ayuntamiento de Bilbao desestimó mis alegaciones. Recurrí entonces ante los juzgados de lo contencioso-administrativo para que se aclarara si era acorde a la normativa o no circular en bicicleta por el parque. Tras varios aplazamientos, se fijó el juicio para el 19 de septiembre.
En agosto de 2024, el gobierno municipal intentó mediante la anulación de la multa evitar el juicio y así no tener que dar explicaciones sobre la normativa que regula la circulación en bici. Su argumento, 16 meses después de poner la multa, era que el expediente no había sido “debidamente tramitado” y solicitaba el archivo por satisfacción extraprocesal. Esto de “satisfacción” es un eufemismo, porque seguimos sin aclaración de cuál es la correcta aplicación de la normativa, que era y es el principal objetivo.
Presentamos alegaciones, porque no habían anulado la multa conforme a los procedimientos requeridos en el derecho administrativo, ni la habían motivado ni notificado correctamente. Hoy ha llegado la notificación del juzgado que anuncia el archivo definitivo del juicio, pasando por alto las alegaciones. Se condena en costas al Ayuntamiento a pagarme 50€ en costas: “Se impone a la parte demandada las costas causadas en el presente recurso, por importe de 50 euros sin incluir el IVA”.
El importe es simbólico, porque imaginad lo que habría podido suponer pagar a un abogado, si no fuera porque apoyó esta causa gratuitamente desde el principio. Donaré esa cantidad a la Asociación Biziz Bizi, Asociación de ciclismo urbano de Bilbao, que me ha apoyado en todo este proceso. Un dinero, que, por otra parte, lo hemos pagado entre todos.
Es una victoria agridulce, ya que el consistorio ha reconocido implícitamente que no tenía razón, pero se ha salido con la suya y no ha tenido que aclarar si se puede o no ir en bicicleta por el parque y en zonas peatonales cuando la concurrencia de personas así lo permita. Como dicen desde Biziz Bizi, muerto el perro se acabó la rabia. Anulada la sanción se acaba la posibilidad de litigar con el Ayuntamiento.
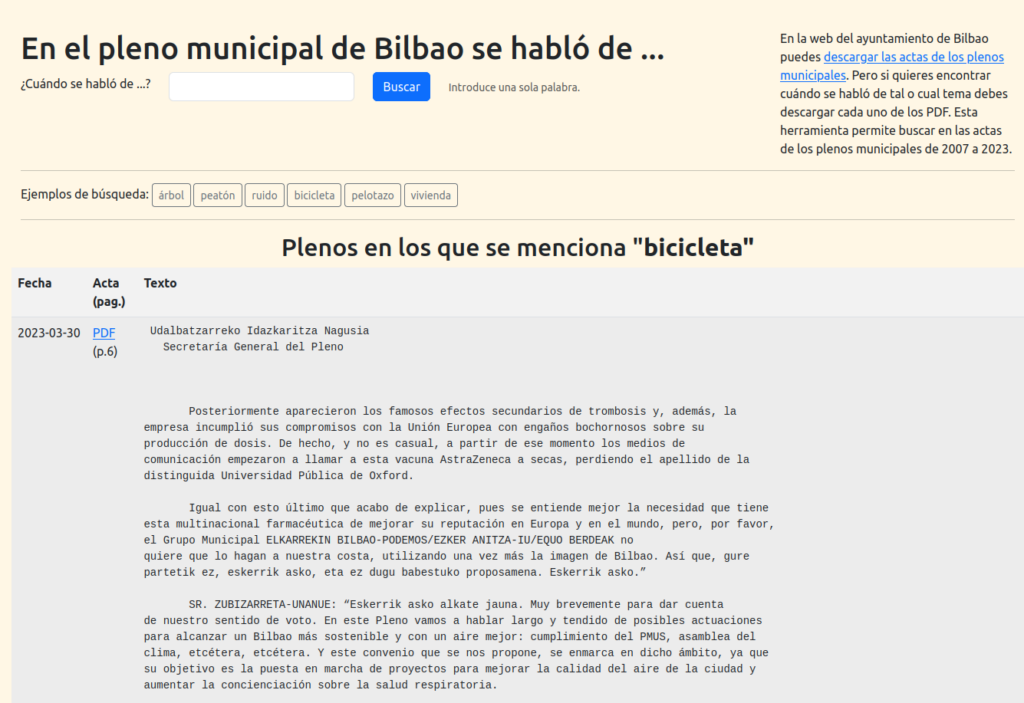
Nos toca buscar otros caminos para que la normativa se aclare. Seguiremos informando. Hablo en plural, porque en el proceso hemos aunado fuerzas la buena gente Biziz Bizi y Aitor Anchía, el abogado que ha hecho posible este proceso judicial. Una alegría encontrar nuevos amigos mientras intentamos hacer el mundo un poco mejor. Han pasado más cosas positivas en este proceso. Por ejemplo, que al principio de todo esto monté una web donde poder buscar en las ordenanzas municipales, porque la web del Ayuntamiento solamente te permite descargar cada PDF por separado. Y más tarde, siguiendo con esta idea de “abrir” lo que contienen los PDF y hacerlos buscables, hice otra web para buscar en las actas de los plenos municipales y los de distrito desde 2007.
Ahora puedo circular de nuevo en bici por Doña Casilda cuando la concurrencia de personas así lo permita, aunque no tenga la sentencia que me hubiera gustadoa enseñar a la policía si me paraba. De momento he ido a probar hoy, de camino a la inauguración-protesta del carril bici de Biziz Bizi. No me han puesto multa.
PD1: Publicaremos todos los documentos de este litigio, convenientemente anonimizados, por si pueden servir a otras personas en sus luchas contra la Administración.
PD2: El Ayuntamiento vio que iba a tener que responder en el juicio a este listado de preguntas que el juzgado había aprobado:
1. ¿Es cierto que el Ayuntamiento de Bilbao, a través de sus Ordenanzas permite que adultos circulen en bicicleta u otros medios de transporte similares en zonas peatonales cuando la concurrencia de personas así lo permita, extremándose en todo caso las medidas de seguridad por parte de la persona usuaria de tales artilugios?
2. ¿Es cierto que el Ayuntamiento de Bilbao, a través de sus Ordenanzas permite que adultos acompañen en bicicleta u otros medios de transporte similares, a menores hasta ciertas edades, ya sea 7, 10 o 12 años?
3. ¿Es cierto que la Policía Municipal de Bilbao tenía un dispositivo de vigilancia especial en la fecha de la multa en el parque de Doña Casilda? Si la respuesta es afirmativa, ¿en qué consistía ese dispositivo y qué motivo el mismo?
4. ¿Existen informes que justifiquen la actuación de ese dispositivo impidiendo a un adulto acompañar en bicicleta u otros medios de transporte similares a menores en bicicleta hasta ciertas edades, ya sean 7, 10 o 12 años?
5. ¿El Ayuntamiento ha realizado la evaluación de las Ordenanzas Espacio Público y de Espacios Verdes que indica el artículo 130 LPAC desde su aprobación hasta la actualidad? Si la respuesta es negativa, ¿por qué no se ha realizado?
6. ¿El Ayuntamiento ha publicado las evaluaciones de las Ordenanzas Espacio Público y de Espacios Verdes que indica el artículo 130 LPAC desde su aprobación hasta la actualidad? – Si la respuesta es afirmativa, ¿dónde las ha publicado? Si la respuesta es negativa, ¿por qué no las ha publicado?
7. ¿El Ayuntamiento ha realizado a través de la policía municipal cursos para aprender a hacer uso de la bicicleta? Si la respuesta es afirmativa, ¿en esos cursos se ha transitado por zonas que luego la policía municipal ha sancionado a personas desplazándose en bicicleta como el paseo de Deusto junto a la ría?