
Hace unos días os contaba lo difícil, por no decir imposible, que era seguir la evolución de los fallecidos por provincias en Euskadi, a no ser que dediques un buen rato, energía y técnica al asunto.
Basta pasearse por las páginas dedicadas a la COVID-19 en Euskadi en los principales diarios que ofrecen información local (eldiario.es, elcorreo.com, por ejemplo) para ver que esos gráficos de evolución de fallecidos por provincia no se publican. Y no se publican porque la Administración publica esos datos de una forma que hace imposible, digamos mejor muy dificultosa, su elaboración. Es un claro ejemplo de cómo la forma de publicar los datos dicta la agenda mediática. Publica los datos de una forma y los medios de comunicación hablarán de una determinada forma ¡Si quieres evitar que se hable de algo, no publiques esos datos!
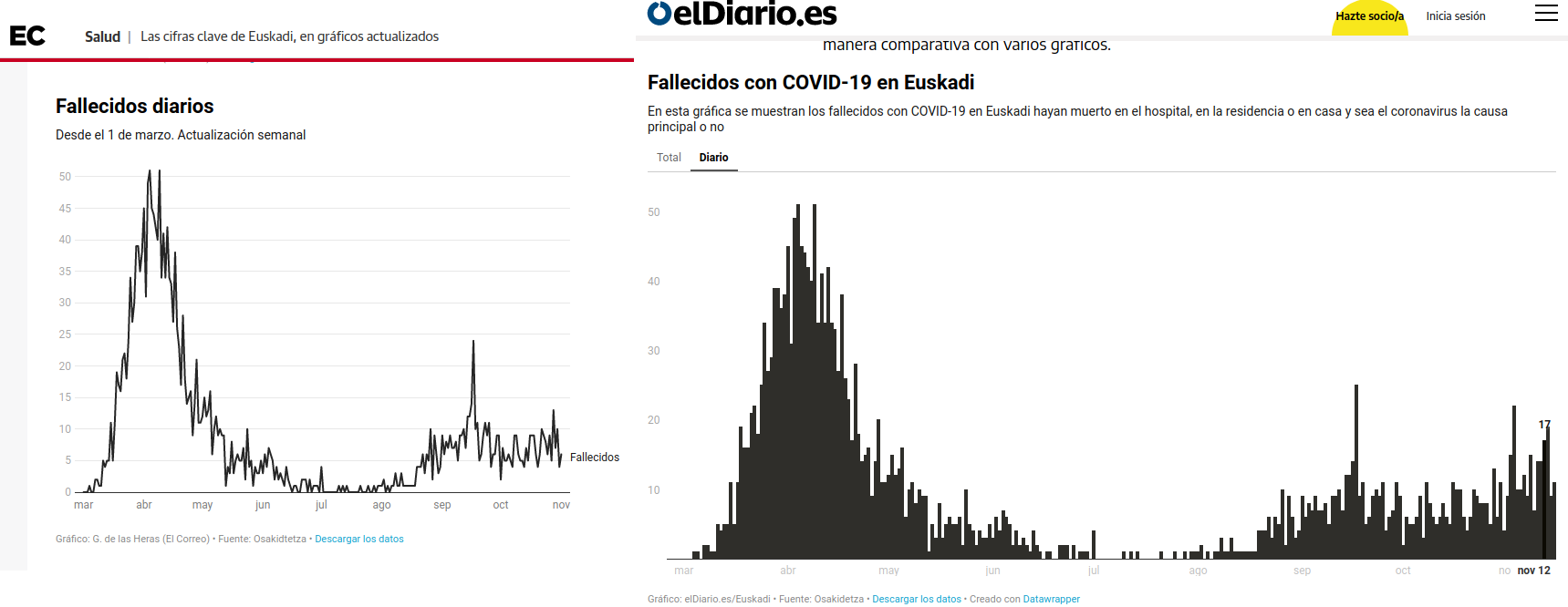
Open Data Euskadi, la plataforma de datos abiertos en País Vasco, publica los datos diarios de fallecidos para toda Euskadi una vez a la semana (pestaña 08 de la hoja de cálculo). Por poner un ejemplo: hasta hoy solamente conocíamos los fallecidos agregados en las tres provincias vascas hasta el 15 de noviembre ¡hace 10 días!
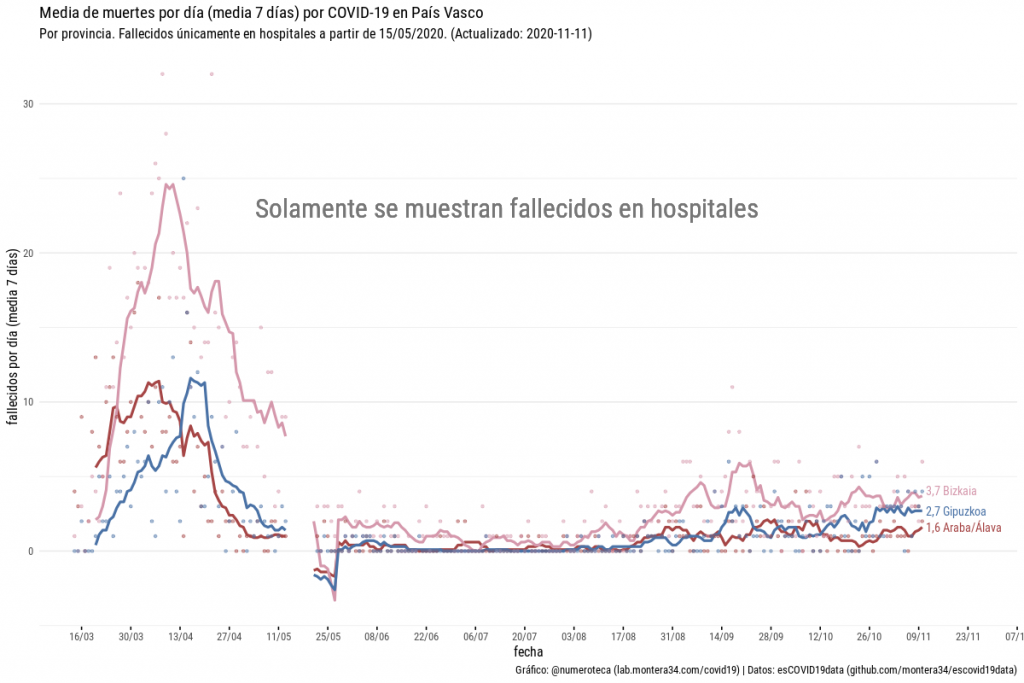
Esta serie de datos vale para ver la evolución en la CAPV, pero no por provincia (Nota: sí que se publica en días laborables los fallecidos por hospitales, que era la cifra que usábamos, por aproximación, hasta hace bien poco).
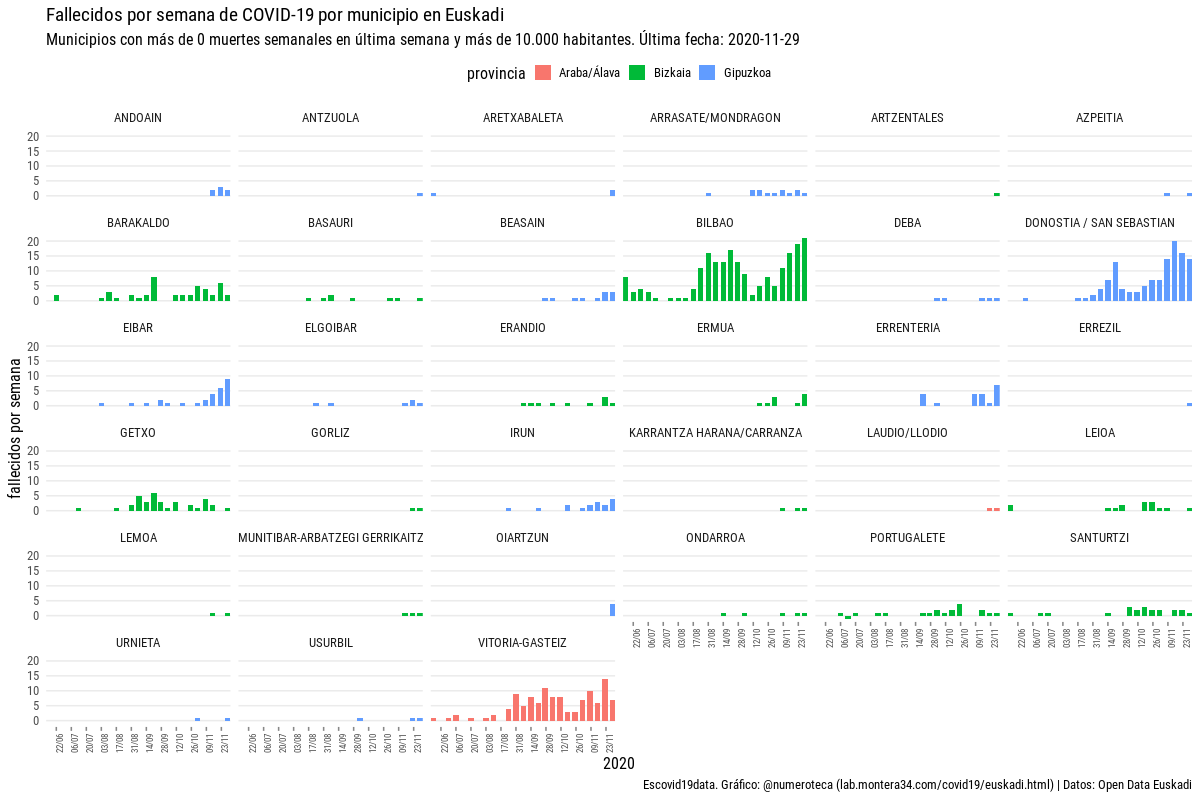
Para construir la serie de fallecidos por provinicas tenemos que recurrir a los datos de fallecidos acumulados que se publican por municipio y una vez a la semana (pestaña 07). Ojo, no se publica el histórico, como sí se hace con los casos o los hospitalizados. Esto es, si quieres saber los fallecidos que había habido en un municipio en determinada fecha no puedes saberlo, porque el archivo que se publica sobre escribe al anterior. Tampoco puedes saber los fallecidos en una determinada semana, porque el dato que se publica es el total acumulado de muertes.
Esto cambió el 20 de octubre de 2020, tras solicitar que fuera posible acceder al histórico de archivos publicados. Además habría que comparar dos archivos para poder calcular el incremetno de muertes de una semana a otra. No nos engañemos, una tarea que nadie va a realizar. A pesar de la buena noticia de que ahora sí se guardan y se publican en abierto los archivos anteriores para permitir trazabilidad… las fechas anteriores al 20 de octubre siguen sin ser accesibles… a no ser que alguien haya guardado todos los archivos que se hayan publicado diariamente… y ¡nosotros lo hemos hecho! (esto es como el he “estudiado a Agrippa” de La Princesa Prometida).
Así que de este modo, no sin un poco de sudor, hemos podido reconstruir la serie histórica de fallecidos por municipios que nos ha permitido construir la serie por provinicas. Un proceso tedioso que implica rescatar con git (el sistema de versiones que usamos) todas las versiones de un archivo, construir la serie y agregar por provincias ¡Por fin tenemos la serie de fallecidos!
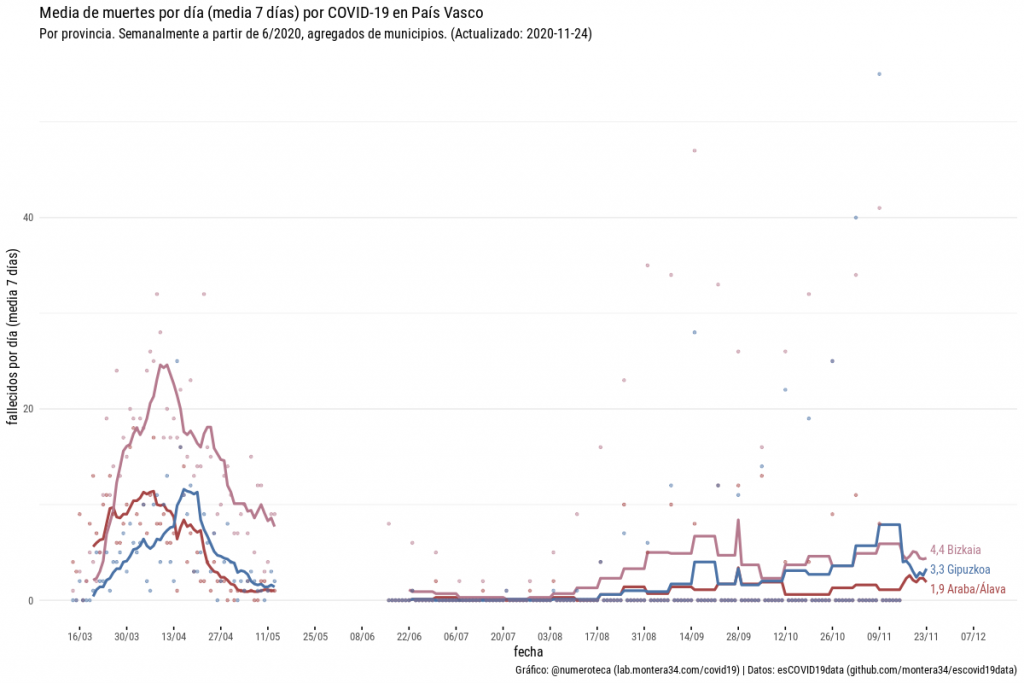
Más gráficos en la web de Escovid19data.
Tenemos un vacio entre mediados de mayo y junio: desde que se dejaron de publicar datos por provincias hasta que se empezó a hacerlo por municipios.
¿Por qué no se publican los datos históricos de fallecidos por municipios, OSI y provinicias? ¿a qué se debe esta opacidad y poner tan difícil una serie de datos que seguro está disponible internamente y que el resto de comunidades autónomas sí publican?
La serie de datos de casos y fallecidos sacada de los archivos por municipios está disponible, pero casi mejor usa la serie completa del repositorio de Escovid19data.
Tenemos más preguntas que ya hemos hecho a Open Data Euskadi, pero las dejamos para otro post.
Esta iniciativa de abrir datos abiertos forma parte del proyecto Escovid19data que recopila colaborativa y voluntariamente datos de COVID-19 en todas las comunidades y ciudades autónomas para ofrecer los datos y gráficos en abierto.




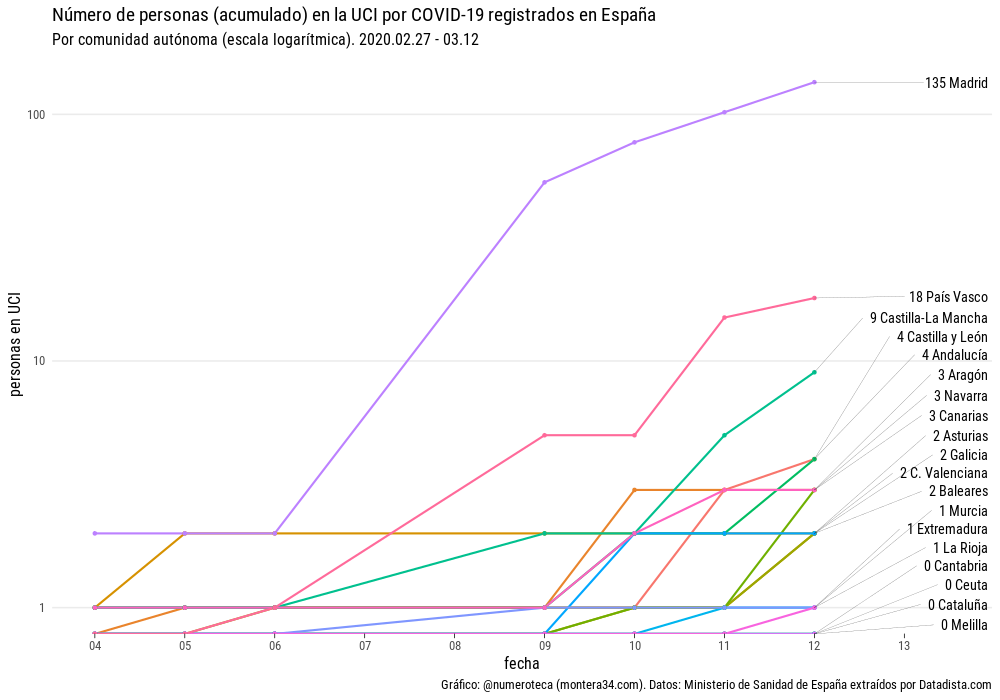
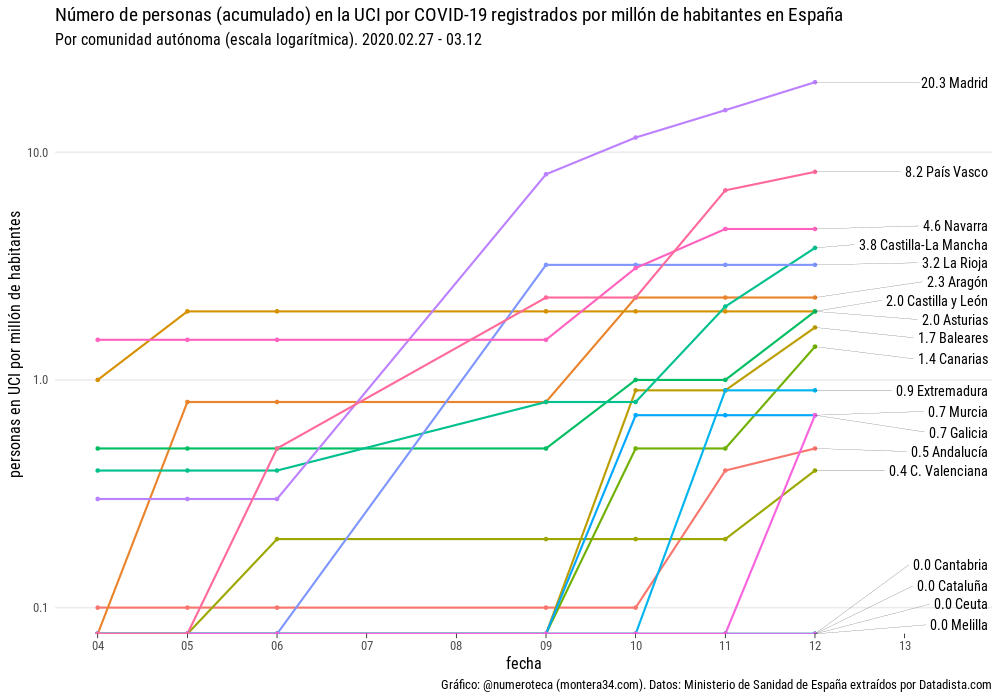
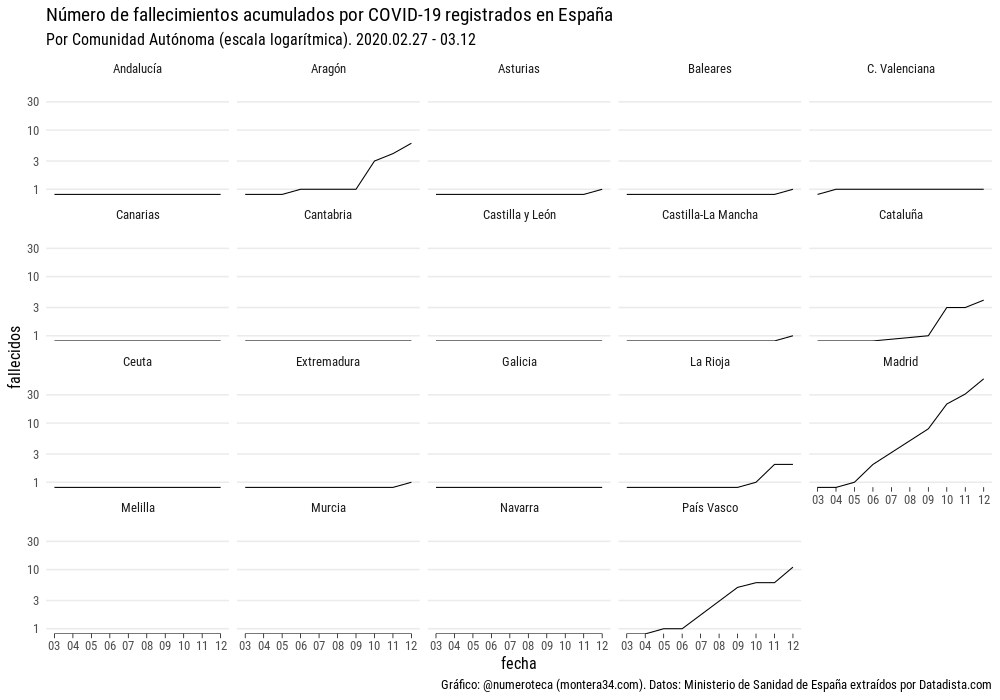
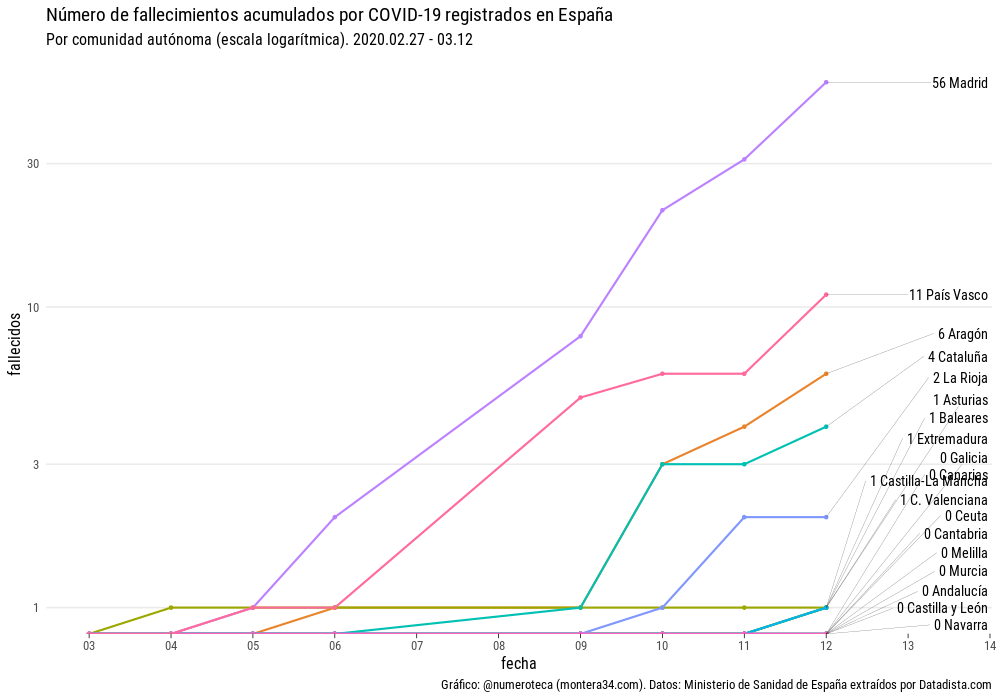


{kind=link}