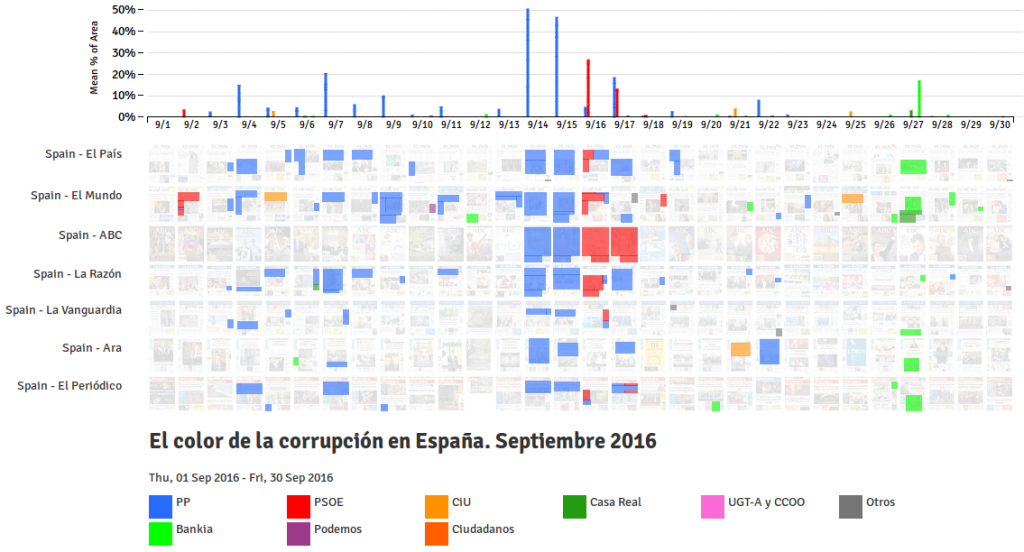
Well, I know you are not going to read the entire PhD thesis and annexes, so I am publishing it little by little, chapter by chapter. I am transforming the content to html, so I can use all the hyperlinks features and make it easier to navigate. It will take months, but I’ll complete the job.
I’ve created a page that is a summary of all the extra content of the dissertation: Color of corruption. Visual evidence of agenda-setting in a complex mass media ecosystem submitted on December 2022 and defended successfully on June 2023.
I’ve already uploaded all the code for the data gathering and analysis as well as the data bases that I’ve used.
I haven’t posted as much as I wanted to tell what I was doing, but I hope this page will help introduce what I’ve been doing. It’s been a long very long journey.
A visual analysis of all the pages of the PhD dissertation.
PS: In the past I’ve also published my research online, see these two examples. The goal was to publish the process, not only the final results, and make them available for everyone else:
TLDR: cómo procesar uan pregunta de todos los barómetros del CIS que no está en los archivos fusionados. Necesito para mi tesis procesar todos los microdatos. Preguntas y próximos pasos al final.
Una de las fuentes de datos que uso para mi tesis son los barómteros del CIS. Cada mes desde hace muchos años el CIS hace una encuesta, barómetro, en donde se pregunta por los tres principales problemas que tiene España.
18/ …y analizando cómo la sociedad percibe la corrupción, por ejemplo, usando los barómetros del CIS y su percepción de ésta como problema. imagen de barómetro y corrupción. Analicé esto para el libro @espanaconC, un manual para entender de dónd viene la corrupción en España pic.twitter.com/13ZLGebAmk
Como los microdatos de cada barómetro están disponibles, esto es, cada una de las respuestas a los cuestionarios está publicada, es posible analizar y cruzar variables por edad, comunidad autónoma o profesión. El primer problema es conseguir y procesar los datos.
Disponibilidad de los datos: web y FID
Lo primero es dirigirse a la página del CIS a descargarlos (pestaña Estudios http://www.analisis.cis.es/cisdb.jsp), pero se encuentra uno el primer problema: hace falta introudcir tus datos personales (nombre, apellidos, universidad, email, objeto) para descargarlo, lo cual descarta un scrapero rápido automatizado de los datos. Existen datos fusionados de varios barómetros juntos para algunos años, pero no están disponibles para todos los años.
Así que la siguiente opción es usar los Fichero Integrado de Datos (FID) (http://analisis.cis.es/fid/fid.jsp) “un único fichero, de los microdatos de un conjunto de variables, para los estudios del CIS que se seleccionen”:
“El interfaz permite al usuario elegir de forma rápida y cómoda a partir de una colección, los estudios que desee y, de estos, las variables deseadas de entre las contenidas en el diccionario del FID. Posteriormente, la solicitud se envía al CIS y, una vez que el CIS procede a su autorización, el fichero con los microdatos seleccionados se puede descargar en formato ASCII o SAV, de modo sencillo y fácil de tabular por diversos programas estadísticos. Es necesario el registro del usuario o identificación del mismo (si el usuario ya está registrado), para completar una petición de datos”.
Web del CIS. Explicación sobre los Fichero Integrado de Datos (FID).
El problema es que la pregunta que necesito “¿Cuál es el principal problema que existe en España? ¿ y el segundo? ¿y el tercero?”, aunque su enunciado concreto ha ido variando a lo largo de los años, no está disponible en los FID, ya que solamente se ofrece un subconjunto de las variables integradas.
Según me han indicado soy el primero en hacerlo. Me parece raro que nadie lo haya hecho antes, ciertamente. Seguramente hayan usado otros métodos.
Tras una serie de pruebas con unos archivos de prueba para comprobar que los abría bien han procedido a preparar para que descargue todos los microdatos de los barómetros en zips por año. En pocos días me he hecho con la colección completa de microdatos de barómetros.
.zips esperando paciente a ser abiertos.
Un poco de código para descomprimirlos fácilmente:
unzip ‘*.zip’ unzipear todos los archivos mv */* . mover los que están en directorios al raiz mv MD*/* . rm -r 19* 20* fu* eliminar directorios vacíos Ahora que tengo todos, volver a unzipear: unzip ‘*.zip’
Ahora creo un archivo con todos los *.sav: ls | grep sav > files.csv
Ahora tengo el listado de todos los barómetros disponibles (los de 2020 y 2021 me da un problema para abrirlos que tengo que resolver “error reading system-file header”). Puedo procesar todos los microdatos de los barómetros desde junio de 1989, los anteriores solamente están disponibles uno de 1987 (nº 1695), dos de 1985 (nº 1442 y 1435) y otro de 1982 (nº 1320), que me enviarán cuando sea posible. Para el resto desde junio de 1979 no hay microdatos y habría que pagar por ellos si los quisiera.
Encontrar la pregunta y su número
Documentos que se incluyen en un .zip de un barómetro.
Para poder analizar las respuestas por CCAA, que es mi objetivo, tengo que encontrar el código de la pregunta, que, oh sorpresa, va cambiando a lo largo de los años. Para ello he montado una hoja de cálculo para anotar qué código lleva la pregunta (https://docs.google.com/spreadsheets/d/1xxlt8FnWanVzYkIQdU2yaWlE8-HUvnzVXSiE2QvNJRU/edit#gid=0). Así, la primera vez que aparece es en los archivos disponibles es de mayo de 1992, y tiene los códigos P501, P502 y P503, una por cada uno de los problemas percibidos. Ese código ha ido variando a lo largo de los años a la pregunta: P1401, P701, P1601, P1201… los primero números indican el número de la pregunta. Para averiguar el código hay dos maneras. Cada barómetro está compuesto por un conjunto de archivos. Así, el barómetro nº 3134 tiene los siguientes archivos:
3134.sav microdatos
DA3134 archivo dat
ES3134
FT3134.pdf ficha técnica
cues31314.pdf cuestionario original
codigo3134.pdf códigos utilizados
tarjetas3134.pdf tarjetas que usan los encuestadores
Al principio miraba si la pregunta estaba en el cuestionario, pero luego vi que era más rápido mirar directamente si en el archivo con los códigos venía la pregunta y su número: “P.7 Principal problema que existe actualmente en España. El segundo. El tercero” que con suerte correspondería con la variable P701, P702 y P703.
El problema es que en algunos casos contados ponen la “p” de la variable con minúscula y el código es p701. Algo que solamente se puede averiguar abriendo el archivo .sav. Para ver lo que contiene el archivo.sav con la librería “foreign” en R: df <- read.spss(data, use.value.label=TRUE, to.data.frame=TRUE), siendo data el “path” al archivo .sav correspondiente.
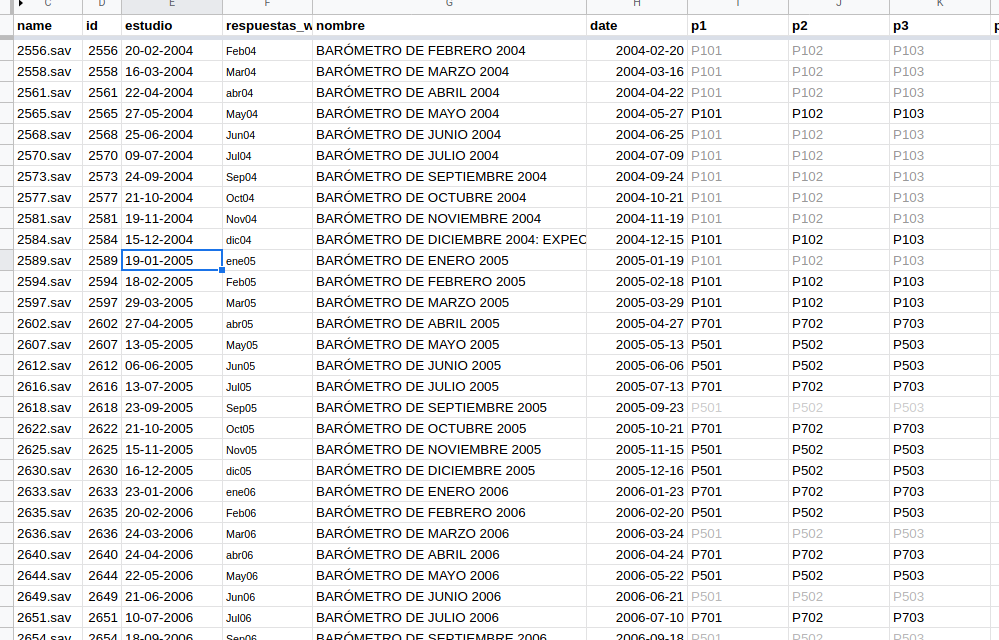
Desde Rstudio se puede previsualizar el archivo .sav cargado y mirar cuál es el código correcto:
Así se ve en Rstudio.
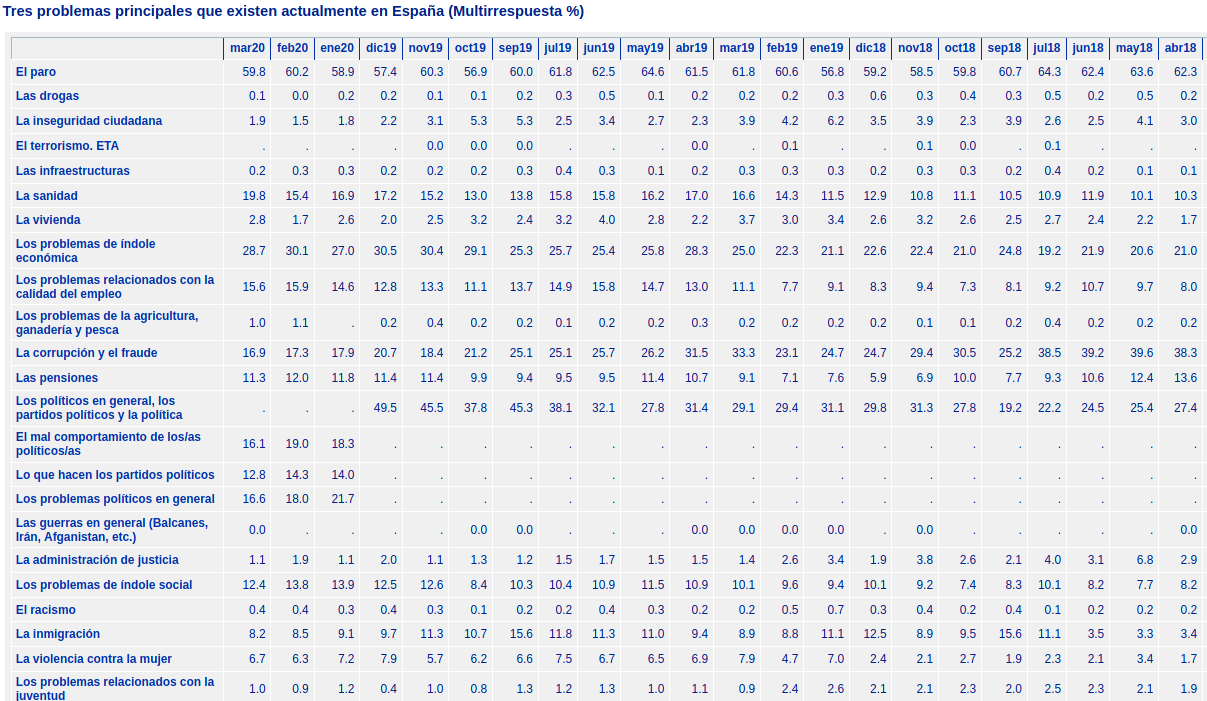
Lo que pasa es que muchos barómetros no tienen disponible esa pregunta, pero ¿cómo saberlo para ahorrarnos tiempo? Existe una página, ya ni recuerdo cómo llegué a ella, que tiene todas las respuestas recogidas y procesadas “Tres problemas principales que existen actualmente en España (Multirrespuesta %) http://www.cis.es/cis/export/sites/default/-Archivos/Indicadores/documentos_html/TresProblemas.htm, esto pernite de un vistazo saber cuáles son los barómetros que tienen respuesta:
Así se puede ir a tiro hecho a buscar el código en los barómetros que sabemos tienen respuesta. Relleno celdas de la hoja de cálculo de las columnas p1, p2 y p3 (cada una corresponde con una de las respuestas a los 3 principales problemas) copiando el valor anterior, hasta que da error el script que lo procesa (ver más adelante).
Clasificando en p1, p2 y p3 los códigos de las preguintas en cada uno de los barómtreos. En negro si lo he mirado, en gris si lo he “acertado” y no ha fallado el script.
Pero no se detienen los problemas. Los encuestadores recogían la respuesta libre (que no se ofrece en los microdatos) para después clasificarla en unos cajones-respuestas establecidos:
Lo que ocurre es que en algunos años “La corrupción y el fraude” no se ofrecían como respuesta posible, así que de haber habido alguna respuesta corrupción como respuesta en aquello años de bonanza económica habrá ido a la casilla de “otros”. Esto pasó entre septiembre de 2000 y julio de 2001, por ejemplo, lo que hará que la serie tenga algunos agujeros. Habrá que hacerlos explícitos.
Procesar 1: juntar todas las respuestas
Una vez sorteadas estas trabas es la hora de programar un script que vaya abriendo cada archivo .sav, seleccione las variables adecuadas y cree un archivo con todas las respuestas:
# Select and load multiple barometro files ------------
# where are files stored
path <- "~/data/CIS/barometro/almacen/tmp/"
# remove if it hasn't got the questions
cis_files <- cis_files %>% filter( p1 != "" )
# iterate through all the files
for ( i in 1:nrow(cis_files) ) {
# for ( i in 1:8 ) {
print("--------------------")
print(paste(i,cis_files$name[i],cis_files$date[i] ) )
# create path to file
data <- paste0(path, cis_files$name[i])
# load data in the file
df <- read.spss(data, use.value.label=TRUE, to.data.frame=TRUE)
# chec if variable ESTU exists
if ( "ESTU" %in% colnames(df) ) {
df <- df %>% mutate(
ESTU = as.character(ESTU)
)
} else {
# if ESTU is not in the variables, insert the ID of the barometer
df <- df %>% mutate(
ESTU = cis_files$id[i],
ESTU = as.character(ESTU)
)
}
# if REGION exixts, rename it as CCAA
if ( "REGION" %in% colnames(df) ) {
df <- df %>% rename(
CCAA = REGION
)
}
# add date to data by taking it gtom cis_id dataframe
df <- left_join(df,
cis_id %>% select(id,date),
by = c("ESTU"="id")
# ) %>% select( date, ESTU, CCAA, PROV, MUN, P701, P702, P703 )
)
# select the basic columns and the 3 questions
# the true name of the question is specified in the online document https://docs.google.com/spreadsheets/d/1xxlt8FnWanVzYkIQdU2yaWlE8-HUvnzVXSiE2QvNJRU/edit#gid=0
selected <- c( "date", "ESTU", "CCAA", "PROV", "MUN", cis_files$p1[i], cis_files$p2[i], cis_files$p3[i])
df <- df %>% select(selected) %>% rename(
p1 = cis_files$p1[i],
p2 = cis_files$p2[i],
p3 = cis_files$p3[i],
) %>% mutate(
p1 = as.character(p1),
p2 = as.character(p2),
p3 = as.character(p3)
)
# For the first file
if ( i == 1) {
print("opt 1")
# loads df in the final exportdataframe "barometros"
barometros <- df
print(df$date[1])
print(df$ESTU[1])
} else {
print("not i==1")
barometros <- rbind( df, barometros)
}
}
Por el momento tengo 570.795 respuestas a la pregunta analizada de 223 barómetros, a falta de solventar algunos problemas.
Ahora toca agrupar las respuestas por barómetros de nuevo y calcular el número de encuestas por barómetro que hacen mención a tal o cual tema:
# Group by date and CCAA ----------------------
evol_count <- barometros %>% group_by(CCAA,date) %>% summarise(
# counts number of elements by barometro and CCAA
count_total = n()
) %>% ungroup()
evol_p1 <- barometros %>% group_by(CCAA,date,p1) %>% summarise(
# counts number of answers for each type for question 1 by barometro and CCAA
count_p1 = as.numeric( n() )
)
evol_p2 <- barometros %>% group_by(CCAA,date,p2) %>% summarise(
# counts number of answers for each type for question 1 by barometro and CCAA
count_p2 = as.numeric( n() )
)
evol_p3 <- barometros %>% group_by(CCAA,date,p3) %>% summarise(
# counts number of answers for each type for question 1 by barometro and CCAA
count_p3 = as.numeric( n() )
)
# joins p1 and p2
evol <- full_join(
evol_p1 %>% mutate(dunique = paste0(date,CCAA,p1)) ,
evol_p2 %>% mutate(dunique = paste0(date,CCAA,p2)) %>% ungroup() %>% rename( date_p2 = date, CCAA_p2 = CCAA),
by = "dunique"
) %>% mutate (
# perc_p2 = round( count_p2 / count_total * 100, digits = 1)
)
# fills the dates and CCAA that were empty
evol <- evol %>% mutate(
date = as.character(date),
date = ifelse( is.na(date) , as.character(date_p2), date),
date = as.Date(date),
CCAA = as.character(CCAA),
CCAA = ifelse( is.na(CCAA), as.character(CCAA_p2), CCAA),
CCAA = as.factor(CCAA)
)
# joins p1-p2 with p3
evol <- full_join(
evol,
evol_p3 %>% mutate(dunique = paste0(date,CCAA,p3)) %>% ungroup() %>% rename( date_p3 = date, CCAA_p3 = CCAA),
by = "dunique"
) %>% mutate (
# perc_p2 = round( count_p2 / count_total * 100, digits = 1)
)
# fills the dates and CCAA that were empty
evol <- evol %>% mutate(
date = as.character(date),
date = ifelse( is.na(date) , as.character(date_p3), date),
date = as.Date(date),
CCAA = as.character(CCAA),
CCAA = ifelse( is.na(CCAA), as.character(CCAA_p3), CCAA),
CCAA = as.factor(CCAA)
)
# add number of answers per barometer and CCAA
evol <- left_join(
evol %>% mutate(dunique = paste0(date,CCAA)),
evol_count %>% mutate(dunique = paste0(date,CCAA)) %>% select(-date,-CCAA),
by = "dunique"
) %>% mutate (
count_p = count_p1 + replace_na(count_p2,0) + replace_na(count_p3,0),
# este sistema da error en los "no contesta" al contarlos varias veces al sumar!!!
perc = round( count_p / count_total * 100, digits = 1)
) %>% select ( date, CCAA, everything(), -dunique, -date_p2, -date_p3, -CCAA_p2, -CCAA_p3 ) %>% mutate(
p = p1,
p = ifelse( is.na(p),p2,p),
p = ifelse( is.na(p),p3,p),
date = as.Date(date)
)
Limpiar los datos 2: las respuestas
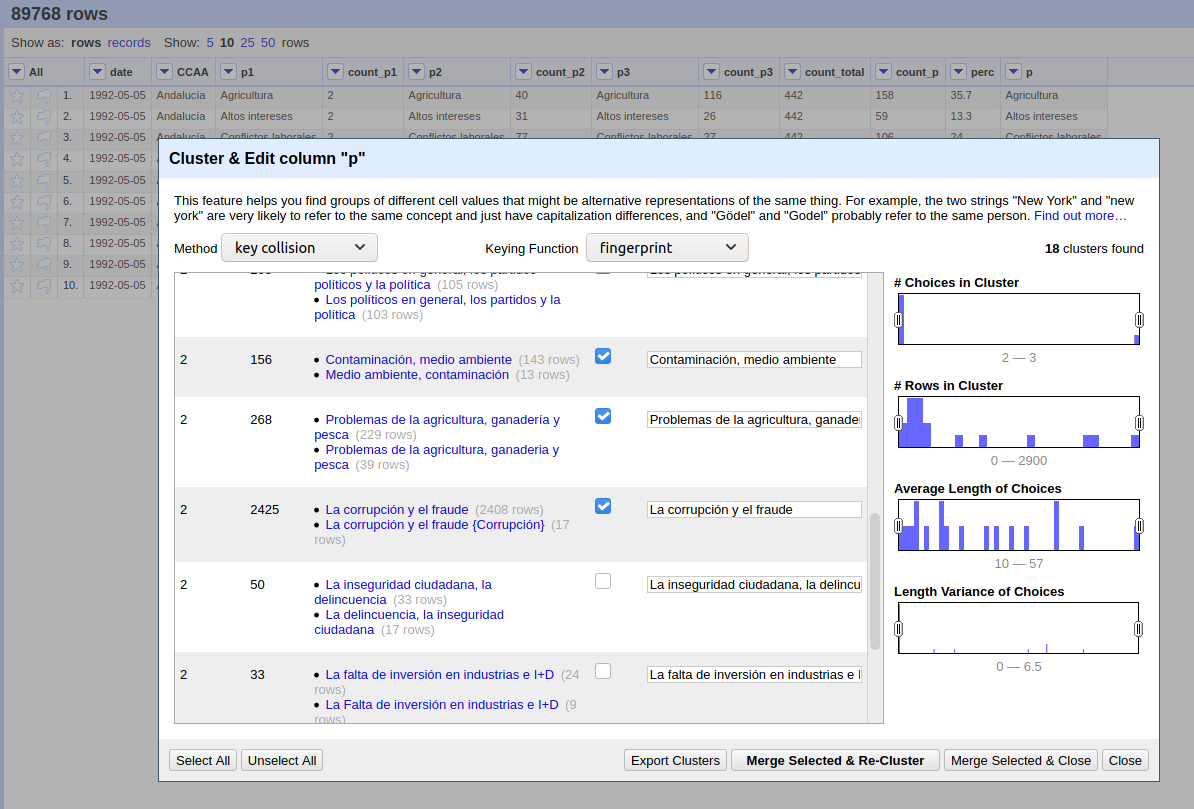
Toca limpiar las respuestas para eliminar las múltiples formas de escribir “La corrupción y el fraude” o “Corrupción y fraude ” (ojo al espacio después de “fraude” que a algunos vuelve loco). Una tarea de estandarización de las respuestas que hago con OpenRefine y que en algunos casos requiere de decisiones subjetivas, véase el ejemplo:
Detección de respuestas parecidas para su consolidación en OpenRefine.Proceso de consolidación de respuestas con OpenRefine.
Visualizar
El siguiente paso es visualizar los resultados para detectar los primero errores y corregir problemas en la captura y procesado. Antes de publicar esto ha ocurrido varias veces: detecté unos barómetros de 2016 que no se habían descomprimido, por ejemplo.
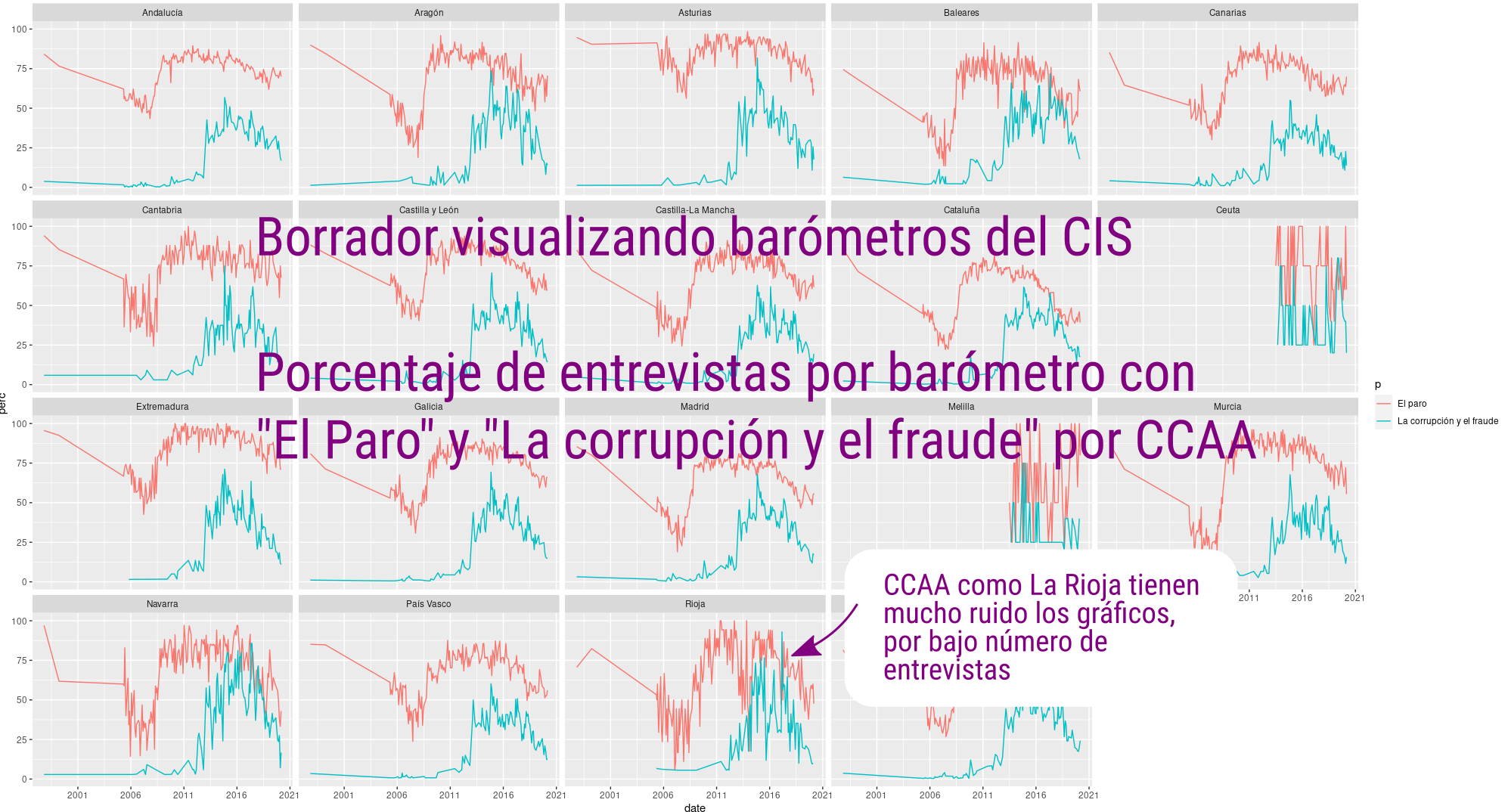
En las primeras visualizaciones trato de ver que salen valores congruentes y que no hay agujeros en los datos. En este primer gráfico de rejilla muestro el porcentaje de entrevistas de cada barómetro que tienen como respuesta “El paro” (rosa) y “La corrupción y el fraude” (verde). Ya se pueden ver cómo hay mucho más ruido en lugares como Ceuta y Melilla por el bajo número de respuestas, pero que el resto de valores sigue una tendencia parecida. En La Rioja (fila de abajo, tercera por la izquierda) también se ve ese problema, con sus 17 entrevistas por barómetro.
Un primer vistazo a las visualizaciones, publicaré más cuando tenga más claro que no hay errores en los datos
Problemas y siguientes pasos
Desde el CIS no solamente me enviaron todos los microdatos sino que me asesoraron sobre su uso. Les conté lo que pretendía hacer con los datos y me advirtieron de dos cosas relacionadas con la cantidad de entrevistas por CCAA y la ponderación:
A. Ponderación en SPSS
“Los ficheros Sav, por defecto van con la ponderación activada, siempre, en todos los que hemos pasado ya y en los que pasaremos, de esta lista”, algo que no entiendo del todo bien, porque eso no creo que deba afectar a los microdatos. Si alguien ha trabajado con los .sav en SPSS quizás me pueda aclarar cómo funciona la ponderación en ese programa, dónde se almacena esa información.
B. Si no tienes más de 400 entrevistas…
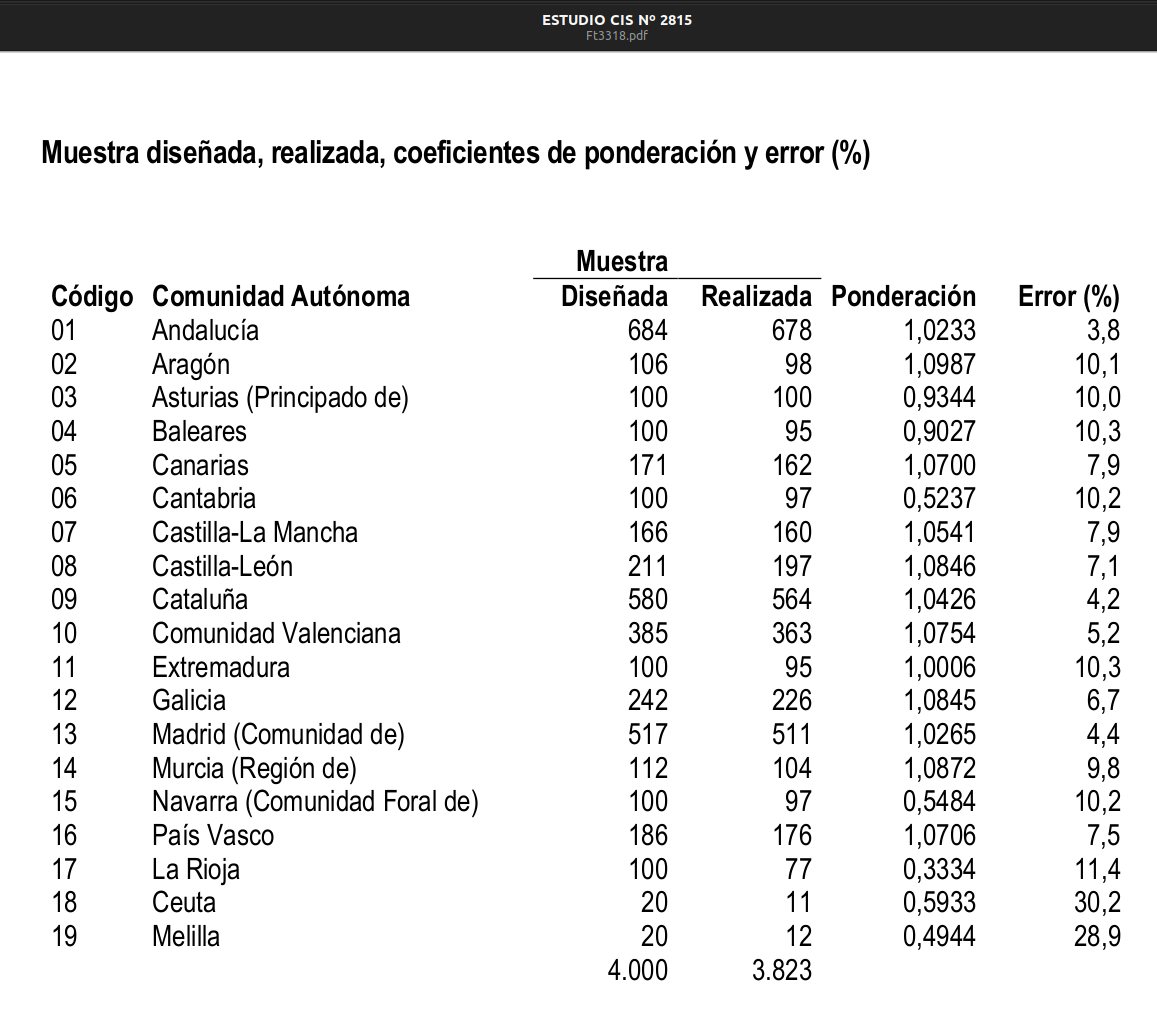
“Nosotros no consideramos representativos los datos de Comunidades con un tamaño menor a 400 entrevistas. En los barómetros, salvo los del último año para algunas Comunidades (mire ficha técnica), el tamaño muestral es de entorno a las 2.500 entrevistas, eso significa que habitualmente salvo Madrid y Cataluña, la mayor parte se quedan muy por debajo, incluso de menos de 100. Los márgenes de error cuando se quiere hablar sobre esos datos son muy altos, y más aún si además va a hacer cruces”. Me redirigían a una sección de su web:
ADVERTENCIA: El error muestral aumenta conforme disminuye el número de entrevistas realizadas. Téngase presente sobre todo en los cruces de variables y las preguntas filtradas. A modo orientativo, bajo la hipótesis de muestreo aleatorio simple, P=Q=1/2 y un 95% de intervalo de confianza, véase la siguiente tabla: Fuente: http://www.analisis.cis.es/aAvisoVars.jsp?tipo=2&w=800&h=600
Una cuestión no menor que puede hacer que no use finalmente estos datos para las comunidades, o tenga que emplear grados de incertidumbre demasiado altos.
En los últimos estudios sí aparece la ponderación usada para el valor global:
Día en que se realiza la entrevista ¿se podría saber?
Tenía interés en cruzar el día de la encuesta para ver si se podía estudiar con determinados escándalos que tienen un día muy marcado su anuncio en los medios de comunicación, podŕia verse su impacto en las encuestas, pero ese dato no está disponible. Lo que se conoce es el periodo en que se realizan las encuestas, que suele ser la primera quincena del mes. ¿se podrá conseguir la fecha exacta de cada entrevista?
En el mes de Marzo de 2018 eldiario.es sacó a la luz irregularidades en el caso del máster de la entonces presidenta de la Comunidad de Madrid Cristina Cifuentes. Para tener más contexto puedes escuchar el magnífico podcast sobre el escándalo que publicó eldiario.es.
En esta serie de posts analizaremos cuantitativa y cualitativamente la cobertura que se le dio al escándalo en diferentes medios de comunicación y redes sociales para intentar entender cómo es el flujo de información entre unos canales y otros. Estos textos forman parte de la investigación para mi tesis doctoral sobre cobertura de corrupción en España. En su momento ya analicé la cobertura en las portadas de los periódicos en papel.
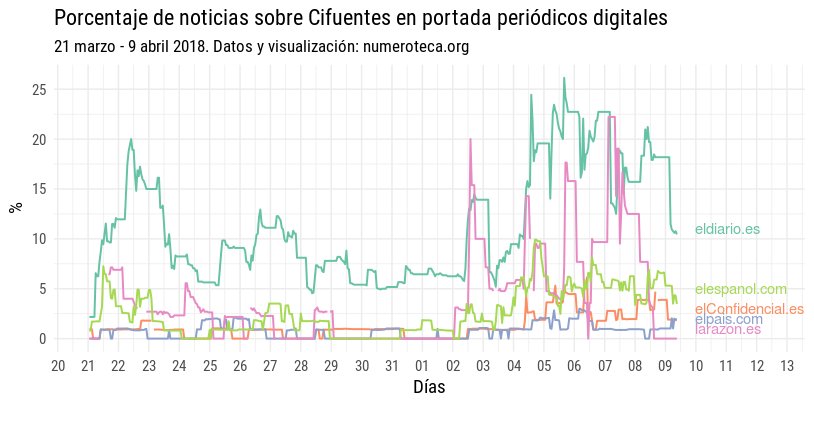
Porcentaje de noticias en portada Cifuentes (sobre el total) en periódicos digitales.
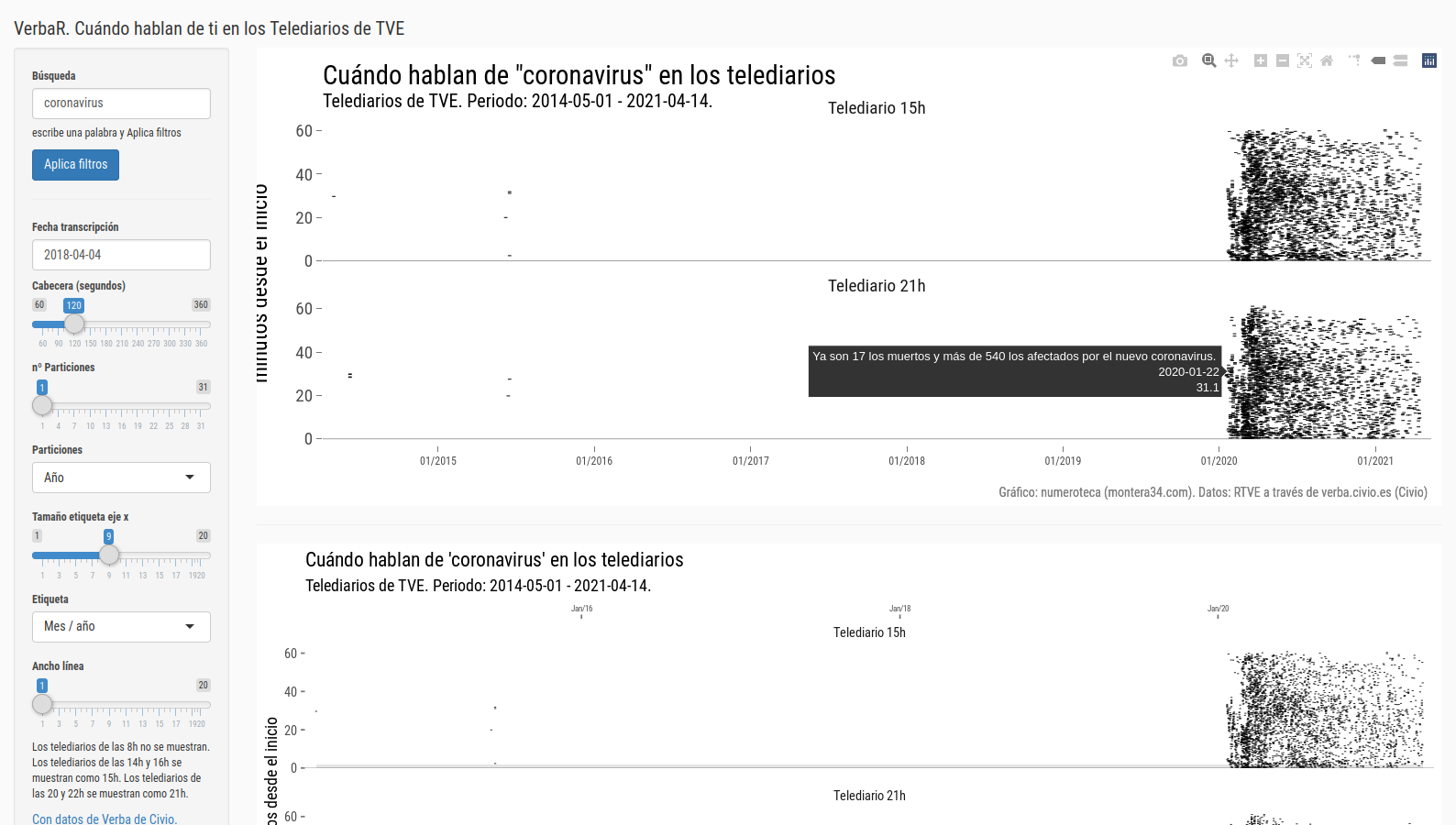
Hoy analizo las noticias sobre lo que se ha venido a conocer como el caso “Máster” en una nueva base de datos: los Telediarios de Televisión Española que Civio pone fácil estudiar con su herramienta Verba (https://verba.civio.es/).
Verba permite hacer búsquedas por palabras en las transcripciones de los telediarios de TVE y descargar los datos. La unidad de medida es la frases que contiene tal o cual palabra.
No centraremos ahora en cuando estalló el escándalo, el 21 de marzo de 2018. El resultado es fruto buscar en Verba tras la búsqueda multipalabra para ese periodo concreto: “Cifuentes”|”Javier Ramos”|”Enrique Álvarez Conde”|”Pablo Chico”|”María Teresa Feito”|”Alicia López de los Cobos”|”Cecilia Rosado”|”Clara Souto|Amalia Calonge”|”Universidad Rey Juan Carlos”.
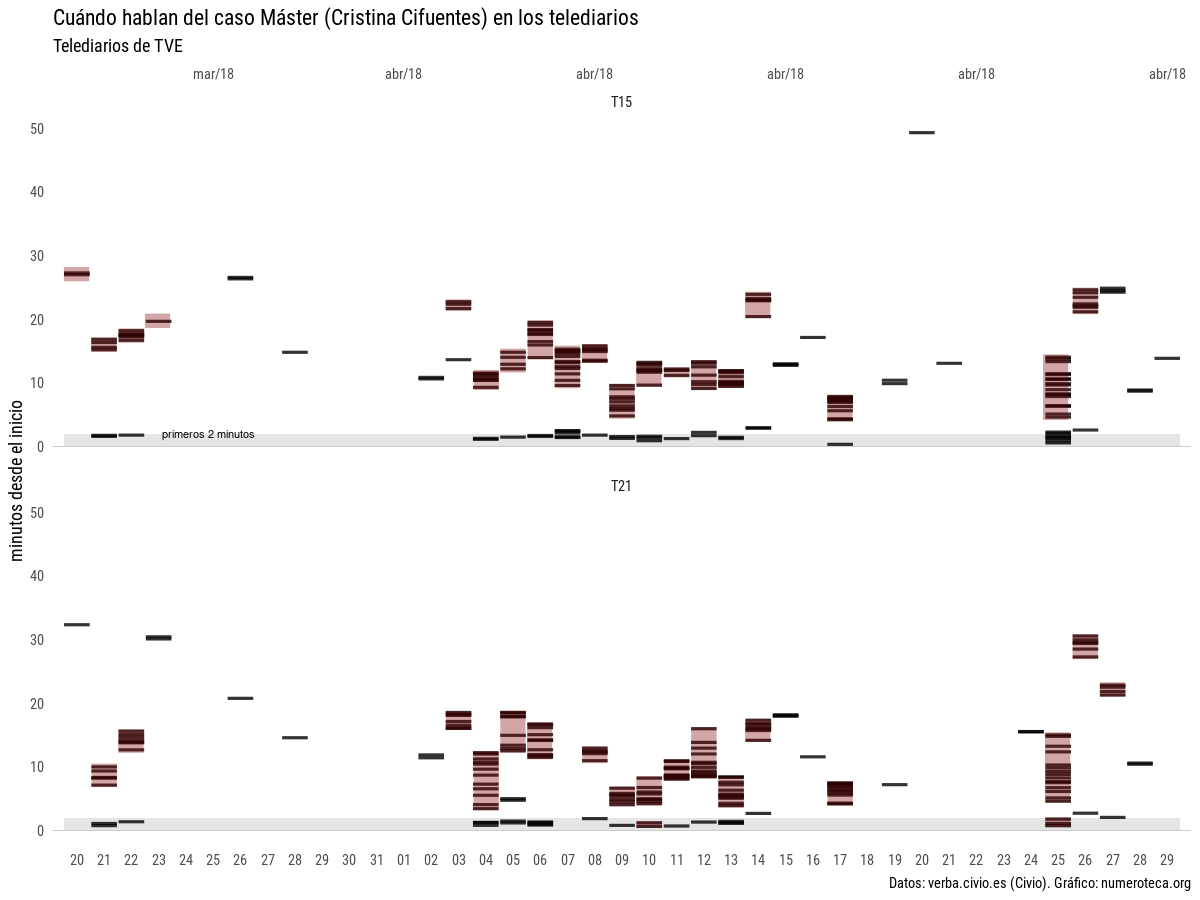
Los gráficos están hechos con VerbaR, unos scripts de R que he desarrollado para analizar con R datos de Verba. Cada línea negra es una frase que incluye una de las palabras de la búsqueda:
El gráfico está dividido en una parte de arriba, para los telediarios de las 15:00h y la de la abajo, para los de las 21:00h. He marcado los primeros dos minutos para enfatizar la cabecera o “portada” del noticiario. No tengo claro todavía cuánto dura este inicio con las noticias más destacadas.
Aquel 21 de marzo, tras salir publicado el escándalo en eldiario.es el Telediario de las 15:00h se hizo eco de la noticia en su apertura:
1’18”: La Universidad Rey Juan Carlos atribuye a un error de transcripción que en dos asignaturas del máster que Cristina Cifuentes cursó hace seis años figurase como no presentada.
1’28”: Cifuentes aprobó ambas asignaturas, según ha confirmado el rector.
Más adelante expandía la noticia ne el minuto 14:
14’56”: En Madrid, la universidad Rey Juan Carlos niega cualquier irregularidad en el máster de la presidenta Cristina Cifuentes.
15’03”: Un diario digital sostiene que obtuvo la titulación con dos notas falsificadas.
Verba ofrece la posibilida de acceder a la transcripción completa y no solamente a las frases resultado de la búsqueda-
En el gráfico se puede ver cómo en ese primer día hay dos bloques de información: el del resumen inicial, esos 2 ó 3 minutos -estaría bien poder cuantificarlo- y cuando se amplia la noticia. Esa cabecera viene a ser análoga a la portada de los periódicos, donde se seleccionan las noticias más importantes.
El problema de la búsqueda por palabras es que se deja fuera las frases que no contienen las palabras buscadas pero que pertenecen a la noticia, por ello esos existen huecos en los gráficos entre unas líneas y otras. Por ejemplo, la noticia en cabecera duraba más, pero se quedó fuera de nuestra búsqueda:
1’31”: La oposición pide explicaciones.
1’34”: El Gobierno regional subraya la honorabilidad del comportamiento de la presidenta.
En el gráfico se ha sobredimensionado la duración de las frases asignándoles 30 segundos de duración para facilitar su lectura.
Si pudiéramos distinguir los bloques de noticias, cuando empieza un tema y acaba otro, podríamos ver algo como esto, donde coloreo “a mano” en rojo la posible duración del total de las noticias relacionadas con el máster:
Este otro gráfico visualiza el número de frases que contienen las palabras clave. Suma todas las frases encontradas y las agrega en una columna:
Nos da una idea aproximada de la evolución de la cobertura. Sería interesante poder clasificar esta información según los días que la noticia ha estado en la cabecera del telediario y poder así estudiar la relación de tiempo de frases dedicadas a la noticia con su aparición en el resumen de inicio. También sería interesante conocer la duración de la noticia, y no únicamente el número de frases encontradas.
Si volvemos a hacer el primer gráfico clasificando manualmente las frases seleccionadas, podemos entender mejor la historia: primero salta la noticia sobre el master (“máster” en verde) , vuelve a aparecer a primeros de abril con fuerza, con 10 días seguidos con noticia en cabecera en el telediario de las 15:00h y se cierra con la dimisión el 26 de abril, tras el nuevo escándalo del vídeo sobre el robo de las cremas en un supermercado:
Podemos ver estos mismo datos agregados en columnas:
Este primer análisis nos permite ver la potencia y las limitaciones de este tipo de visualizaciones:
las palabras clave de búsqueda son determinantes
es necesario reclasificar la información para poder analizar en profundidad la evolución de la cobertura. Otras variables a analizar serían el enfoque de las noticias.
¿Cómo de relevante fue la cobertura de TVE en relación a otros medios de comunicación o redes sociales como Twitter? Lo veremos en los siguientes capítulos.
He creado una aplicación con Shiny para poder generar gráficos de este tipo y analizar más rápidamente las diferentes búsquedas en Verba: [actualizción: mejor esta versión: https://r.montera34.com/users/numeroteca/verbar/app/] https://numeroteca.shinyapps.io/verbar/
Gracias a que es interactiva puedes ver que contiene cada frase.
Hay una opción que te permite seleccionar una fecha y ver todas las frases de ese día.
Para mi tesis sobre cobertura de corrupción en España llevo tiempo recopilando tuits. Llevo el seguimiento de mensajes de Twitter relacionados con algunos casos de corrupción, para luego poder compararlos con cómo los medios de comunicación han hablado del tema.
Utilizo t-hoarder, desarrolllado por Mariluz Congosto, para capturar tuits según se van publicando. Lo tengo instalado en un servidor remoto que está continuamente descargándose tuits que contienen una determindad lista de palabras. Con un interfaz en la línea de comandos desarrollado en python permite interactuar de manera sencilla con la API de Twitter para obtener y procesar tuits descargados (ver este manual que escribimos hace un tiempo para aprender a usarlo).
T-hoarder guarda los tuits en archivos .txt en formato .tsv. Cada cierto tiempo comprime el archivo streaming_cifuentes-master_0.txt en uno comprimido streaming_cifuentes-master_0.txt.tar.gz que contiene entre 150.000 o 250.000 tuits.
En el servidor se van acumulando estos archivos comprimidos que me descargo periódicamente con rsync: rsync -zvtr -e ssh numeroteca@111.111.111.111:/home/numeroteca/t-hoarder/store/ .
Con ese sistema tengo un directorio con múltiples archivos de los diferentes temas que voy capturando:
El primer paso consiste en entender de forma básica qué he conseguido recopilar. Hay múltiples razones por las que puedo tener agujeros en los datos: el servidor se llenó, el acceso a la API de Twitter se interrumpió por algún problema de permisos, etc.
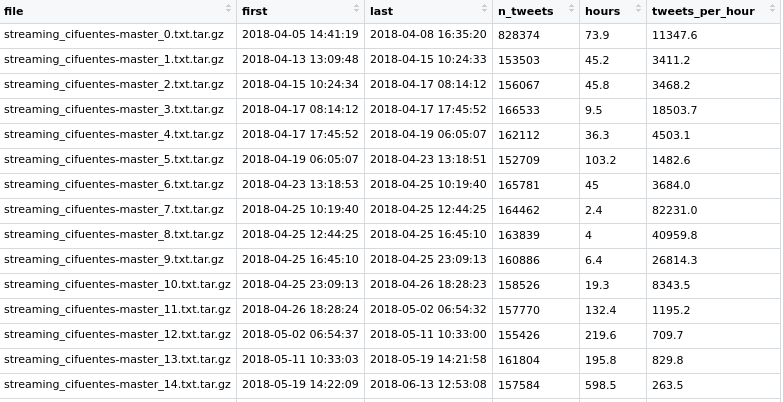
Para ello he desarrollado este pequeño script en bash para obtener la información básica que contiene cada archivo de tuits:
Este script lee todos los archivos como streaming_cifuentes-master_20.txt y va guardando en cada línea del archivo mycifuentes.txt en líneas separadas: el nombre del archivo tar.gz, la fecha y hora del primer tuit (head) y del último (tail) y por último el número de tuits. Con eso obtengo un archivo como este:
Que proceso a mano en gedit son sustituciones masivas (me falta generar mejor el tsv donde cada campo esté en la línea que le corresponde):
Actualización 8 junio 2020: Gracias a @jartigag@mastodon.social que me llegó por Twitter no me hace falta el procesado manual ya que cada dato va a su propia columna:
lo que hace es leer el archivo (read_tsv) y cuenta las horas entre el primer y último tuit y calcula los tuits por hora:
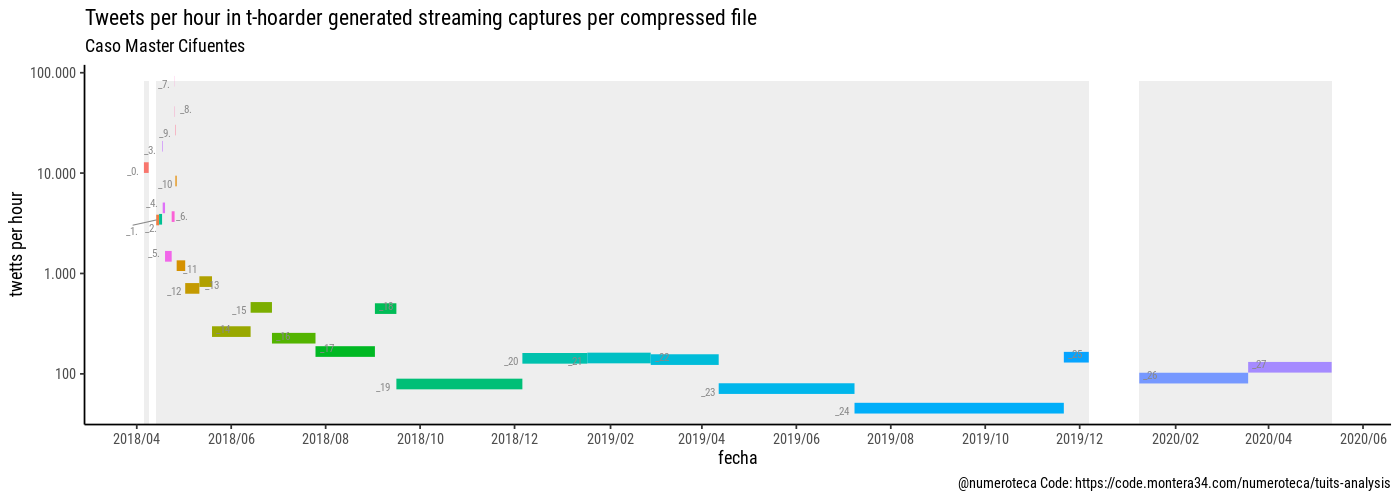
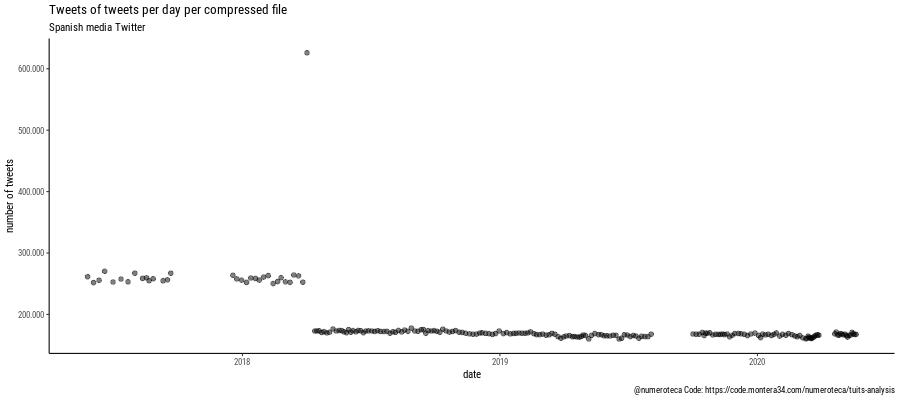
Ahora ya podemos hacer las primeras visualizaciones para explorar los datos. En este primer gráfico cada línea es un archivo que va del primer al último tuit según su fecha. En el eje vertical se indica el número medio de tuits por hora. En el caso del master de Cifuentes el primer archivo no se comprimió por error y contiene 828.374 tuits. el fondo gris indica cuando no hay tuits descargados. Hay un periodo en blanco la inicio del caso y otro en diciembre de 2019, la escala vertical es logarítmica, para que se puedan ver todos los archivos incluyendo los primeros.
En este otro gráficos (escala vertical lineal) muestro los archivos de tuits que he capturado de unos cuantos medios de comunicación españoles, para luego poder comparar las diferentes coberturas, vuelvo a tener agujeros para los que todavía tengo que encontrar explicación.
En este otro gráfico comparo la fecha del archivo con el número de tuits que contiene:
Este es un primer análisis muy “meta” que no entra ni de lejos a analizar el contenido de los tuits pero me sirve como primer paso para entrar en faena a analizar los datos que tengo. Tenía que haber hecho esto hace tiempo. En cualquier caso bueno es ponerse en marcha y documentar. Mis conocimientos de bash son escasos pero creo que merece la pena y es más rápido en este caso que usar R. Inspirado por este libro que estoy a medio leer Data Science at the Command Line de Jeroen Janssens.
5 Easy Facts About https fortnite com 2fa Described buy testosterone cypionate 250mg ski-in/ski-out hotel sport, saas-almagell: find the best price
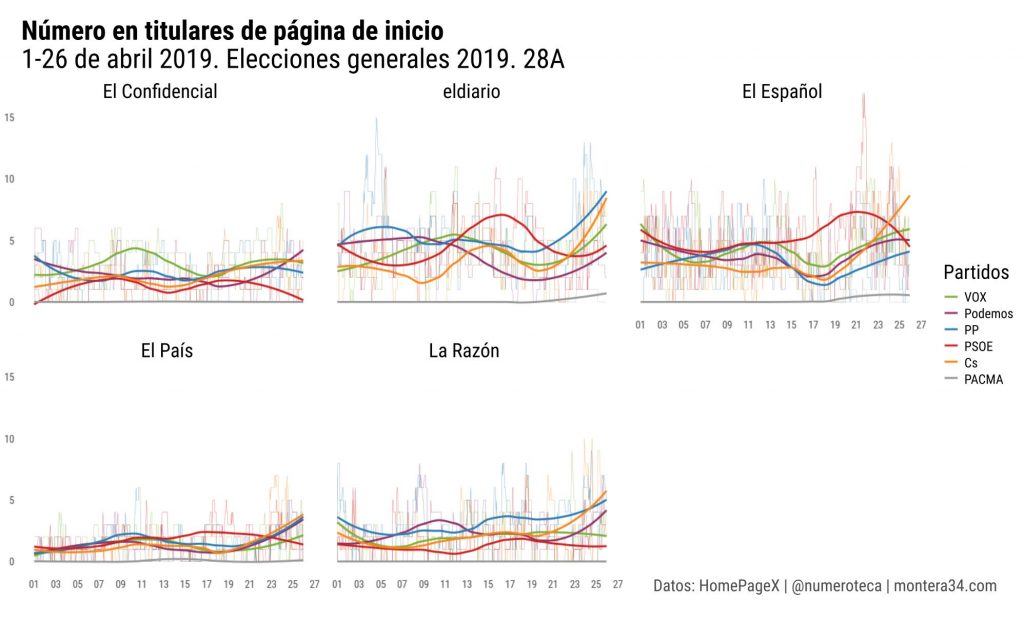
He analizado los titulares de las páginas de inicio de algunos periódicos online antes del #28A para medir la cobertura de los principales partidos de ámbito estatal. Cuento nº de titulares que contengan los nombres, siglas o líderes de cada partido #homepagex c @PageOneXpic.twitter.com/QzO7jan2ao
He analizado los titulares de las páginas de inicio de algunos periódicos online antes del #28A para medir la cobertura de los principales partidos de ámbito estatal. Cuento nº de titulares que contengan los nombres, siglas o líderes de cada partido #homepagex c @PageOneX
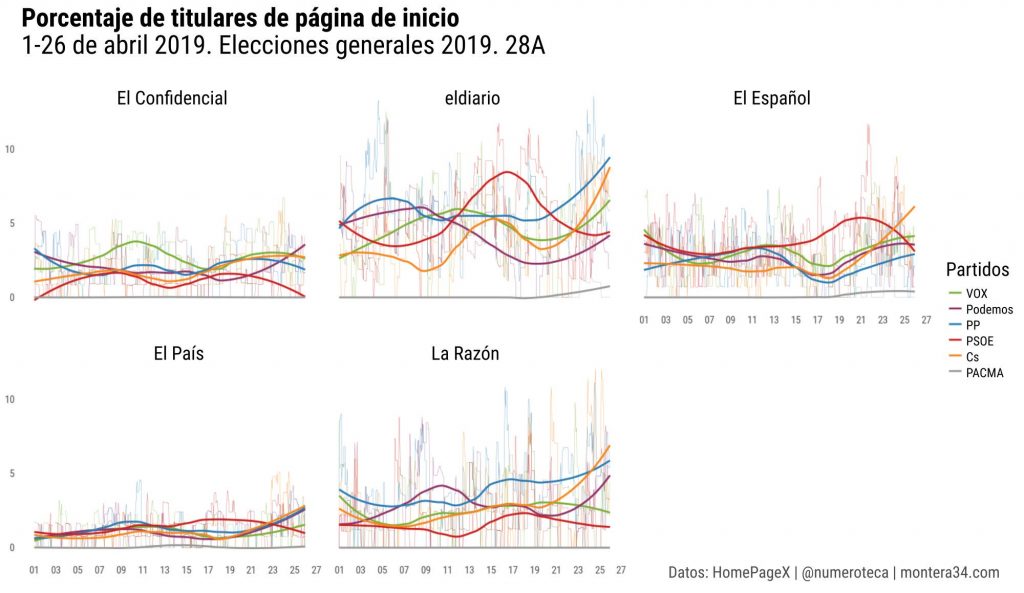
He calculado también el porcentaje de esos titulares sobre el total de titulares de cada página de inicio #28A. Una forma de medir automatizadamente la cobertura que realiza cada medio.
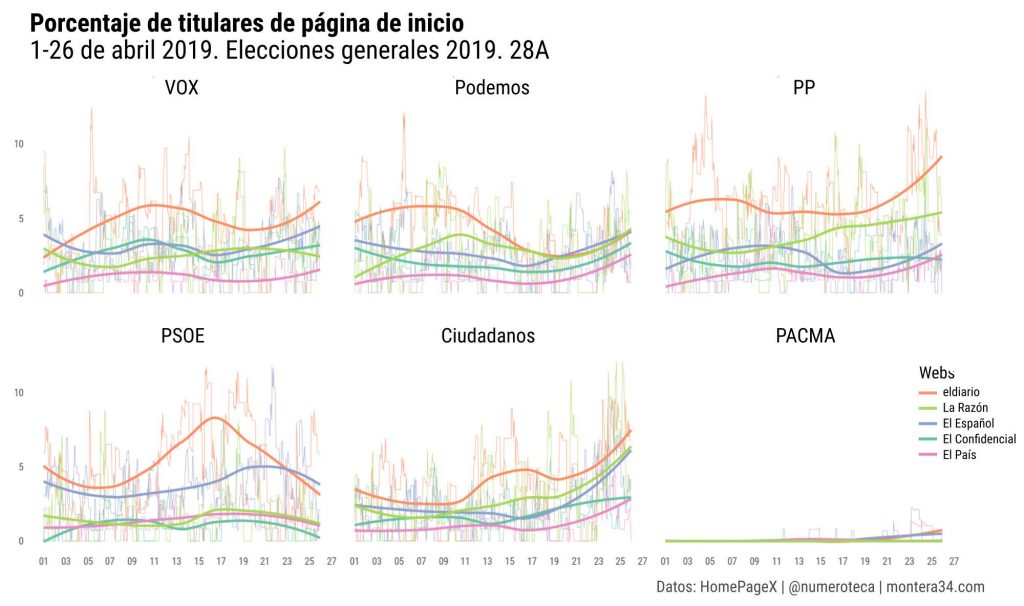
Y aquí agrupando por partido, que facilita la comparativa entre cabeceras. Las líneas finas son los datos por hora y las más gruesas el redondeo que permite ver las tendencias más fácilmente #28A
Son análisis preliminares mientras refino la herramienta. Encantado si queréis aportar vuestra lectura y crítica. Hoy no me dará tiempo a más. Se basan en una base de datos que recopila hora a hora las páginas de inicio de cada periódico
Too long & do not read Spanish: How to parse and make the visualizations based on the archive of digital home pages built with storytracker: R code available.
Bueno, por fin puedo ponerme a contar noticias de Cifuentes en portada de los periódicos digitales. A ver qué sale:
Para poder el porcentaje de noticias sobre Cifuentes en portada necesitamos saber cuál es el total de noticias en cada momento (cada hora) en cada periódico:
Noticias en portada por hora en eldiario.es.
Después hay que contar los titulares en portada de las noticias que contienen “Cifuentes” (y palabras relacionadas con el caso de su máster) para un periódico. Ejemplo con eldiario.es:
Número de noticias en portada en eldiario.es sobre Cifuentes.
Para hacer el cálculo del número de noticias se han elegido todas aquellas que incluyen una de las siguientes palabras o grupos de palabras en su titular: “Cifuentes|Javier Ramos|Enrique Álvarez Conde|Pablo Chico|María Teresa Feito|Alicia López de los Cobos|Cecilia Rosado|Clara Souto|Amalia Calonge|Universidad Rey Juan Carlos”.
Justo ayer, el día que empezaba a declarar Correa en el juicio de la primera época de la Gürtel, me ha llegado la noticia. Ha sido aprobado el proyecto de tesis y plan de investigación “The color of corruption coverage in Spain” (descarga el pdf) que presenté en mayo. Así que ya soy oficialmente doctorando. Sólo me queda hacer la tesis. Correa es el acusado clave de la trama y por el que toma nombre el caso Gürtel, que es “correa” en alemán.
Ahora un resumen de los últimos acontecimientos en cunato a la tesis se refiere.
Data gathering in the age of information
It’s been a busy week. Almost all the tasks are related to data gathering: tweets, front pages or video streaming. It is interesting how non trivial is to gather all the different information flows that surround as.
Researched different ways of “hunting” tweets. This reminds me to the uncompleted experiment I launched for collecting tweets with different methods.
Check out this scripts:
Cheered Mari Luz Congosto to relaunch t-hoarder.com, a platform that collects, visualizes and archives tweets about corruption in Spain. It is the main I plan to use for my PhD dissertation. I am going to help her document the tool to allow other researchers/activists install, use it and… share their data!
By the way, we are looking for other people interested in installing their own instances of t-hoarder… or hosting our own instance. Do you have empty space in your server?
I’ve been recording the video streaming of the Gürtel trial, one of the main cases of corruption in Spain that involves the party in the government (PP), as I am not finding any public archive that does it for me. I’ve used Kazam to do it, so it means that I have to be there at the right moment. It is like going back to he ’80-’90 and recording with VHS.
I have the video recording, the tweets of the day, the screenshots of the main online newspapers… I’ll be able to reconstruct on an minute basis one day in the media ecology of that particular corruption case.
Answers from reviewers to the thesis research plan
Hypothesis too general “hypotheses are too general. Here is my recommendation: the candidate defines the hypothesis thinking on the connection between the dependent and independent variables”.
Operationalization of variables and independent variables “The candidate will use three types of data, one related to front-pages of print media, another with the information about twitter, and public opinion. To do that the candidate not only will follow existing methodologies but will also use pageonex.com (elaborated by the author). Here it will be relevant to know something else about the operationalization of variables. I guess the unit of analysis is going to be stories (number of percentage?), tweets (number?), public opinion (percentage?) for one or two years (2016-2017). Also we need more information about which are the independent variables that will be taken into account. In general the methodology seems as appropriate for the plan but needs further elaboration in the future”.
Define agenda setting role of media, traditional vs new media, analyze literature
“In general, it is clear the author has analyzed some of the main contributions to the field, but there are some important shortcomings. There is not a discussion about which is the agenda setting role of the media, what we mean by that, why this is important, and which are the factors that limit the capabilities of the new and traditional media to develop this agenda setting role. (…) Accordingly, the theoretical part needs an elaborated discussion about the agenda setting role of the new and traditional media, highlighting the similarities and differences between the two and why this matters. To do that the author needs to analyze the literature about agenda setting taking into account authors like Norris to better understand the role of the media in a democracy, Graber and Iyengar to explain the agenda setting role of the media and the interconnection between different types of media outlets, Hallin and Mancini to better understand the media systems and why this matter (just to mention some of the most cited).
Add asocial movemente theory and atudy anti-corruption activist
“Suggest the author add an additional RQ / hypothesis about anti-corruption activists attempts to influence the mass media agenda, outside of social media (through meetings, petitions, protests, and so on). Do anti-corruption protests shift the mass media agenda? (…) The author may want or need to develop additional data (qualitative and/or quantitative) about attempts by anti-corruption activists to shift the mass media agenda. For example, a dataset of anti-corruption protests, by size/participation, and/or analysis of interviews with anti-corruption activists. (…) the dissertation might benefit from a section that engages significantly with the social movement studies literature. Specifically, there is a subfield of social movement studies that explores the ways that social movement actors attempt to gain access to mass media visibility, and in the context of the Spanish corruption cases, presumably this is taking place extensively. This introduces additional possibilities and questions about mass media agenda setting. For example: are there social movement actors who have personal friends among journalists, editors, and other members of the mass media? Potentially, they are meeting, lobbying, talking with, protesting, and otherwise attempting to shift the mass media agenda to cover corruption, NOT ONLY via social media but also through face to face methods, phone calls, petitions, meetings, perhaps direct actions, advertiser boycotts, and so on. Also: do anti-corruption protests shift the news agenda?”
Mejor conexión entre los ámbitos de la investigación
“Faltaría, en algunos casos, trabar mejor la transición o la interconexión entre los distintos ámbitos de la investigación. En especial faltaría una mejor/mayor justificación de la (supuesta) disrupción que hacen los medios sociales en el panorama informativo y su papel de contrapeso con los medios tradicionale. (…) La parte del impacto de los nuevos medios en el establecimiento de la agenda debería reforzarse para que no quede coja respecto al resto de marco teórico. Por otra parte, la retroalimentación mútua entre los viejos y los medios nuevos/digitales debería perfilarse mejor para poder acabar de definir la metodología”.
¿Qué preguntas hacer a los datos pra no desbordarse?
“La metodología es muy robusta y utilizará sobre todo dos grandes fuentes de datos, extensas, objetivas y relativamente fáciles de manipular. En este sentido, el reto será saber qué preguntas hacerles a los datos – de las muchas posibles dada la riqueza de los mismos – para que la investigación no se desborde”.
Falta mayor profundidad en el planteamiento “Sí, los objetivos, las preguntas y las hipótesis son claras y fundamentadas en el debate teórico. Sin embargo, falta una cierta profundidad de planteamiento que se queda en lo descriptivo. Ciertas cuestiones de fondo quedan implícitas o marginadas, como si la polarización es mayor en las redes sociales que en los medios de referencia o si los casos de corrupción preeminentes en ambas esferas (redes digitales y medios convencionales) difieren en cuanto a sus protagonistas. La primera cuestión se relacionaría con las dinámicas de polarización que se atribuyen a la esfera pública digital y la segunda, con el control que se atribuye a las fuentes oficiales en la agenda de los medios convencionales de referencia y a los alineamientos político-edioriales que se han percibido en la prensa española. Se recomienda un mayor énfasis en estas preguntas para facilitar un debate académico que haga aportaciones más allá del caso de estudio nacional que ahora se plantea”.
Falta autores españoles anteriores al año 2000
“La bibiliografía recoge en extenso las principales contribuciones en el orden teórico y empírico, en el plano nacional e internacional. Se echa en falta, sin embargo, el conocimiento y la referencia a obras de autores españoles anteriores del año 2000 y anteriores que abordan el tema de la construcción de la agenda y de los marcos discursivos tanto en la teoría como en análisis de casos”.
Después de unos ajustes al resumen que preparé para el seminario de hace unas semanas he presentado el Abstrac Research Plan a la comisión de doctorado. El cambio principal es centrar o dar más peso al estudio de las redes sociales (social networking sites) en el ecosistema de medios, que son que ha cambiado el panorama de la comunicación en los últimos tiempos. Dentro de “mass media” incluyo “news media” y “social media“. La idea es usar el caso de la cobertura de corrupción para realizar esta investigación.
A finales de mes tengo que presentar el plan de investigación completo (4.500 palabras) así que ya estoy trabajando en ello. A ver cómo este nuevo enfoque me hace reestructurar y escribir lo que tenía hasta ahora.
Mientras, pastpages.org se ha puesto a funcionar para capturar las portadas de los principales diarios online que le pasé a Ben Welsh ¡thank you! No está funcionando del todo bien, no todos los periódicos aparecen etiquetados como “Spain” pero ya va empezando a existir el archivo de periódicos online en España. De momento sólo archiva la imagen de la portada, no el código html. Esa funcionalidad solamente está disponible para ciertos periódicos.
Además, tendré que leer las recomendaciones de Ismael Peña, mi tutor, sobre el tema de la influencia de los social media. Jóvenes clásicos que hay que no he leído todavía que me ayudaran a tratar el tema de la importancia de los medios sociales en la web: hablan del “daily me” en Being digital (1996) de Negroponte, las “echo chambers” en Republic.com 2.0 (2009) o sobre amateurs “Our social tools remove older obstacles to public expression, and thus remove the bottlenecks that characterized mass media” en Here comes everybody: How change happens when people come together (2009) de Shirky.
Pego aquí el abstract que entregué este domingo. Se aceptan y agradecen consejos, sugerencias.
Title: The color of corruption coverage in Spain. Agenda setting in a polarized media ecosystem.
Objectives, hypothesis and questions
By selecting and framing stories mainstream media help determine what is important and what not. Mass media play then a key role in shaping public opinion. Since the seminal article The agenda-setting function of mass media was published in 1972, and specially during the last decade, we have witnessed the emergence and the growth of influence of social media. Social media users (writers/readers) help to disseminate the news, but are also able to participate directly in the selection, creation and framing of the stories to modify the agenda setting traditionally dominated by the mainstream media (Negroponte 1995; Shirky, 2008; Sunstein, 2001). News media remain as key players in mass media ecosystem but they are no longer alone in the way political reality is shaped. How are social networking sites changing the agenda-setting role of traditional media?
How is the dialogue between social networking sites and mass media and how they drive attention to certain stories? We will use the topic of corruption in Spain to study this question.
In the past years, corruption cases in Spain have involved almost every institution in the country. These scandals are usually brought to light by news media and amplified by social media. Every week, a new investigation is unveiled provoking an increasing sense of indignation. As there is a wide range of actors involved in the scandals it makes corruption an appropriate field of research to analyze the role of social media in a polarized media ecology, where Spanish media outlets are traditionally aligned with political parties.
We will research the different variables that shape mass media coverage and public perception such as the main actors involved in a corruption case, the medium where it is published, the publicity given to the story or when it is published. Through the analysis of corruption coverage we are going to measure how news media protect or attack certain parties and institutions by hiding or promoting certain stories. The underlying objective is to update theories about the Spanish partisan media ecosystem.
In a system where people select the newspaper more aligned to their ideology: what comes first, the agenda setting and framing by mass media or the general public predisposition? We are specially interested to see how the situation evolves in a political situation that is shifting from a bipartisan system to a four players game, where new online news sites and networking sites are entering with strength the mass media ecosystem.
Methodology
The unit of analysis of this research are corruption stories in front/home pages of paper and online newspaper newspapers and social media messages in Twitter. We want to measure the importance given by the mass media to certain topics and compare it to the discussion in social media so that we can infer similarities and differences in both their characteristics and determinants.
We will quantify corruption coverage by measuring: the number of news; the size, by using the percentage of surface dedicated to the topic; the “color”, which institution was related to corruption. Informed by other studies and literature in the field of corruption coverage and media studies (Rivero & Fernández-Vázquez, 2011; Baumgartner & Chaqués Bonafont, 2015) we will also study the framing of corruption (Costas-Pérez, Solé-Ollé & Sorribas-Navarro, 2012), whether the coverage is neutral or negative or defensive and giving a positive view.
Whereas front page analysis is not new, we propose the use of new methods to have better and more accurate metrics that take in account size and visual aspect of the analyzed stories. We are going to use PageOneX.com to analyze front pages of paper newspapers and StoryTracker (http://storytracker.pastpages.org/) to analyze home sites of online news sites. Our collection of data can also be compared with other analysis of front pages conducted by the Spanish Policy Agendas project (Chaqués-Bonafont, Palau & Baumgartner, 2014) in the two largest newspapers in Spain: El País and El Mundo.
To analyze social media messages in Twitter we will use the software and data set developed by Mari Luz Congosto at the Universidad Carlos III available at http://t-hoarder.com/. We will quantify conversations about topics by the number of messages, retweets, number of users and the topic they are referred to. We will also analyze user networks and the dissemination of tweets by the mainstream media in Twitter.
To provide related information to our stories data set and in order to measure impact in public opinion we are using two different approaches, existing public opinion surveys and focus groups.
The monthly national survey, “the barometer”, of the Centro de Investigaciones Sociológicas (CIS), that asks about the three more important problems for citizens, where corruption and fraud is since 2013 in the top three.
Focus groups to provide context to understand how people “read” front pages, how they judge about scandals along personal ideologies. We want to contrast data from media coverage with direct perceptions of readers. Participants will be selected to have diverse affinity to political parties and different ideologies. We will use the newspapers front pages of the week as a starting point for a conversation about corruption.
–
Próximamente espero renovar el tema de wodpress de este blog. Stay tuned!
Last semester I took two courses on research methodologies: Advanced Qualitative Methods and Research Design in Social Sciences which lead me to draft a research proposal for my dissertation.
There are a lot of things to talk about: selection of the topic, new areas of research, bibliography, methodology, on line education, why in English… and what it means (and why, how) to make a PhD.
I’ll start with this short presentation I prepared two weeks ago for a seminar at UOC to get some feedback about the research proposal. The following month I have to officially present the research plan.
Abstract
The color of corruption coverage in Spain. Agenda setting in a polarized media system.
In the recent years, the fast-growing list of corruption investigations in Spain have involved almost every institution in the country: the major political parties, the royal house, the main unions, the supreme court or the national bank, just to mention some of them. Everyday, new information and a new case is released/unveiled, provoking an increasing sense of indignation. This situation has pushed up the concern for corruption to the second position of the problems perceived in Spain.
Objectives and questions
The objective of this research is to study how corruption is portrayed in newspapers and analyze how corruption coverage influences public opinion:
to update theories about the Spanish partisan media ecosystem and understand how media outlets are reacting to the new wave of corruption scandals.
to find out if (and how) corruption coverage influences public opinion in order to help readers understand how persuasive is the mass media ecosystem. In a system where people select the newspaper more aligned to their ideology: what comes first, the agenda setting and framing by mass media or the general public predisposition?
to study how is the feedback between social networking sites and mass media regarding corruption coverage and how they drive attention to certain stories?
Methodology
We are going to analyze corruption stories in front pages of paper newspaper and home pages of online newspapers to measure the importance given by the media to certain topics. Whereas front page analysis is not new, we propose the use of new methods (PageOneX.com and StoryTracker software) to have better and more accurate metrics that take in account size and visual aspect of the analyzed stories. We plan to complete our research using existing datasets like opinion surveys and databases of social networking sites, like Twitter. Social networking sites are another key element to analyze the influence of mass media in the public agenda and to help understand the triangle media, politics and public opinion.