En el mes de Marzo de 2018 eldiario.es sacó a la luz irregularidades en el caso del máster de la entonces presidenta de la Comunidad de Madrid Cristina Cifuentes. Para tener más contexto puedes escuchar el magnífico podcast sobre el escándalo que publicó eldiario.es.
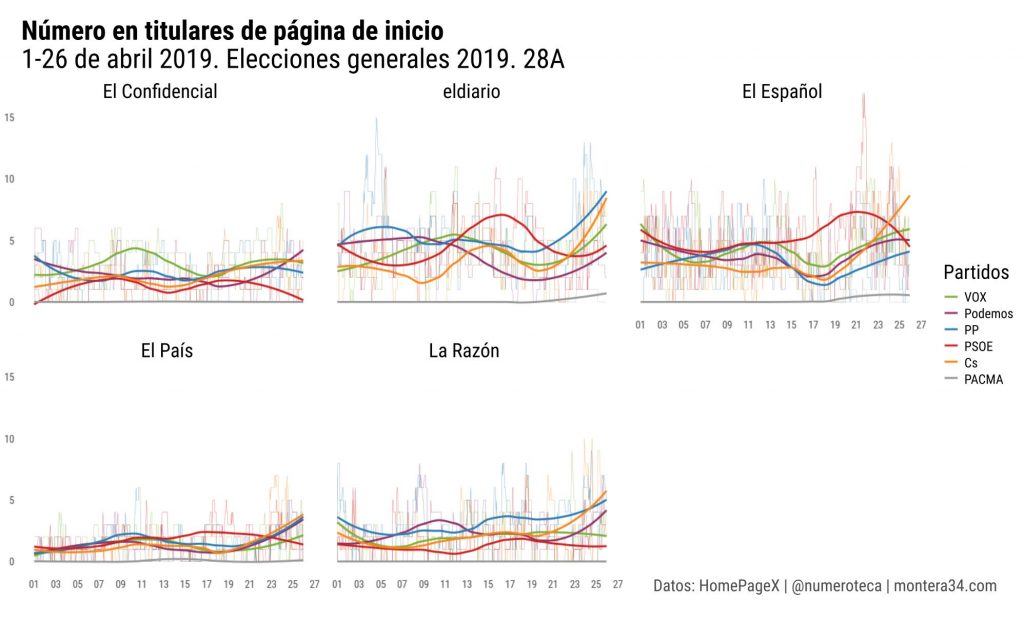
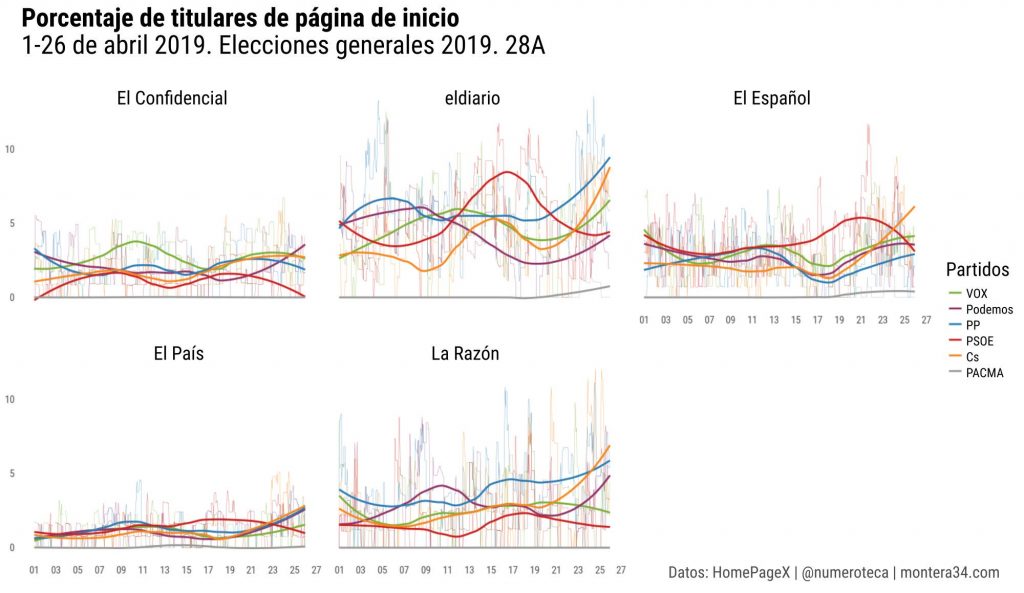
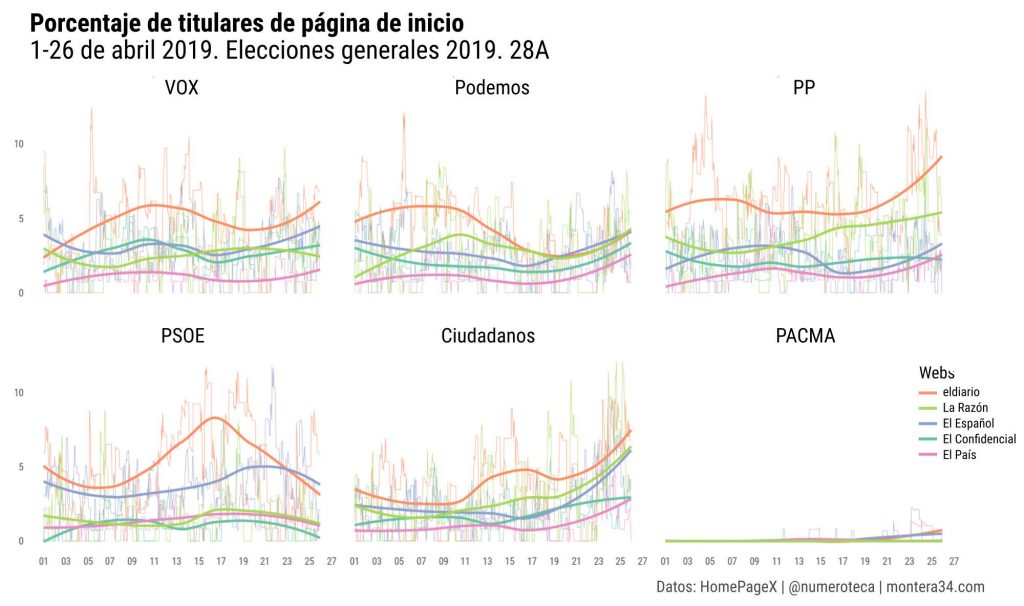
En esta serie de posts analizaremos cuantitativa y cualitativamente la cobertura que se le dio al escándalo en diferentes medios de comunicación y redes sociales para intentar entender cómo es el flujo de información entre unos canales y otros.
Estos textos forman parte de la investigación para mi tesis doctoral sobre cobertura de corrupción en España. En su momento ya analicé la cobertura en las portadas de los periódicos en papel.
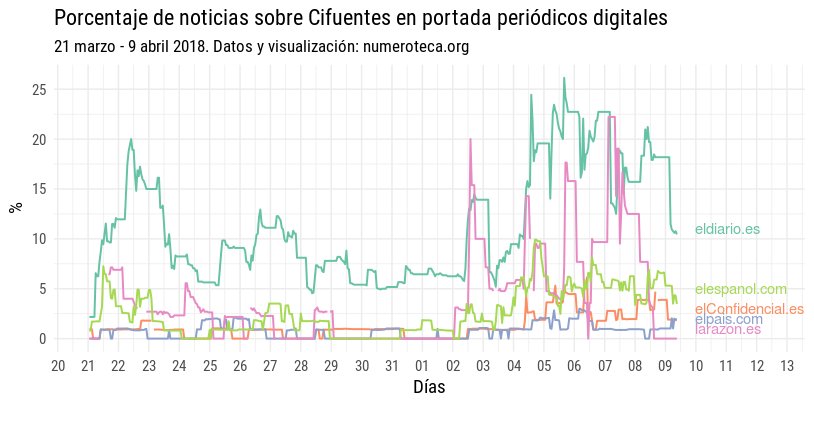
Hoy analizo las noticias sobre lo que se ha venido a conocer como el caso “Máster” en una nueva base de datos: los Telediarios de Televisión Española que Civio pone fácil estudiar con su herramienta Verba (https://verba.civio.es/).
Verba permite hacer búsquedas por palabras en las transcripciones de los telediarios de TVE y descargar los datos. La unidad de medida es la frases que contiene tal o cual palabra.
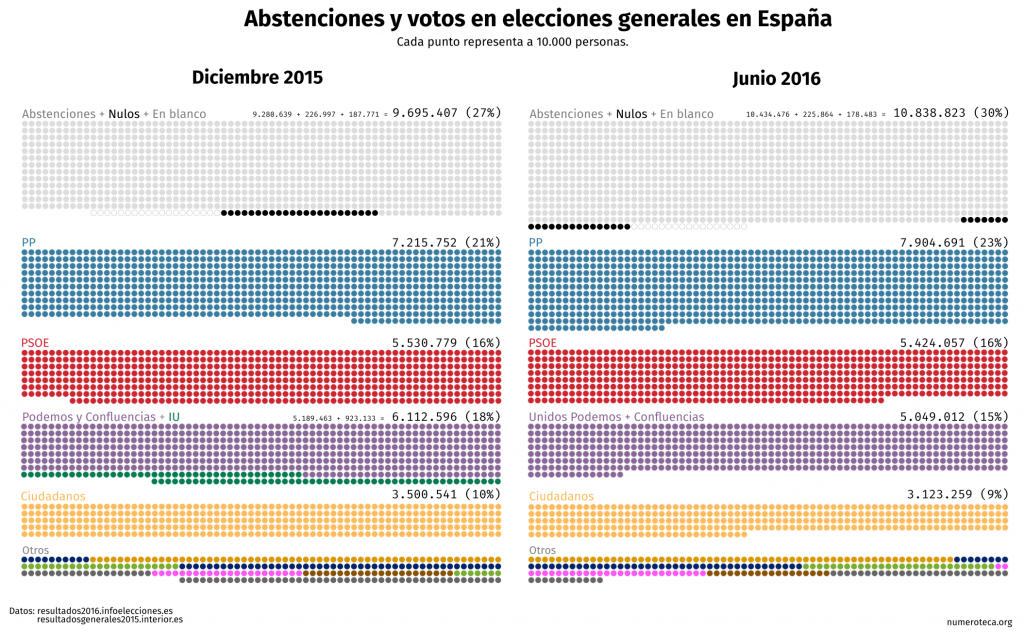
No centraremos ahora en cuando estalló el escándalo, el 21 de marzo de 2018. El resultado es fruto buscar en Verba tras la búsqueda multipalabra para ese periodo concreto: “Cifuentes”|”Javier Ramos”|”Enrique Álvarez Conde”|”Pablo Chico”|”María Teresa Feito”|”Alicia López de los Cobos”|”Cecilia Rosado”|”Clara Souto|Amalia Calonge”|”Universidad Rey Juan Carlos”.
Los gráficos están hechos con VerbaR, unos scripts de R que he desarrollado para analizar con R datos de Verba. Cada línea negra es una frase que incluye una de las palabras de la búsqueda:

El gráfico está dividido en una parte de arriba, para los telediarios de las 15:00h y la de la abajo, para los de las 21:00h. He marcado los primeros dos minutos para enfatizar la cabecera o “portada” del noticiario. No tengo claro todavía cuánto dura este inicio con las noticias más destacadas.
Aquel 21 de marzo, tras salir publicado el escándalo en eldiario.es el Telediario de las 15:00h se hizo eco de la noticia en su apertura:
- 1’18”: La Universidad Rey Juan Carlos atribuye a un error de transcripción que en dos asignaturas del máster que Cristina Cifuentes cursó hace seis años figurase como no presentada.
- 1’28”: Cifuentes aprobó ambas asignaturas, según ha confirmado el rector.
Más adelante expandía la noticia ne el minuto 14:
- 14’56”: En Madrid, la universidad Rey Juan Carlos niega cualquier irregularidad en el máster de la presidenta Cristina Cifuentes.
- 15’03”: Un diario digital sostiene que obtuvo la titulación con dos notas falsificadas.
Verba ofrece la posibilida de acceder a la transcripción completa y no solamente a las frases resultado de la búsqueda-
En el gráfico se puede ver cómo en ese primer día hay dos bloques de información: el del resumen inicial, esos 2 ó 3 minutos -estaría bien poder cuantificarlo- y cuando se amplia la noticia. Esa cabecera viene a ser análoga a la portada de los periódicos, donde se seleccionan las noticias más importantes.
El problema de la búsqueda por palabras es que se deja fuera las frases que no contienen las palabras buscadas pero que pertenecen a la noticia, por ello esos existen huecos en los gráficos entre unas líneas y otras. Por ejemplo, la noticia en cabecera duraba más, pero se quedó fuera de nuestra búsqueda:
- 1’31”: La oposición pide explicaciones.
- 1’34”: El Gobierno regional subraya la honorabilidad del comportamiento de la presidenta.
En el gráfico se ha sobredimensionado la duración de las frases asignándoles 30 segundos de duración para facilitar su lectura.
Si pudiéramos distinguir los bloques de noticias, cuando empieza un tema y acaba otro, podríamos ver algo como esto, donde coloreo “a mano” en rojo la posible duración del total de las noticias relacionadas con el máster:
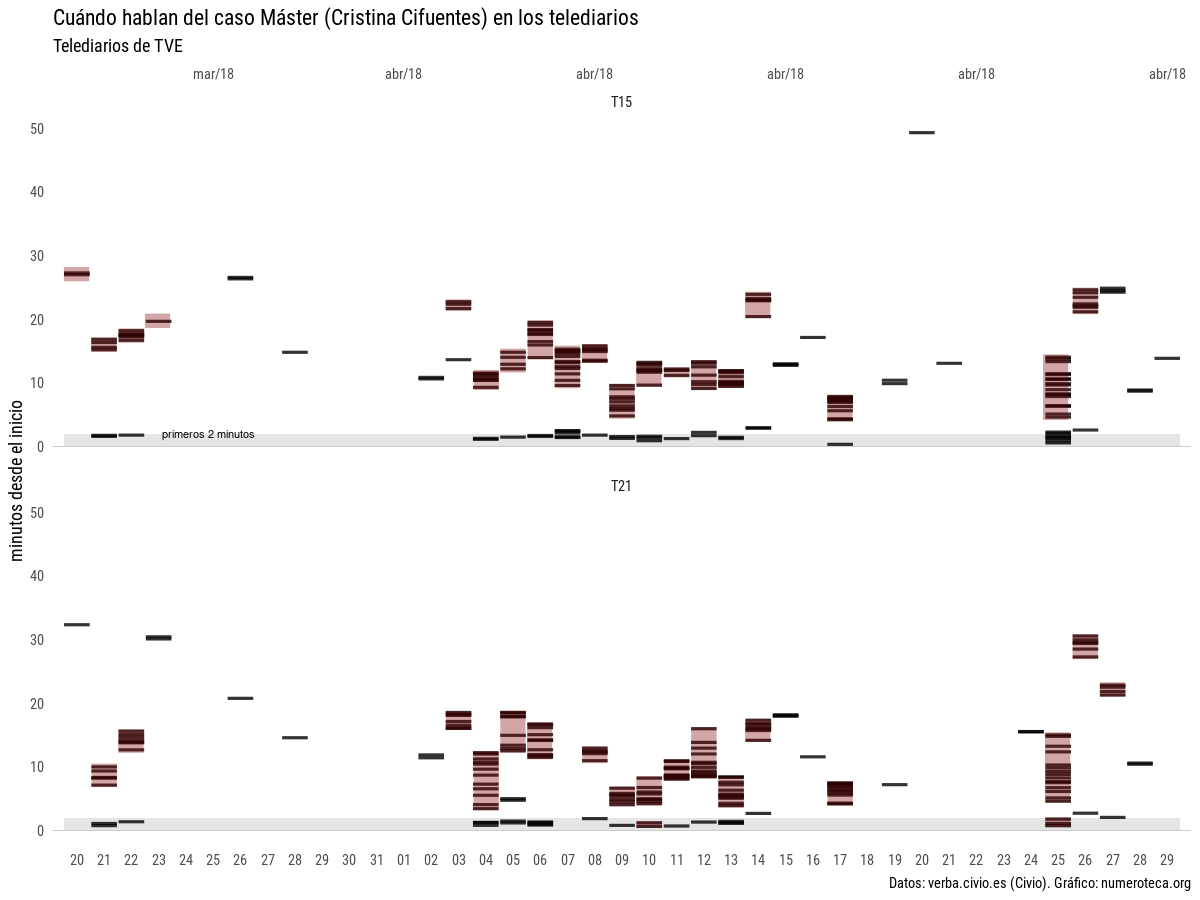
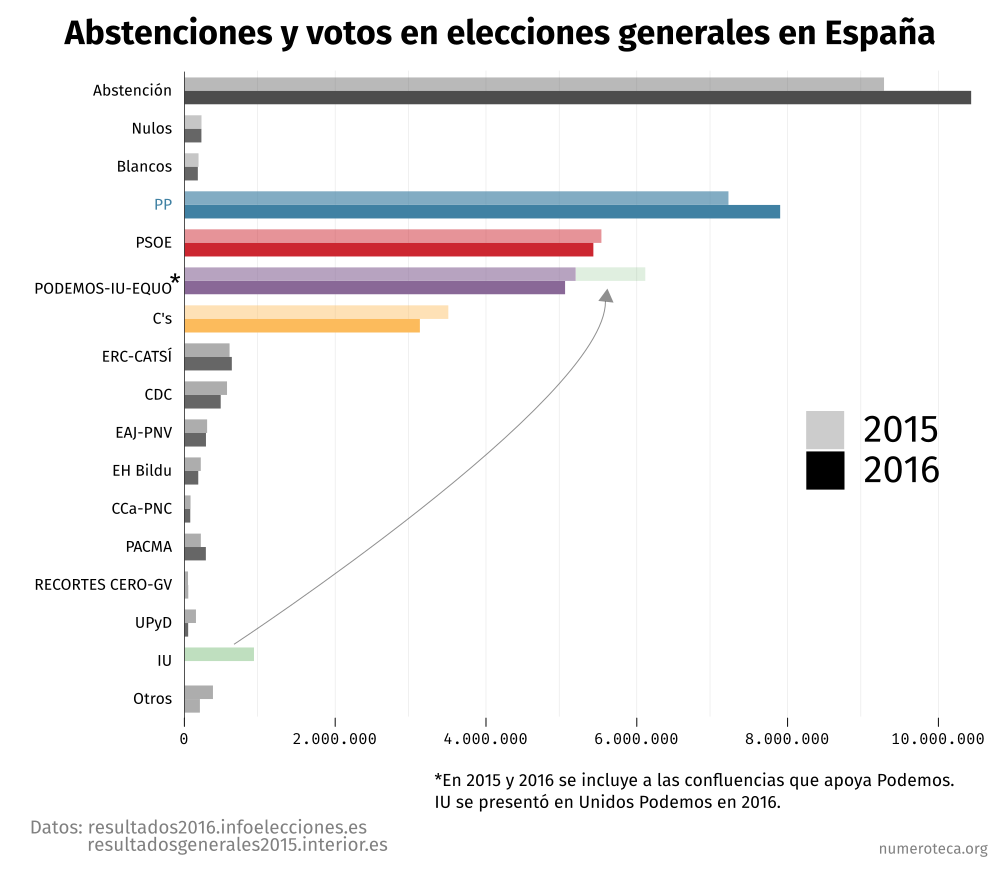
Este otro gráfico visualiza el número de frases que contienen las palabras clave. Suma todas las frases encontradas y las agrega en una columna:

Nos da una idea aproximada de la evolución de la cobertura. Sería interesante poder clasificar esta información según los días que la noticia ha estado en la cabecera del telediario y poder así estudiar la relación de tiempo de frases dedicadas a la noticia con su aparición en el resumen de inicio. También sería interesante conocer la duración de la noticia, y no únicamente el número de frases encontradas.
Si volvemos a hacer el primer gráfico clasificando manualmente las frases seleccionadas, podemos entender mejor la historia: primero salta la noticia sobre el master (“máster” en verde) , vuelve a aparecer a primeros de abril con fuerza, con 10 días seguidos con noticia en cabecera en el telediario de las 15:00h y se cierra con la dimisión el 26 de abril, tras el nuevo escándalo del vídeo sobre el robo de las cremas en un supermercado:
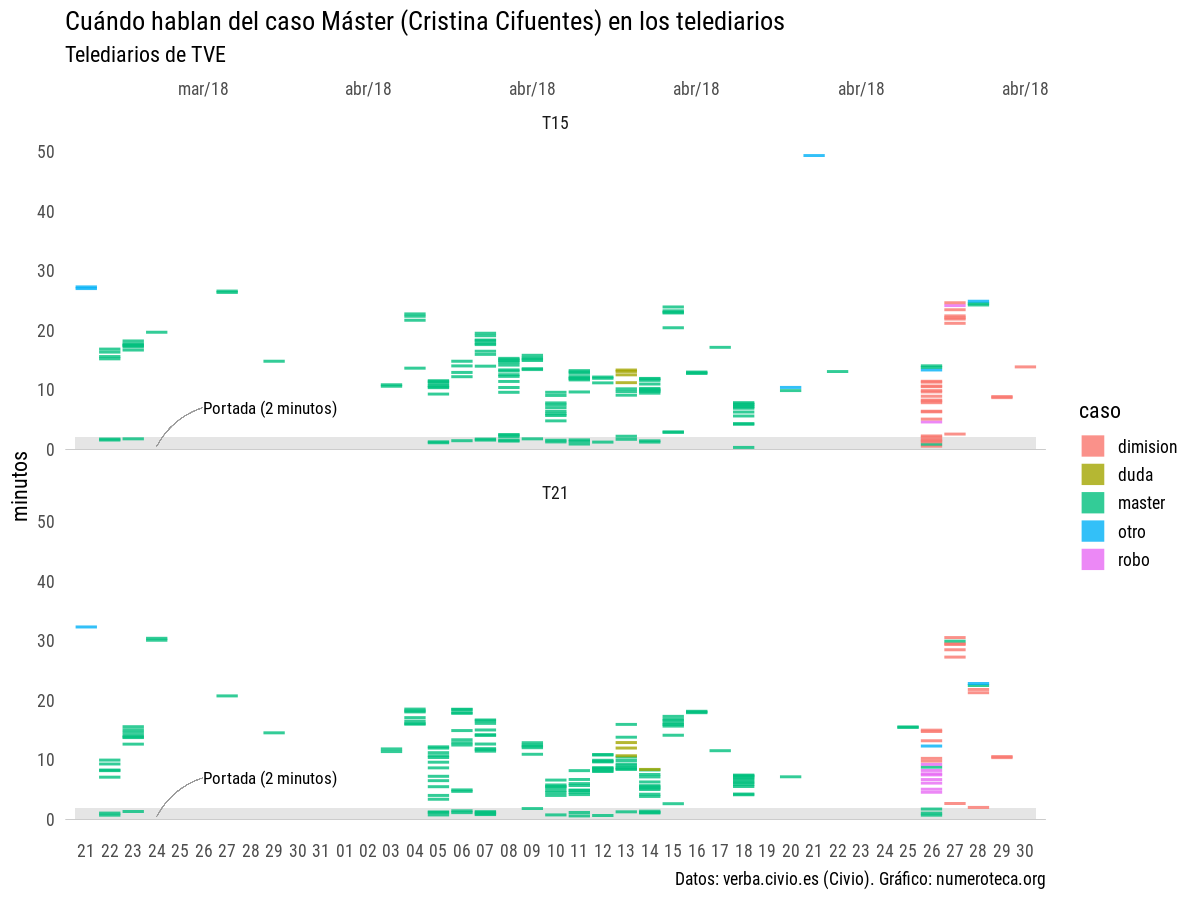
Podemos ver estos mismo datos agregados en columnas:

Este primer análisis nos permite ver la potencia y las limitaciones de este tipo de visualizaciones:
- las palabras clave de búsqueda son determinantes
- es necesario reclasificar la información para poder analizar en profundidad la evolución de la cobertura. Otras variables a analizar serían el enfoque de las noticias.
¿Cómo de relevante fue la cobertura de TVE en relación a otros medios de comunicación o redes sociales como Twitter? Lo veremos en los siguientes capítulos.
He creado una aplicación con Shiny para poder generar gráficos de este tipo y analizar más rápidamente las diferentes búsquedas en Verba: [actualizción: mejor esta versión: https://r.montera34.com/users/numeroteca/verbar/app/] https://numeroteca.shinyapps.io/verbar/
Gracias a que es interactiva puedes ver que contiene cada frase.
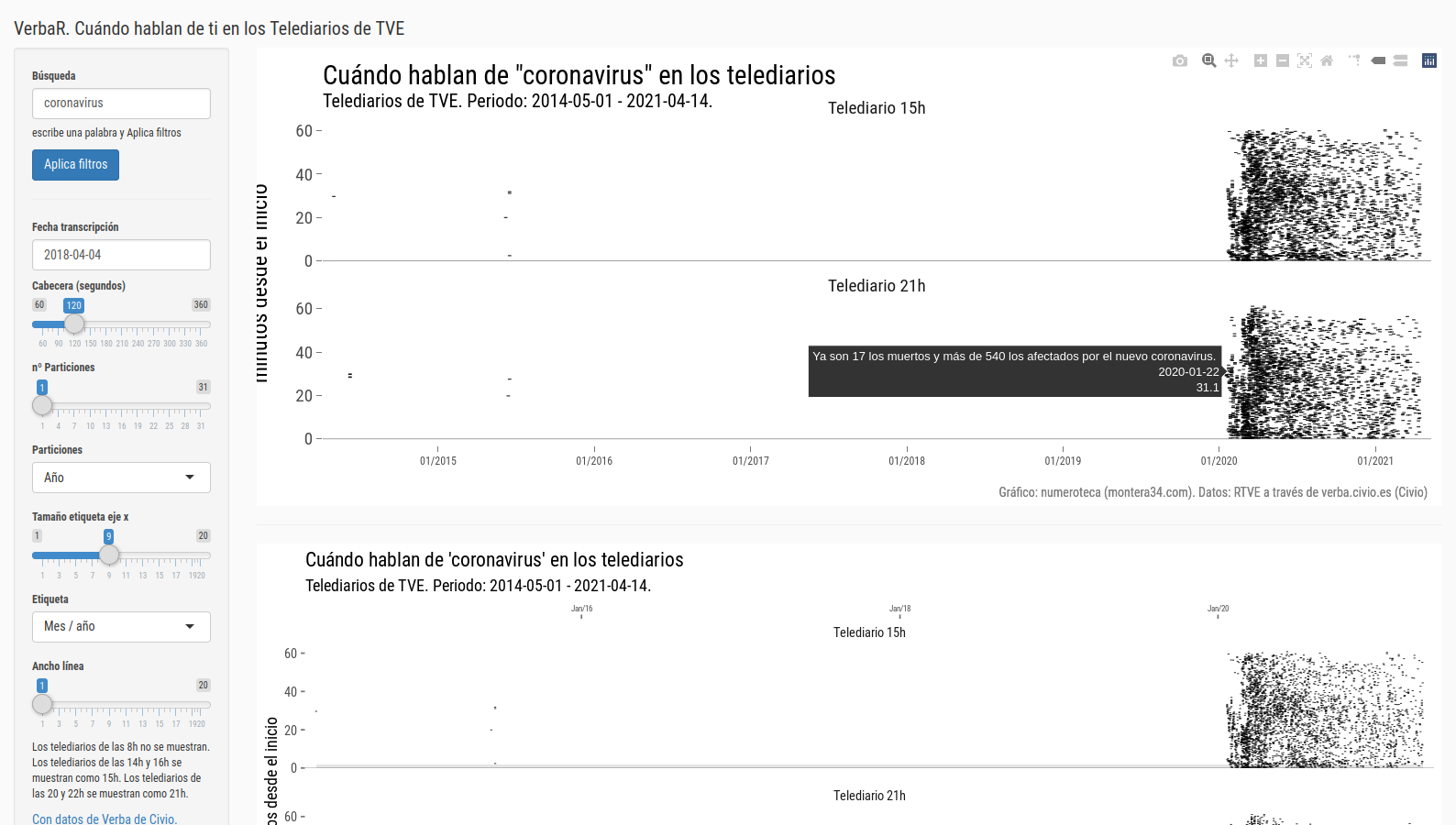
Hay una opción que te permite seleccionar una fecha y ver todas las frases de ese día.







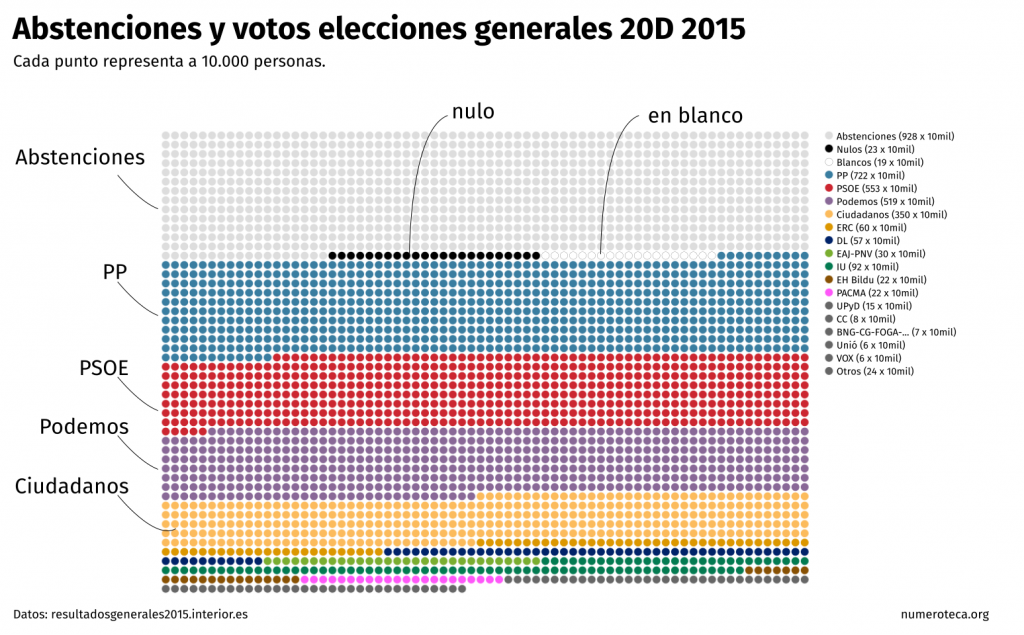
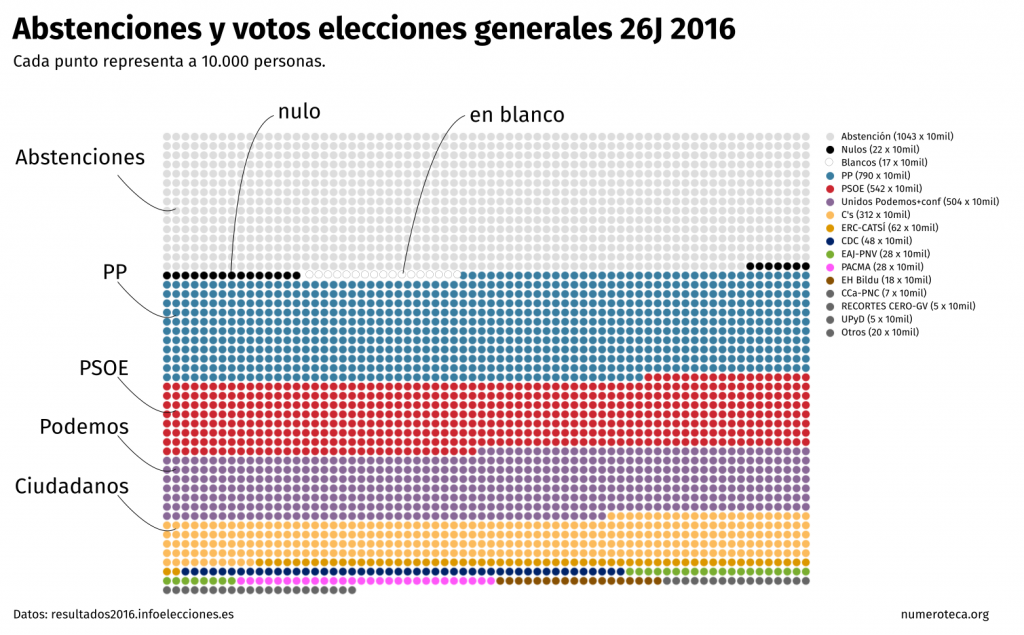
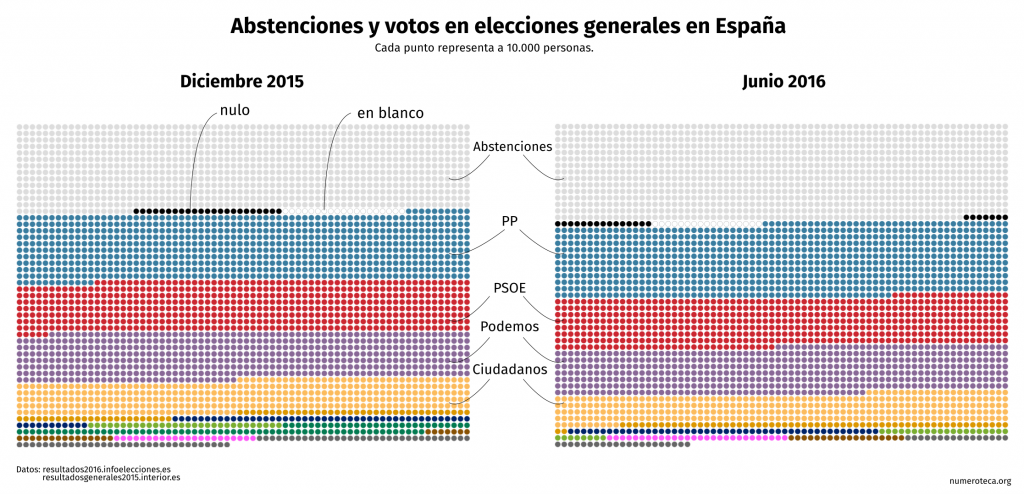
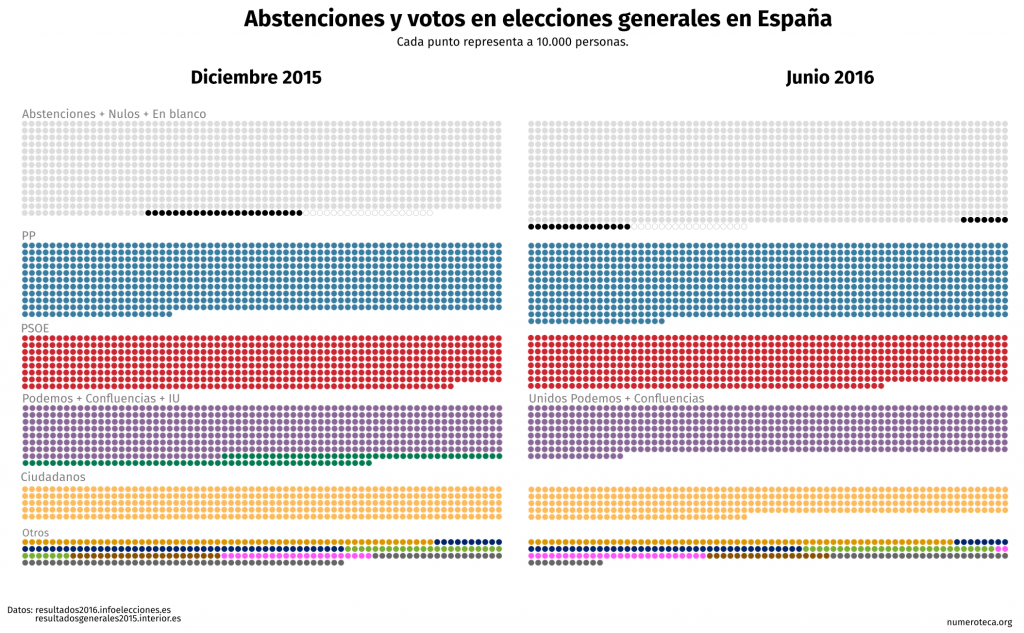

")


{kind=link}