0. ¿De verdad no hay una forma sencilla de buscar en las actas de los plenos municipales?
Te ha pasado. Bueno, hagamos como si te hubiera pasado.
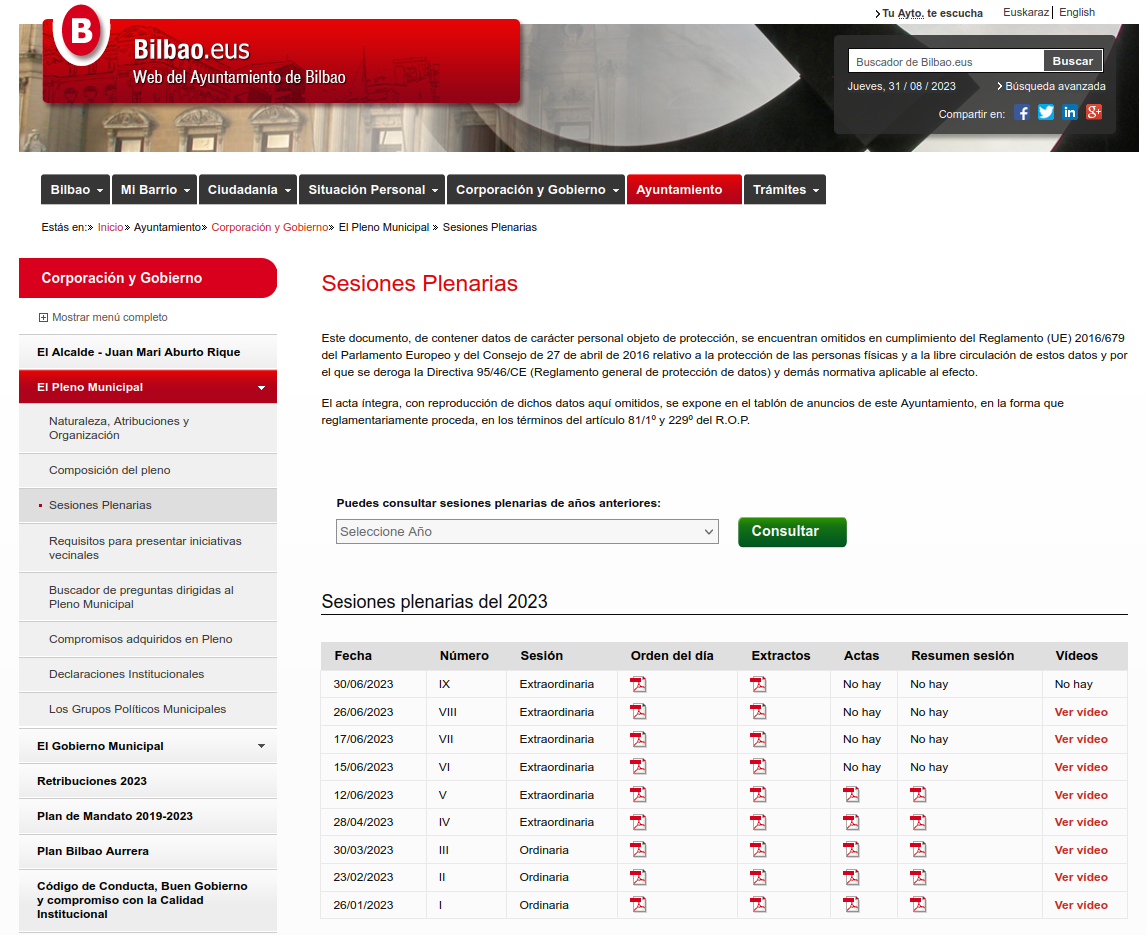
Quieres saber cuándo, en el pleno de tu ayuntamiento, han hablado de tal o cuál tema. Vas a la web del ayuntamiento y tras un rato navegando encuentras la página ¡bingo!
Una URL maravillosamente larga: https://www.bilbao.eus/cs/Satellite?c=Page&cid=3000015482&language=es&pageid=3000015482&pagename=Bilbaonet%2FPage%2FBIO_ListadoSesionesPlenarias.
Puedes acceder a las actas en PDF. Todo bien.
Basta ahora con descargarlas una a una, abrir cada documento y buscar. Puede resultarte algo tedioso. Lo haces para el 2023, pero cuando llegas a 2022 ya te cansas ¿no existe una manera mejor para poder buscar en todas las actas? Y si las tuvieras descargadas ¿cómo buscar en todas ellas?
En la web del ayuntamiento hay disponibles actas de los plenos desde noviembre de 2007, pero descargarlas todas te llevaría más tiempo del que dispones. Son 193 a día de hoy (y eso sin contar con los extractos de las actas, que están disponibles desde 2002).
Las actas están ahí. Están publicadas. Cualquiera puede acceder a elllas. Otra cosa es que alguien tenga el tiempo para descargarlas y analizarlas.
¡Este es un caso para Abrir Datos Abiertos!
No es la primera vez que me pasa. Tener la información al alcance y no poder procesarla, porque no está publicada de una forma que pueda ser fácilmente consumida. Requiere demasiado trabajo.
Así que me puse manos a la obra.
Lo primero es 1) obtener la lista completa de actas; luego 2) descargar todos los PDF; y por último3) procesar todos los textos para poder hacer búsquedas.
1. Scraping
Para lo primero hace falta “escrapear” (de scraping, en inglés), esto es, descargar sistemáticamente la información de la web. Para ello le pregunté a Ekaitz si se le ocurría algo, porque el escrapeado no era imposible, pero tampoco trivial. En unas horas me mandó este código de python, que sirve para genera un archivo JSON que contiene la lista y URL de todos los documentos para poder descargarlos:
# Copyright 2023 Ekaitz Zárraga <ekaitz@elenq.tech>
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import requests
from bs4 import BeautifulSoup
from urllib.parse import urlparse, urljoin
import json
if __name__ == "__main__":
base_url = urlparse("https://www.bilbao.eus/cs/Satellite?c=Page&cid=3000015482&language=es&pageid=3000015482&pagename=Bilbaonet%2FPage%2FBIO_ListadoSesionesPlenarias")
r = requests.get(base_url.geturl())
soup = BeautifulSoup(r.text, "html.parser")
years = { i.text: i["value"] for i in soup.select("select#anioId option[value]") if i.text.isdigit()}
data = []
for year, id in years.items():
r = requests.post(base_url.geturl(), {"anioId": id})
soup = BeautifulSoup(r.text, "html.parser")
table = soup.find('table', class_='tablalistados')
headers = [ th.text.strip() for th in table.find("tr").find_all("th") ]
data_rows = table.find_all("tr")[1:]
print(year)
for data_row in data_rows:
line = { k: v for k, v in zip(headers, data_row.find_all("td"))}
line["Fecha"] = line["Fecha"].get_text().strip()
line["Número"] = line["Número"].get_text().strip()
line["Sesión"] = line["Sesión"].get_text().strip()
# Los que tienen archivo: guardar enlace (luego se puede hacer un GET)
for field in ["Orden del día", "Actas", "Resumen sesión", "Extractos", "Vídeos"]:
link = line[field].find("a")
url = urlparse(urljoin(base_url.geturl(), link["href"])) if link else None
line[field] = url.geturl() if url else None
data.append(line)
with open("plenos.json", "w") as f:
f.write(json.dumps(data))¡2) Descargar los PDF
Para eso me fui a R, que es donde me encuentro más cómodo para trastear. Este archivo de R lee el JSON descargado, descarga todos los PDF y genera un archivo CSV en el que en cada línea guarda: el texto contenido en una página de cada PDF, el número de página, la URL al PDF original del acta y la fecha del pleno municipal.
# Cargar librerías
library(tidyverse)
library(pdftools)
library(tm)
library(rjson)
# Genera archivo .json con el código de plenos.py
# Archivo descargado plenos_230823.json
# Segundo archivo, en vista de que han cambiado las URL
data <- fromJSON(file= paste0("data/original/plenos_230823.json") )
# Apana (flat) el archivo json para operar más fácilmente --------
for( i in 1:length(data) ) {
print(i)
# for( i in 1:2 ) {
fecha <- data[[i]]$Fecha
num <- data[[i]]$Número
sesion <- data[[i]]$Sesión
orden <- data[[i]]$"Orden del día"
extractos <- data[[i]]$Extractos
actas <- data[[i]]$Actas
resumen <- data[[i]]$"Resumen sesión"
video <- data[[i]]$Videos
if( is.null(orden) ) { orden = NA }
if( is.null(extractos) ) { extractos = NA }
if( is.null(actas) ) { actas = NA }
if( is.null(resumen) ) { resumen = NA }
if( is.null(video) ) { video = NA }
if ( i == 1 ) {
plenos <- data.frame(fecha = fecha, num = num, sesion = sesion, orden =orden, extractos = extractos, actas = actas, resumen = resumen, video =video)
} else{
plenos <- rbind( plenos,
data.frame(fecha = fecha, num = num, sesion = sesion, orden =orden, extractos = extractos, actas = actas, resumen = resumen, video =video)
)
}
}
# Format date (pon en formato fecha)
plenos <- plenos %>% mutate(
fecha = as.Date(fecha, format="%d/%m/%Y")
)
# Descarga los PDF - Download ----
for( i in 1:nrow(plenos) ) {
# for( i in 1:22 ) {
print(plenos$actas[i])
if ( !is.na(plenos$actas[i]) ) {
print(plenos$fecha[i])
#Descarga el archivo
download.file(plenos$actas[i],
paste0("data/output/actas_230823/",plenos$fecha[i],"_acta_pleno-municipal-bilbao.pdf"))
}
}
# Read pdf -------
# Guarda el resultado de cada página en una celda, junto con fecha y número de página
for( i in 1:nrow(plenos) ) {
print( paste(i,"fila"))
print(plenos$fecha[i])
if ( !is.na(plenos$actas[i]) ) { # Que exista el acta
text <- pdf_text(paste0("data/output/actas/",plenos$fecha[i],"_acta_pleno-municipal-bilbao.pdf"))
if ( i == 5 ) { # TODO: Para el primer pleno que tiene acta (metido a mano, mejorar!) en este caso el 5
for( j in 1:length(text)) { # itera por todas las páginas de cada pdf
print( paste("row:", j, " ----------------------------------"))
if( j == 1) { # Para la primera iteración
print("j es 1")
all_pages <- text[j] %>% as.data.frame() %>% rename( txt = 1) %>% mutate(
pag = j,
fecha = plenos$fecha[i],
actas = plenos$actas[i]
)
} else (
page = as.data.frame(text[j]) %>% rename( txt = 1) %>% mutate(
pag = j,
fecha = plenos$fecha[i],
actas = plenos$actas[i]
)
)
if( j != 1) {
all_pages = rbind(all_pages, page)
}
}
} else {
for( j in 1:length(text)) { # itera por todas las páginas de cada pdf
if( j == 1) {
print("4")
all_pages_temp <- text[j] %>% as.data.frame() %>% rename( txt = 1) %>% mutate(
pag = j,
fecha = plenos$fecha[i],
actas = plenos$actas[i]
)
} else (
page = as.data.frame(text[j]) %>% rename( txt = 1) %>% mutate(
pag = j,
fecha = plenos$fecha[i],
actas = plenos$actas[i]
)
)
if( j != 1) {
all_pages_temp = rbind(all_pages_temp, page)
}
}
all_pages = rbind(all_pages, all_pages_temp)
}
} else {
print("No existe acta")
}
}
# salvar archivo como CSV
write.csv(all_pages, "data/output/paginas-actas-plenos_230823.csv")3. Página para buscar
A partir del CSV generado en el paso anterior monte un buscador básico (sólo se puede buscar por una palabra) desarrollado en PHP (ver código):
lab.montera34.com/plenosbilbao
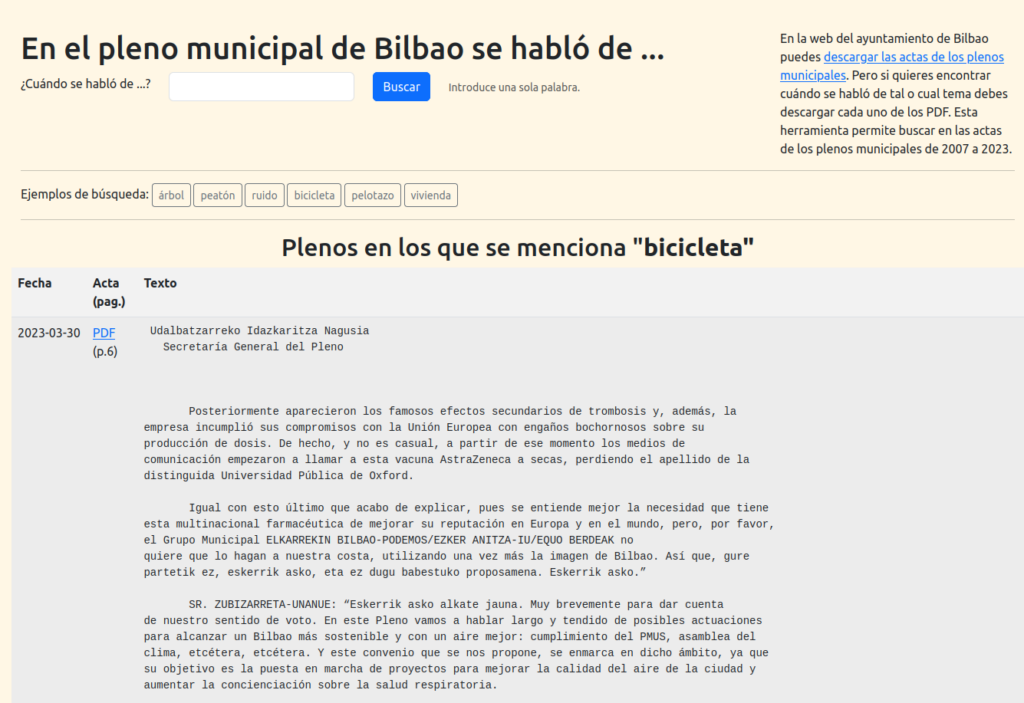
¿Qué le sobra, qué le pasa, qué le falta a esta web? ¿os resulta útil? ¿cómo podíais vivir sin ella? ¿encontrais algo interesante? Encantados de escucharos.
Bola extra: si has llegado, quizás te interesa la web que he montado para buscar en las ordenanzas del ayuntamiento de Bilbao u otros proyectos de abrir datos abiertos que hemos hecho desde Montera34.