Este post es parte de la serie “Investigación colaborativa, divertida, barata, transmedia. Otras formas de entender la investigación” publicada a modo de cruce de posts entre numeroteca.org y voragine.net. Este trabajo se enmarca dentro de un estudio sobre Investigación en red coordinado por Mayo Fuster Morell parte de un proyecto más amplio sobre Juventud, Internet y Política bajo la dirección de Joan Subirats en el marco del grupo IGOPnet.cc, con la colaboración de Montera34, para la Fundación Museo Reina Sofía sobre adolescencia y juventud. #otrainvestigación es el hashtag.
#OccupyData Hackathon
Uno de los grupos de trabajo de los que formaba parte dentro de Occupy Research, red abierta y distribuida de investigación, que comentaba en la anterior entrega fue Data and Visualization, que consistía en recopilación de datos sobre el movimiento Occupy y tratar de visualizarlos. Como contaba el resumen de este apartado en la wiki de Occcupy Research cuando interactuamos en redes sociales en Internet dejamos una huella en forma de datos. Muchos de esos datos son esos registros a los que hacía referencia Alfonso en la entrega anterior, Investigar sin darse cuenta: archivos personales: dominios que visitamos, términos de búsqueda, y también los más obvios y visibles como tuits, estados de Facebook, “me gustas” que más tarde pueden ser recogidos y analizados. Este análisis lo pueden hacer las empresas en Internet para ofrecernos conocer mejor a los usuarios y proporcionar publicidad más personalizada para así obtener más beneficios. Pero también, como está destapando el caso Snowden sobre la Agencia Nacional de Seguridad (NSA) de EE.UU, las agencias de inteligencia de los estados pueden obtener información de las redes sociales, tanto datos oficialmente públicos como los supuestamente privados, para estudiar el comportamiento de los ciudadanos según su actividad en Facebook, skype o emails.

Occupy Data trataba de obtener y utilizar esos datos que vamos dejando en las redes sociales para aprender sobre el movimiento Occupy visualizando la información de forma inteligible. Había gente interesada en compartir diferentes métodos de obtención de datos (entrevistas en las acampadas, scrapers que descargaban datos atomáticamente), y otros en compartir bases de datos que habían generado. Nos llegó una base de datos de un particular que había recopilado por su cuenta información relacionada con cada uno de los nodos de Occupy: sus cuentas de Twitter, Facebook, dirección física, teléfono, email… todo un ejemplo de investigación no distribuida pero de gran calidad.
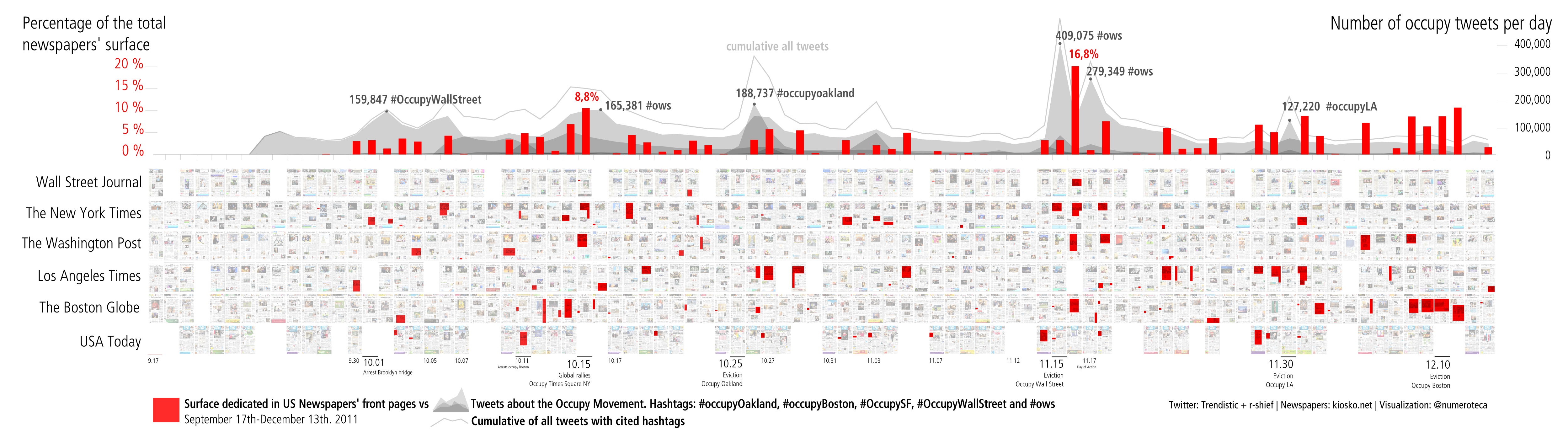
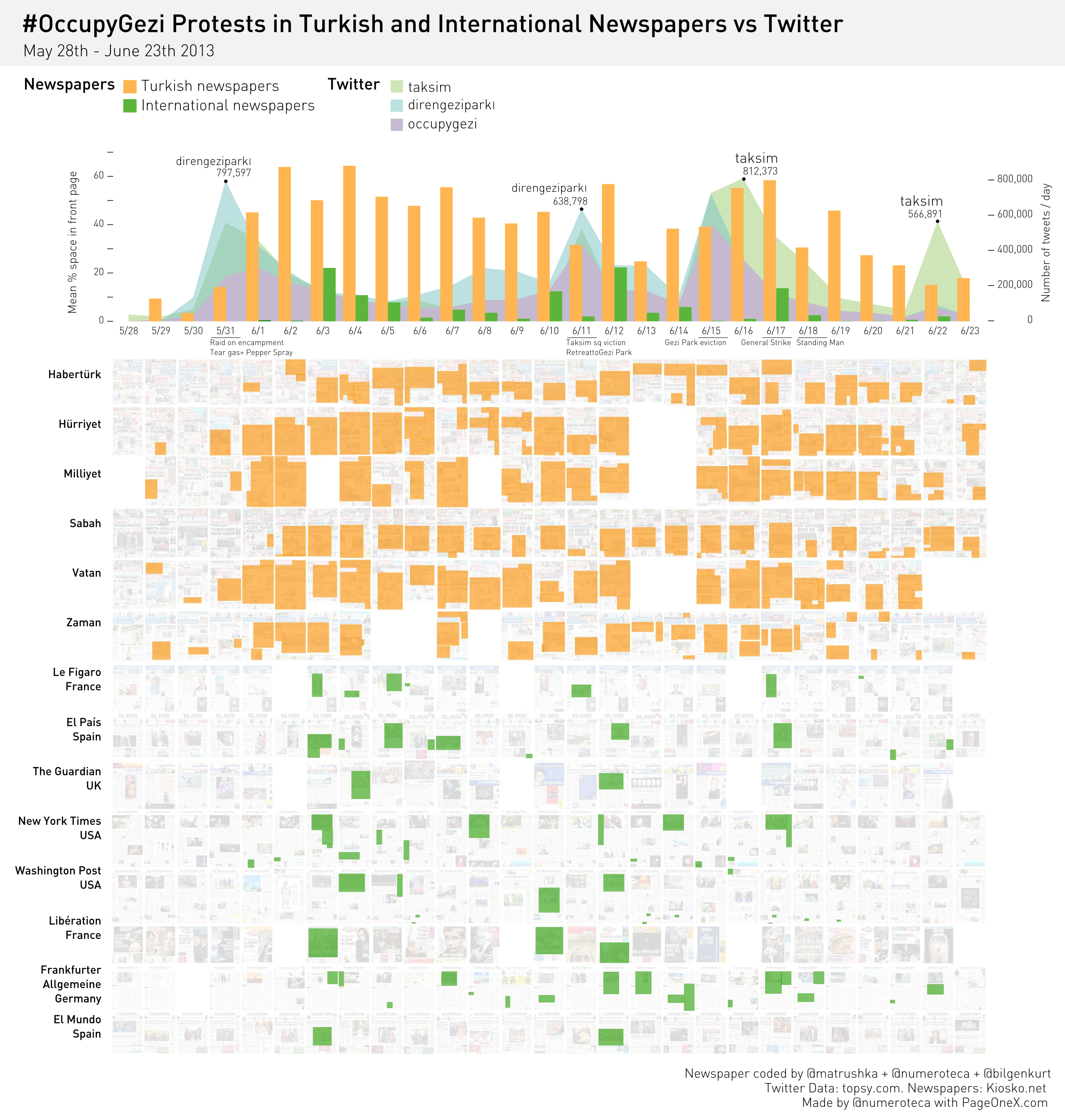
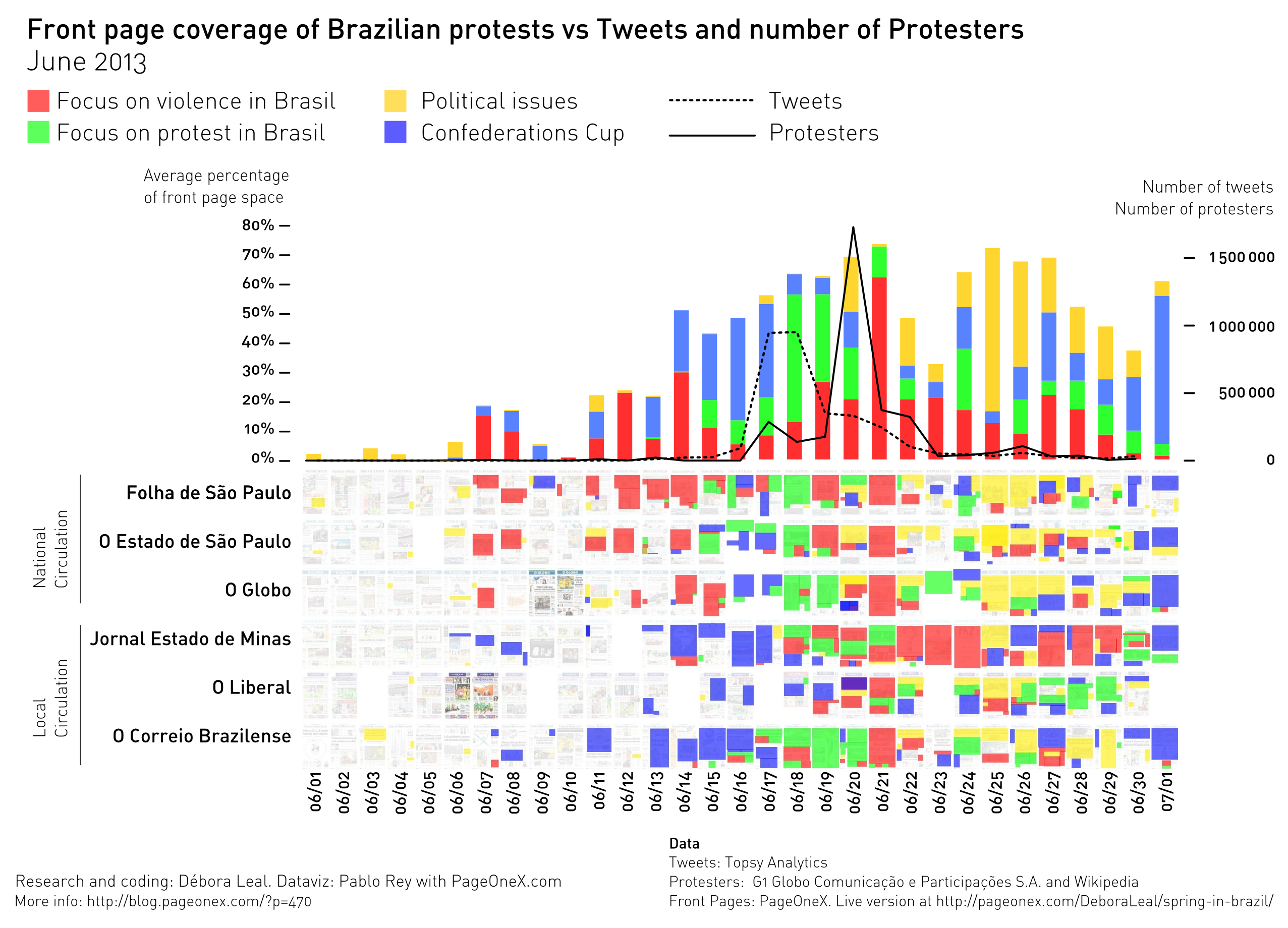
A raíz del anuncio de publicación de un archivo de varios millones tuits sobre Occupy, que la organización R-Shief (r-shief.org) había recopilado, organicé junto con Sasha Costanza-Chock, profesor del MIT y co-director del Center for Civic Media, un hackathon desde Occupy Research para analizarlos colectivamente y hacer visualizaciones. Se trataba de un evento deslocalizado y pensamos que era una buena oportunidad para juntarnos y crear colectivamente. #OccupyData hackathon iba a ocurrir simultáneamente en diferentes ciudades del mundo los días 9 y 10 de diciembre de 2011.
Un Hackathon, que viene de Hack y Marathon, es un evento en el que durante poco tiempo se juntan varias personas para desarrollar intensamente un proyecto, habitualmente de software. En esta ocasión se partía de varios millones de tuits que contenían hashtags relacionados con occupy (#occupy, #OccupyWallSt, #OccupyBoston, #OccupyOakland, etc.). Un hashtag es la forma de etiquetar el contenido de un tuit. La palabra que sirve de etiqueta, el hashtag, debe estar precedida del símbolo “#”. Si el usuario hace click en ella puede ver el resto de mensajes que otros usuarios han publicado con esa etiqueta.
El hackathon empezó exponiendo a los participantes con qué datos contábamos para pasar rápidamente a una lluvia de ideas sobre qué hacer con ellos. Entre todos evaluamos las diferentes propuestas que habían quedado dibujadas en la pizarra para decidir cuáles podíamos llevar a cabo, dado el tiempo y las capacidades técnicas de las que disponíamos. Cada cierto tiempo había preparadas conexiones por videoconferencia (Google Hangout) con otras ciudades para compartir avances y exponer los prototipos generados.
Compartir espacio físico durante unas horas o unos días es un buen método para forjar alianzas y conocerse. Puede dar pie a que los proyectos tengan recorrido más allá del tiempo programado del hackathon. Como comentaba Charlie DeTar, doctor por MIT Media Lab y colega del Center for Civic Media, un hackathon es un buen método para concentrar creatividad multidisciplinar e inspiración en un corto periodo de tiempo, a la vez que puede ayudar a atraer la atención sobre un determinado tema.
OccupyTweets: de la idea al programa en dos días
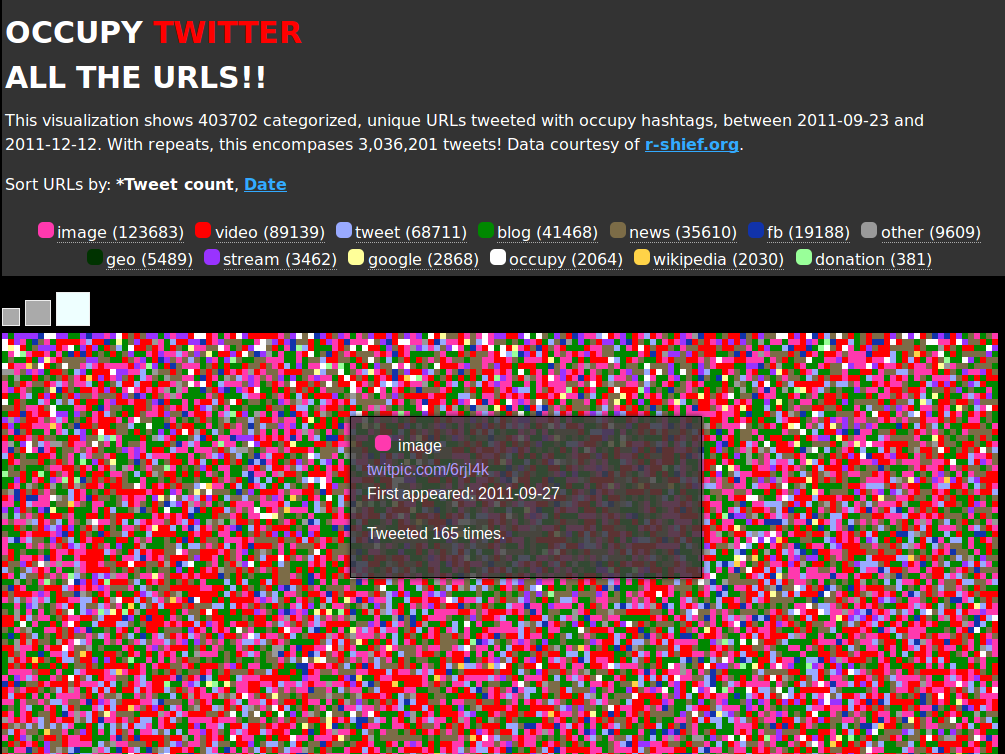
Una de las propuestas de esa lluvia de ideas inicial era clasificar y cuantificar visualmente los enlaces (las url) contenidos en los tuits. En vez de analizar las palabras del mensaje nos queríamos centrar en las url, la mayoría de las veces indicativo de dónde quería fijar la atención el usuario que enviaba o retuiteaba un mensaje. Pensamos que clasificando cada uno de esos enlaces por tipo de página web enlazada, podíamos entender qué sitios en internet estaban teniendo más importancia dentro de la temática occupy.
La primera dificultad técnica era ‘extraer’ las url de los mensajes, ya que en Twitter los enlaces aparecen acortadas (con url’s como t.co, o bit.ly) para ahorrar espacio de los limitados 140 caracteres que permite cada mensaje. Así una dirección como “http://www.ustream.tv/channel/occupy-chicago” está insertada en el tuit como tiny.cc/b7f6h, y a su vez acortda como http://t.co/mjoQVsQr. Para poder clasificar las url necesitamos obtener los enlaces originales.
Una vez resuelto este paso había que clasificar las url y para ello creamos una serie de categorías. Las que más se repitieron fueron: imágenes (123.683 veces), vídeos (89.139), Twitter (68.711), blogs (41.468), noticias (35.610), facebook (19.188), video stream (3.462), Google (2.868), sitios web de occupy (2.064), Wikipedia (2,030) y a campañas de donaciones (381).
Una primera versión, en la que usamos solamente los tuits sobre #OccupyBoston para probar el sistema, estuvo disponible el segundo día por la noche, al terminar el hackathon. Para entonces ya habíamos publicado un post explicando lo que queríamos hacer, un vídeo de cómo lo hacíamos y otro explicando el resultado obtenido. El código estaba disponible también online: se trataba de hacer herramientas que otros investigadores también pudieran usar y modificar.
Si todo el proceso está bien documentado, diferentes personas pueden colaborar en su desarrollo aportando su conocimiento y capacidades en diferentes momentos del mismo. Una documentación de calidad convierte un proyecto en verdaderamente abierto, especialmente si se trabaja deslocalizadamente, pero también si se está en un mismo lugar físico.
En un breve lapso de tiempo, tan solo dos días, habíamos podido ir de un borrador en una pizarra a una primera herramienta para estudiar una ingente cantidad de datos. Fue posible porque habíamos seleccionado una idea que era factible realizar en el tiempo y con los recursos que teníamos disponibles. Esto incluía contar con alguien que pudiera programar el código necesario. En este caso contábamos con Charlie DeTar, que hizo toda la programación.
Sin embargo, es importante señalar lo que Charlie comentaba en su post “los hackathons no resuelven problemas”. La mayoría de los prototipos que salen de un hackathon requieren casi siempre retoques y desarrollo posterior para que sean usables por el gran público una vez ha terminado el hackathon. En el caso de la visualización de tuits, si echamos un ojo a las líneas de código que escribió, veremos que una vez terminado el proyecto siguió mejorando la herramienta y corrigiendo errores días después de que el evento hubiera acabado. Añadía también que los resultados de un hackathon no suelen tener la calidad y complejidad para resolver los problemas complejos del mundo real. Si son útiles, es sobre todo por el contexto dentro del que se desarrollan y por la red de usuarios y gente que los apoyan y usan.
Un proyecto como OccupyTweets, que esencialmente es una herramienta de análisis de links tweets emparentada de alguna forma con Eventweet, tiene mucho margen de mejora: búsqueda por fecha, añadir captación de tuis en directo, etc. Lo que es necesario para que eso ocurra es un grupo de usuarios que lo usen, que demanden implementaciones en el código, y unos desarrolladores que puedan dar respuesta a esas necesidades.
HurricaneHackers: ¡Esto es sólo una demo!
Otro grupo de investigación informal que surgió animado por los acontecimientos que nos rodeaban fue el de HurricaneHackers. Un día antes de la llegada del huracán Sandy a la costa este de Estados Unidos un grupo de personas, animados por Sasha Costanza Chock, se empezó a organizar a través de Internet bajo el nombre de HurricaneHackers, lo que viene a ser algo así como los hackers del huracán. Se pretendía pensar colectivamente qué podían hacer los ciudadanos para ayudar y coordinarse frente a la ‘supertormenta’ Sandy.
El grupo, de número y composición indefinida, se coordinaba a través del hashtag #hurricanehackers en Twitter y de un canal de chat en IRC. La información sobre los diferentes proyectos se iba escribiendo en un googledocs que centralizaba la información. Paralelamente se iba completando una lista con todos los enlaces relevantes para estar informado sobre Sandy: http://bit.ly/hh-linklist.[ref] Los links acortados tipo bit.ly eran usados para facilitar el compartir url difíciles de memorizar. Una url como https://docs.google.com/document/pub?id=1SGcfQz13ce4FfB-QHKF3WLwxHoCRGBouuvZn-3aoX0k se convertía en http://bit.ly/hh-index.[/ref] Al carecer de un espacio físico común, todo el proceso de lluvia de ideas, evaluación y desarrollo de proyectos, similar al proceso de un hackathon, se hacía online. El proyecto atrajo la atención de los medios de comunicación (boing boing, cnet, techpresident) y muchas personas se acercaban por el canal de char de IRC de hurricanehackers. Enseguida nos dimos cuenta de que era importante tener a alguien para la dar la bienvenida a los recién llegados y redirigirlos a donde hicieran más falta. Si no, mucha gente con ganas de ayudar podría verse abrumada con la conversación y los proyectos ya empezados.
El sentimiento de urgencia puede provocar querer empezar proyectos que ya existen. Siempre será mejor empezar donde otro lo dejó que desarrollar un herramienta desde cero, uno de los lemas del software libre aplicable a cualquier tipo de investigación. Muchas veces no hará falta escribir ni una línea de código, sino pensar cómo usar las herramientas existentes.
Como Sasha comentó en una entrevista, era importante centrarse en proyectos realistas que pudieran funcionar directa y rápidamente, especialmente en una emergencia como aquella, donde muchas personas quedaron aisladas sin agua ni luz durante días. Los proyectos que tendrían mayores posibilidades de funcionar eran aquellos que se basasen en necesidades reales de grupos trabajando en lugares específicos.
Unos días después, HurricaneHackers se unió a la iniciativa Sandy CrisisCamps, que consistía en una serie de hackathons promovidos por CrisisCommons en diferentes lugares del mundo para ayudar a las víctimas de Sandy, y empezamos a organizar un hackathon en el MIT Media Lab, que coorganicé con Denise Cheng. La tarea que teníamos por delante era mucho más compleja que con el hackathon de OccupyData: había víctimas, gente necesitada y mucha urgencia.
Aunque organizamos el evento invitando a expertos en emergencias y a desarrolladores de software (hackers) para intentar conseguir resultados tangibles, los resultados del hackathon no llegaron a producir ninguna herramienta lista para ser usada. Probablemente porque los datos y la situación eran demasiado complejos y porque entraron en juego problemas de coordinación con otros grupos en la definición misma de los problemas a solucionar. Como advierte un informe de la Universty of Missouri “no intentes organizar una web de ayuda a no ser que estés preparado para ocuparte de ella 24 horas al día”. Al menos el proceso sirvió para concienciar a los que asistieron al hackathon de la complejidad de desarrollar software para este tipo de situaciones y para revivir temporalmente el grupo de CrisisCommons Boston.
Una de las lecciones que aprendimos de este hackathon, junto con Denise Cheng, fue que es muy importante explicar a los periodistas y a los lectores que se habían acercado a la iniciativa que estábamos desarrollando prototipos y no herramientas listas para usar que sustituyeran a organizaciones como FEMA o Cruz Roja. El proyecto #SandyAid, por ejemplo, quería proporcionar ayuda a víctimas de Sandy a través de Twitter, pero estaba lejos de estar terminado y de tener un equipo detrás que pudiera proporcionar la ayuda y soporte necesarios. Otros proyectos promovidos por ciudadanos proporcionaron ayuda in situ y siguen en activo a día de hoy como por ejemplo una de las secuelas más fecundas de Occupy: occupysandy.net.
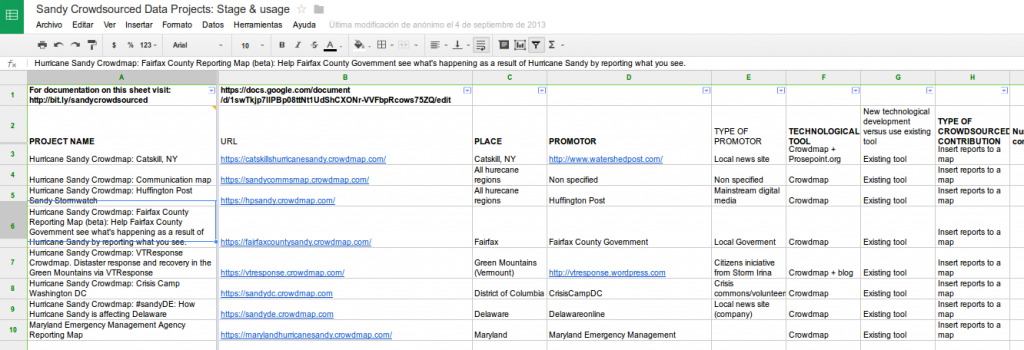
Uno de los proyectos del hackathon, realizado por Mayo Fuster, se dedicó a documentar cómo y cuánto eran usados los diferentes proyectos basados en la recolección colaborativa de datos (crowdsourced). Una de sus conclusiones fue que los proyectos más localizados tenían más probabilidades de ser usados que los más generalistas. Así pensar en un proyecto que quiera mapear toda la información sobre el huracán Sandy en la costa Este de EE. UU. (megalomanía no infrecuente en muchos hackathons) tiene menos probabilidades de funcionar que un pequeño proyecto sobre una ciudad afectada, donde los propios ciudadanos paticiparán más ávidamente.
Otros proyectos tuvieron mucho más largo recorrido hasta poder ser usados. Remembers site sí que llegó a ser un prototipo listo para su uso, gracias a la perseverancia de Sasha. Remembers es una web de homenaje a las víctimas fallecidas en el huracán y que es fácilmente editable a través de un googledocs. El software permite hacer otras webs de homenaje con un simple click y rellenando una nueva hoja de cálculo en googledocs.
–
Incluir en investigaciones de largo recorrido breves periodos de intensidad (sprint), mediante un hackathon por ejemplo, puede ayudar a introducir nuevos agentes e ideas que mejoren y hagan la investigación más rica. Estos sprint son lugares idóneos para dar lugar a ideas innovadoras y encontrar soluciones inesperadas. Como hemos visto, pasado este periodo de intensidad inicial hará falta tiempo para darles forma y llegar a un prototipo usable. Documentar, hacer rápidos tests y difundir son buenas prácticas para probar si las herramientas desarrolladas son útiles. Esto ofrece la posibilidad a que otros investigadores se sumen al proyecto y colaboren.
La respuesta a este texto llega el jueves 13 de febrero a las 9.00h en el blog de voragine.net.
Entregas anteriores de la serie:
- Investigar (es ir) haciendo y compartiendo: Demo or die, en numeroteca.org.
- Investigar sin darse cuenta: #meetcommons, acción y documentación colectiva, en voragine.net.
- Investigar (es ir) haciendo y compartiendo: Public Lab y PageOneX, en numeroteca.org.
- Investigar sin darse cuenta: archivos personales, en voragine.net
- Liveblogging, cómo documentar en directo en numeroteca.org
- Espacios autónomos de experimentación e investigación en voragine.net