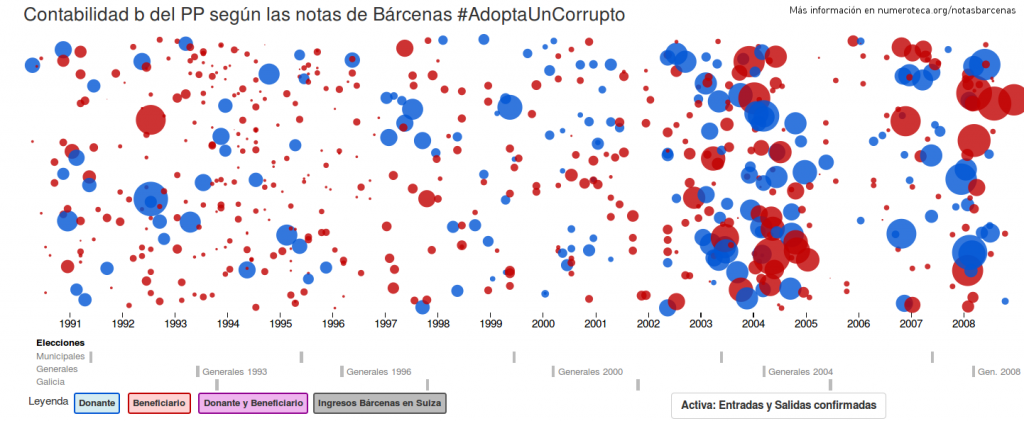
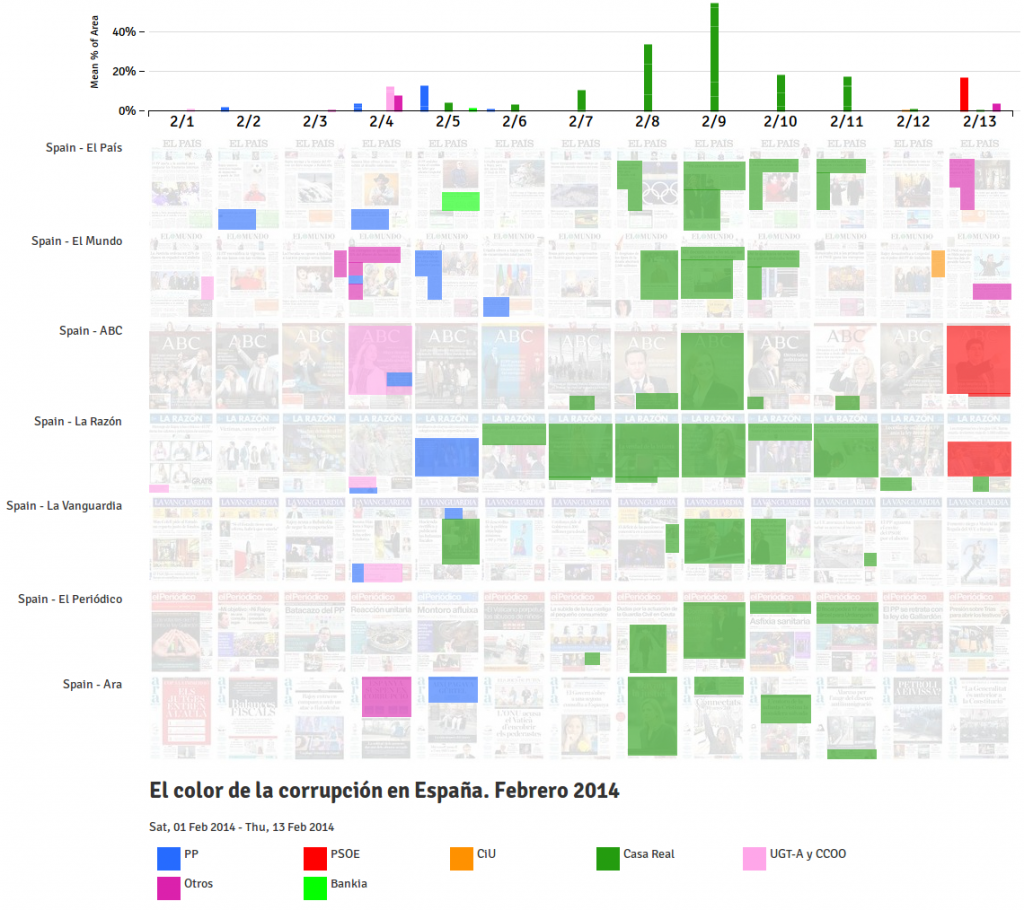
Este post es el último de la serie “Investigación colaborativa, divertida, barata, transmedia. Otras formas de entender la investigación” publicada a modo de cruce de posts entre numeroteca.org y voragine.net. Este trabajo se enmarca dentro de un estudio sobre Investigación en red coordinado por Mayo Fuster Morell parte de un proyecto más amplio sobre Juventud, Internet y Política bajo la dirección de Joan Subirats en el marco del grupo IGOPnet.cc, con la colaboración de Montera34, para la Fundación Museo Reina Sofía sobre adolescencia y juventud.
Este informe incluye varias investigaciones de temáticas muy diferentes entre sí que se desarrollan en entornos igualmente diversos, entre otros: Nathan Matias, investigador en el MIT, escribe un programa que le ayuda a codificar y visualizar quién escribe las noticias según su género; Public Lab desarrolla opensource hardware y software para monitorizar el medio ambiente al servicio de grupos de base y se financia habitualmente por crowdfunding; #meetcommons es un espacio y tiempo de encuentro pensado para experimentar metodologías de organización e investigación de un grupo abierto formado en torno a las charlas online de ThinkCommons; Eventweet es una herramienta que convierte en archivo navegable los tuits que de otra manera quedarían perdidos; los hackathons de OccupyData y Hurricanehackers son eventos pensados para condensar la creatividad y unir a un grupo heterogéneo de personas durante un breve periodo de tiempo; Obsoletos es un colectivo que difunde todo lo que investiga en su blog, donde recoge tanto proyectos propios como ajenos; voragine.net es un blog personal que recopila en forma manual todas las soluciones de programación de código que Alfonso Sánchez Uzábal va aprendiendo y desarrollando.
Todos estos casos comparten una preocupación por desarrollar las herramientas que les permiten realizar su investigación. Investigar, dialogar y difundir son parte de una misma acción para compartir lo investigado y atraer la atención del público u otros investigadores. Se publican las instrucciones o el código usado para investigar para que puedan ser replicadas. El uso de licencias libres es denominador común.
Todos ellos muestran también una preocupación por los canales y métodos en los que se difunde lo investigado. Escribir un artículo en una revista especializada no es el objetivo principal o prioritario de ninguno de estos casos. Por ejemplo, Nathan Matias monta una mini web para publicar sus visualizaciones de datos y asociado con un periódico, The Guardian, publica ahí sus resultados. #meetcommons mientras, usa Eventweet para archivar y difundir un diálogo online que se mantuvo en Twitter y permitir una multi-narrativa del evento.
En la mayoría de los casos se busca generar entornos de trabajo que permitan la innovación y el fluir de información: los hackathons de OccupyData o la retransmisión en directo de las charlas (liveblogging) del Center for Civic Media.
No existe una receta única para investigar, pero sí la certeza de que, como en la cultura hacker, a investigar se aprende investigando y explorando los límites de las herramientas de las que disponemos. Llegado al límite: hay que inventar las herramientas que quieras usar.
–
Entregas anteriores de la serie:
- Investigar (es ir) haciendo y compartiendo: Demo or die, en numeroteca.org.
- Investigar sin darse cuenta: #meetcommons, acción y documentación colectiva, en voragine.net.
- Investigar (es ir) haciendo y compartiendo: Public Lab y PageOneX, en numeroteca.org.
- Investigar sin darse cuenta: archivos personales, en voragine.net
- Liveblogging, cómo documentar en directo en numeroteca.org
- Espacios autónomos de experimentación e investigación en voragine.net
- Investigación Sprint vs. Investigación de largo recorrido en numeroteca.org
- Snippets: un gran repositorio de código distribuido en voragine.net
- Conclusiones #otrainvestigación: inventa las herramientas que quieras usar en numeroteca.org