Este post es parte de la serie “Investigación colaborativa, divertida, barata, transmedia. Otras formas de entender la investigación” publicada a modo de cruce de posts entre numeroteca.org y voragine.net. Este trabajo se enmarca dentro de un estudio sobre Investigación en red coordinado por Mayo Fuster Morell parte de un proyecto más amplio sobre Juventud, Internet y Política bajo la dirección de Joan Subirats en el marco del grupo IGOPnet.cc, con la colaboración de Montera34, para la Fundación Museo Reina Sofía sobre adolescencia y juventud.
El propósito de este informe es reflexionar sobre diferentes prácticas de investigación y de difusión de ésta que son caminos alternativos al tipo de investigación standard que se practica en la universidad en España. Para ello me he servido de proyectos que he conocido durante mi estancia como investigador visitante en el MIT Center for Civic Media (Civic Media).
Este programa de investigación, con una pata en el MIT Media Lab y otra en el departamento de Comparative Media Studies, enfoca sus actividades a
- entender cómo funcionan los medios de comunicación y flujos de información actuales, desde blogs a páginas de noticias, desde la evolución de un meme a ataques DDoS;
- desarrollar prototipos para apoyar el activismo cívico y político de grupos o comunidades de base.
Demo or die
El prototipado rápido es una de las características del tipo de investigación que se fomenta en el MIT Media Lab. Bajo el lema “demo or die”, que vendría a ser algo como “prototipa o muere”, se promueve el desarrollo rápido de prototipos para su rápido testeo. Se pretende así que un estudiante-investigador desarrolle varios proyectos hasta el punto que puedan ser usados, pero sin la necesidad de que sean productos 100% terminados. Se anima así a que sus investigadores — estudiantes de máster, doctorandos o personal contratado — exploren diferentes ideas aunque no estén relacionadas estrictamente con su línea principal de investigación ni su disciplina. La línea que apoya esta metodología es que crear un espacio antidisciplinar donde puedan ocurrir conexiones entre personas de distintos departamentos puede conducir a proyectos e ideas inesperadas en los más diversos campos.
Como ejemplo de una prolífica producción de proyectos e ideas de un estudiante en el MIT Media Lab conviene ver la presentación que Dan Schultz dio en 2012 en la conferencia que Civic Media organiza cada año. En vez de exponer un proyecto durante los 5 minutos y 20 diapositivas que se nos daban a cada ponente en un formato exprés de ponencia llamado ignite talk, expuso 18 proyectos diferentes. Iban desde ideas mínimamente desarrolladas a prototipos en funcionamiento. Uno de ellos era Truth googles, una especie de detector automático de mentiras en Internet, orientado a mostrar datos incorrectos en webs de noticias. Fue parte de la tesina de su máster. Otro era NewsJack una herramienta que permite modificar las páginas de inicio de páginas web de noticias y compartirlas en Internet. Básicamente un proyecto y su némesis: un sofware que permite hackear las portadas de los periódicos online y publicar noticias falsas con otro que detecta datos erróneos. Este ejemplo nos puede dar idea de cómo de amplio es el concepto de investigación en el MIT Media Lab.


La investigación entendida como “demo or die” promueve la creación de prototipos: tanto para crear herramientas que faciliten el proceso de investigación como para inventar nuevos dispositivos que resuelvan problemas o desempeñen nuevas funciones. La documentación del proceso es parte fundamental de la investigación y contribuye al resultado de la misma.
Desarrolla las herramientas que quieras usar
Nathan Matias, colega y estudiante de máster en Civic Media, quería responder a la pregunta ¿quién escribe las noticias en la prensa? Para ello quería mostrar cuántos artículos eran escritos por mujeres en la prensa de Reino Unido. La hipótesis que quería probar era que existe una desigualdad en quién escribe las noticias, y eso influencia qué, cómo y cuales noticias leemos.
Desde hace mucho tiempo, este tipo de estudios cuantitativos se han hecho codificando manualmente noticias a partir de periódicos de papel. Sin ir más lejos, en 2011, un grupo de investigadores codificó a mano todas las noticias de 7 periódicos durante un mes según el género de su autor. Nathan, en vez de clasificar manualmente uno por uno todos los artículos (de los tres periódicos a estudio en Reino Unido: Guardian, Daily Mail y Telegraph) escribió un programa que los descargaba de sus páginas web y los clasificaba por el género del autor. Automatizó el proceso que había supuesto para otros grupos de investigación jornadas enteras de tabajo.
Para clasificarlos por género tenía que primero construir una base de datos con los artículos de prensa y sus autores. En términos informáticos esto se llama scraping (raspar, arañar), conseguir que un programa descargue todos los artículos de la web de un periódico y vaya llenando una base de datos con los datos que interesan, en este caso: nombre de autor, título, fecha de publicación, contenido del texto, sección…
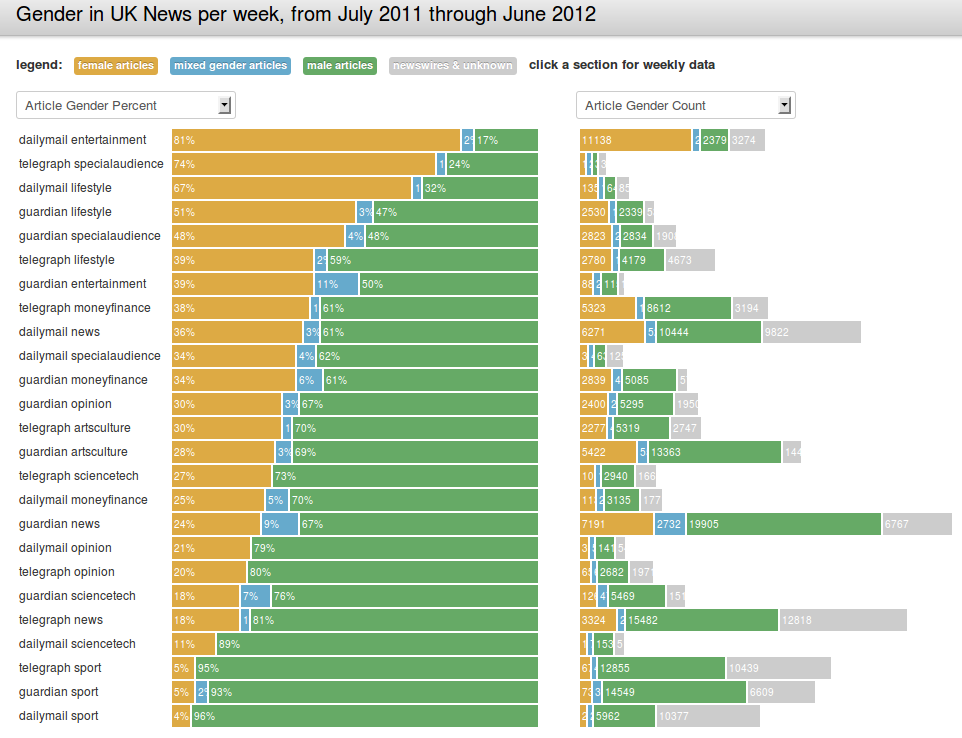
Una vez obtenida esa base de datos tenía que cruzar los nombres de los autores con otra base de datos de nombres de bebés, que previamente estaban clasificados por género. De este modo obtenía el número de artículos por género. Con estos datos se podía probar la hipótesis: el porcentaje de mujeres que escribe en la prensa es menor que el de hombres. El resultado del estudio se difundió a través de un blog de uno de los periódicos estudiados y de la propia página web del estudio, donde se podía interactuar con los datos en una visualización interactiva y comparar por periódico y por secciones quién ha escrito las noticias.
El proyecto pretende conseguir que el usuario busque entre los datos y extraiga sus propias conclusiones, en vez de ofrecer una serie de ideas a priori. El estudio se complementó analizando cuánto se compartían esos mismos artículos en las principales redes sociales en internet (Facebook, Twitter y Google⁺), para probar si la “dieta de noticias” que los medios ofrecen es la que el público decide consumir. O lo que es lo mismo, si los contenidos que publican los medios de comunicación coinciden con lo que los usuarios quieren compartir y difundir, que es una medida del interés que muestran los lectores a determinadas noticias.
Para hacer esta investigación Nathan tuvo que desarrollar una serie de herramientas que le permitieron automatizar la codificación de los artículos de prensa y visualizar los datos obtenidos. Hacer el prototipo e investigar es parte del mismo proceso en este caso. El resultado es un gráfico interactivo y una base de datos publicadas abiertamente que pueden ser la base para futuras investigaciones, tanto por él mismo como por otros investigadores o público en general interesado en el tema. El código para repetir este tipo de investigación está disponible en opengendertracking.org que ha desarrrollado junto con Lisa Evans, Irene Ros y Adam Hyland. Mientras, Nathan sigue buscando periódicos, especialmente en castellano, que estén interesados en participar en su proyecto.
Un paso más allá fue el proyecto que ha desarrollado Nathan con Sarah Szalavitz. Ambos compartían las mismas ideas sobre lo importante que era medir y cambiar las diversidad de género en los medios de comunicación. En vez de escribir el enésimo artículo sobre la escasa presencia de mujeres que firmar artículos en la prensa, desarrollaron followbias.com, una herramienta que muestra el porcentaje de hombres y mujeres a los que sigues en Twitter.

El cambio es sustancial: en vez de analizar cómo de sesgada es la información que el lector recibe en función de los editores de un periódico, ahora la herramienta mide cómo es el sesgo de información que el propio usuario ha decidido recibir. Puede analizar de este modo cómo de diverso es el grupo de cuentas que sigue en Twitter (followers), que es es el filtro de la información que recibe a través de esa plataforma. La herramienta ayuda a codificar y corregir el género asignado a tus followers. El hecho de colaborar en esta codificación, hace que el usuario se involucre el análisis y se dé cuenta de cómo funciona.
Así, la investigación atrae la atención sobre un determinado tema. No es solamente relevante por los datos que produce o por la información que nos suministra. Pero no solo eso, el usuario también participa en el análisis, ya sea explorando los datos a través de interfaces gráficas o ayudando a codificar esos mismos datos.
La respuesta a este texto llega el jueves 23 de enero a las 9.00h en el blog de voragine.net.
