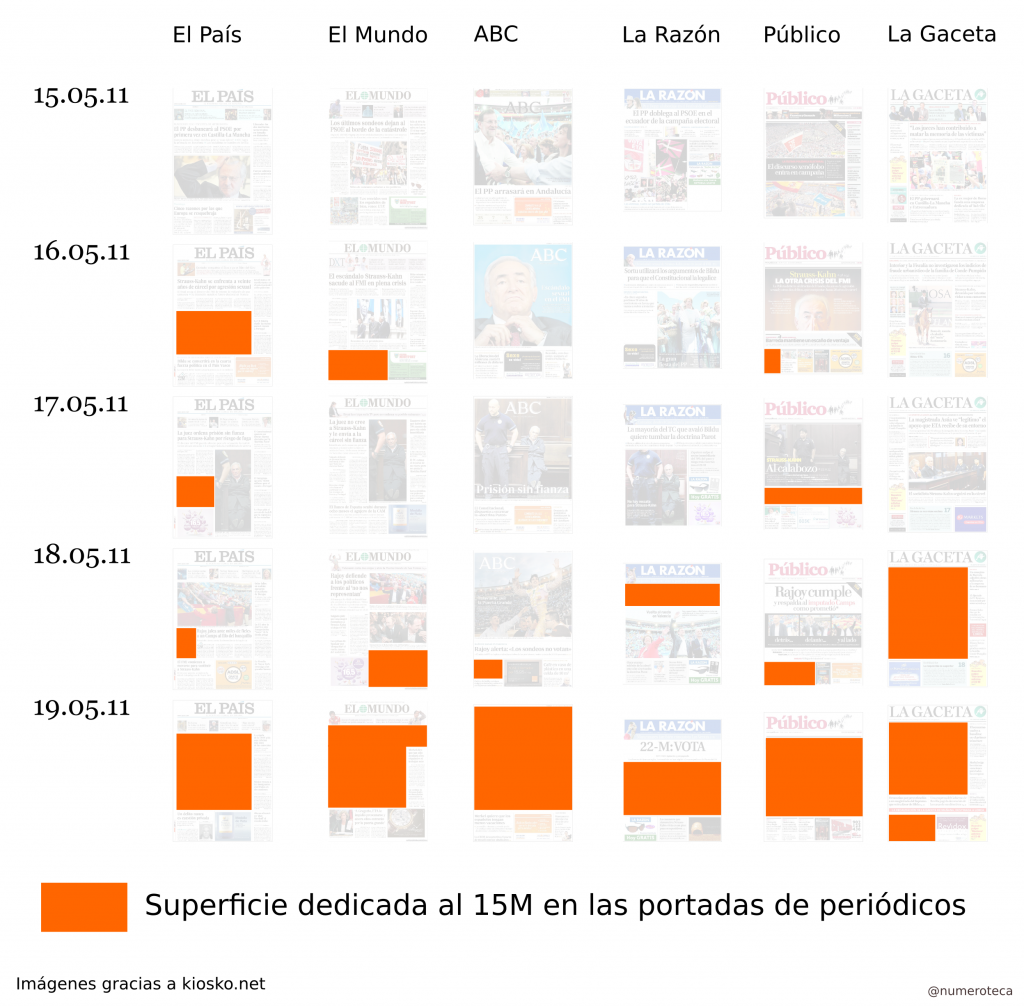
El artículo Y, ¿qué pasó con la corrupción? de Carlos Elordi me ha animado a publicar un segundo avance del informe #colorcorrupción, para mostrar o refutar con datos y gráficos algunas de las ideas que se comentan. Para ello he cruzado los datos de cobertura de corrupción en portadas de prensa impresa escrita que he acumulado en el último año con los datos del barómetro mensual del CIS. El barómetro mide la percepción de la corrupción y el fraude como uno de los tres principales problemas que existen actualmente en España.
Su artículo venía a decir que la corrupción ha dejado de estar presente en el debate político: que puede incluso que los partidos se hayan dado cuenta de que el “y tú más” no funciona y evitan hablar de corrupción del partido rival. Menciona también que la corrupción “ha caído verticalmente en la lista de preocupaciones prioritarias de los españoles que proporciona el CIS” (!) antes de haberse publicado el barómetro de abril. No comparto que haya habido una drástica caída, aunque sí que se aprecia un descenso en los últimos meses. Con lo que sí estoy de acuerdo es con que los medios hablan menos de corrupción que antes y que eso puede llegar a influir en la agenda mediática de otros medios como la televisión y la radio, y a la postre, en la agenda pública. Los datos que he recopliado de las portadas de prensa impresa demuestran que la cobertura de corrupción ha descendido.
Elordi atribuye los motivos de la disminución de la cobertura a “que la corrupción ya no da noticias clamorosas o a que se ha dejado de buscarlas”. Comparto la idea de que los casos de corrupción más importantes, los de los macrojuicios de los ERE o Gürtel, se extienden tanto en el tiempo que dejan de ser noticiables. Como la noticia suena a refrito ya no vende. Por tanto, desaparece también de las portadas, de la actualidad mediática y, como consecuencia, de la agenda pública. El fenómeno es más complejo que esta simplificación (sumad otros agentes: movilizaciones sociales, redes sociales en internet entre otros) pero puede ser un buen atajo para intentar entender qué es lo que está pasando. Sobre la segunda idea, que los medios han dejado de buscar nuevas noticias de corrupción o alimentar las existentes, es probable que sea cierta, pero difícil probarlo ¿hay menos cobertura porque hay menos casos (improbable) o porque no se quieren/pueden destapar los casos existentes?
Los datos
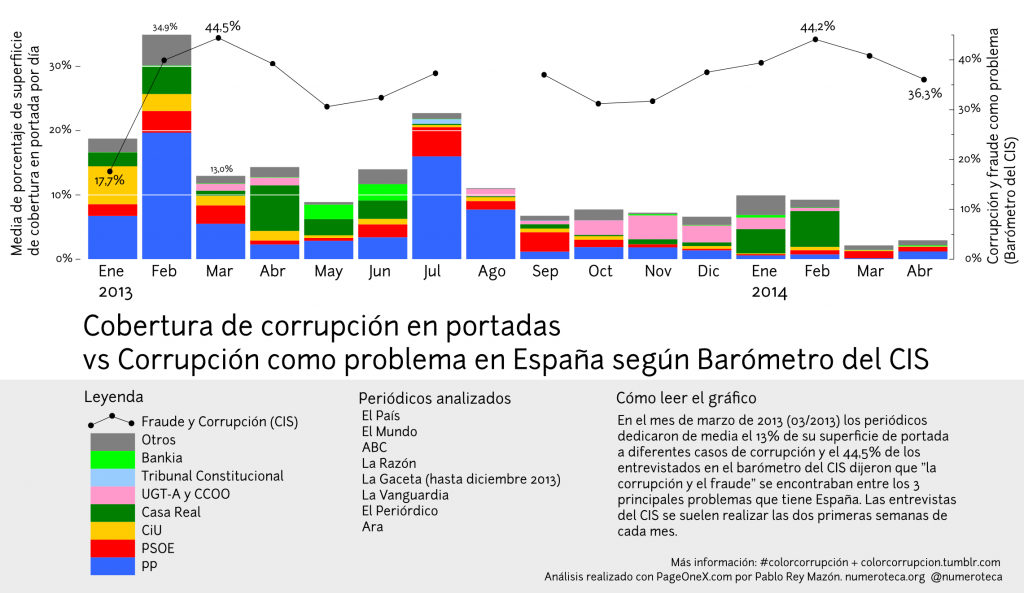
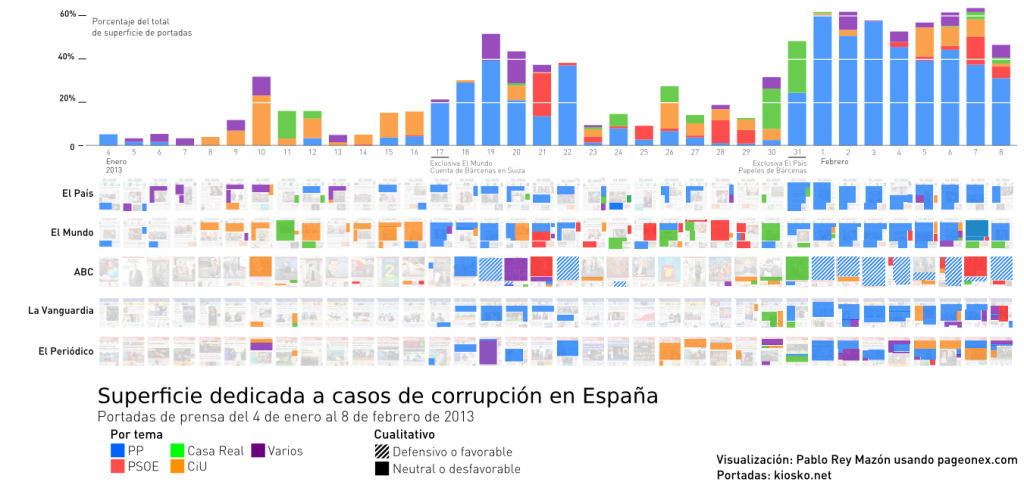
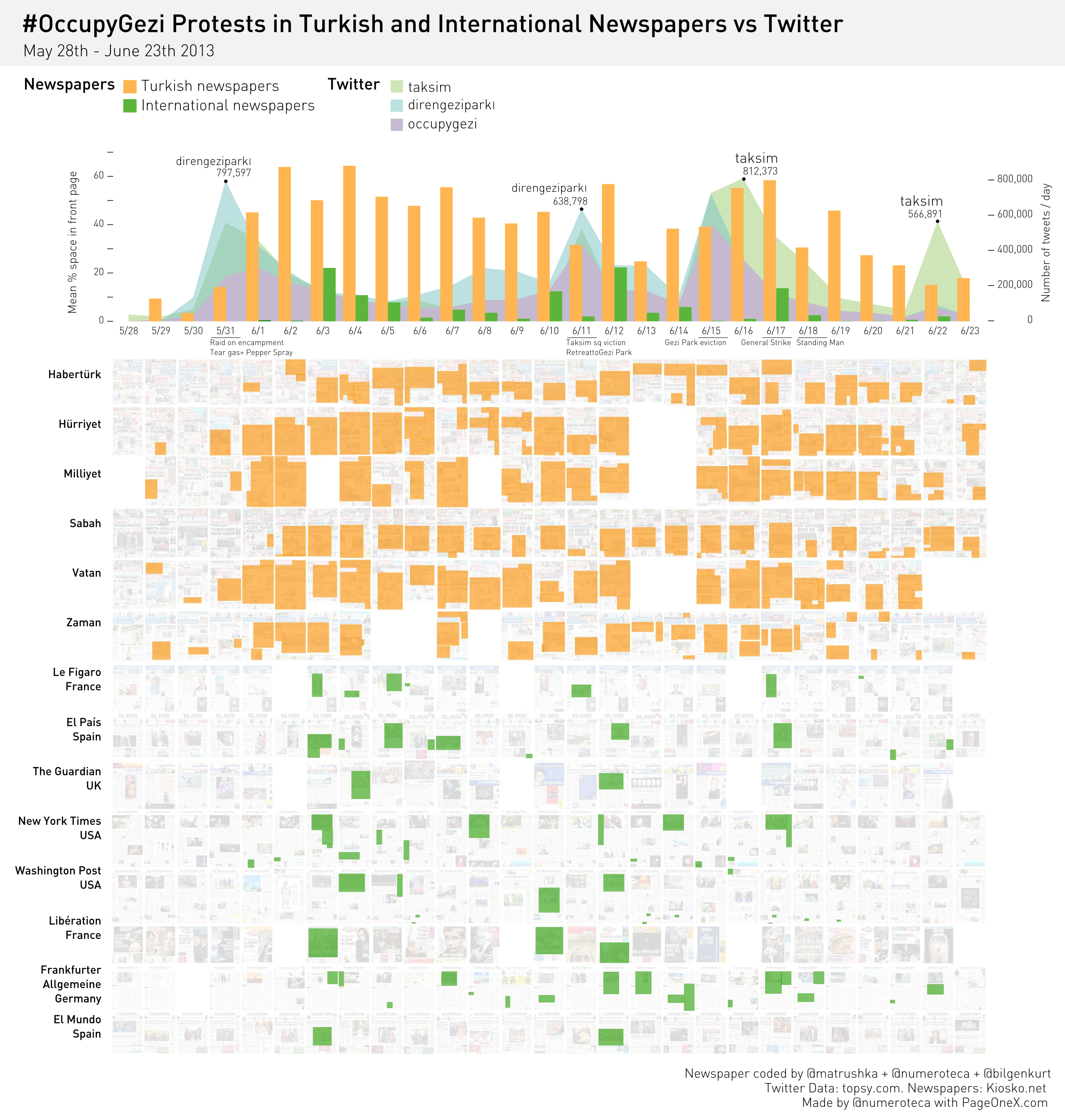
Se puede apreciar una cierta correlación (que no causalidad) entre la cobertura en las portadas y la percepción de la corrupción como problema, al menos hasta julio de 2013. Parecen también estar relacionadas tanto la brusca subida en febrero de 2013 como la paulatina subida de los meses mayo-julio de 2013. A partir del mes de julio de 2013 hay una fuerte caída en la cobertura sobre corrupción, tras la ronda de declaraciones de miembros del PP ante el juez Ruz por los papeles de Bárcenas. Los valores según el CIS, sin embargo, se mantienen bajos en torno al 7% a partir de septiembre (en el mes de gosto no hay barómetro del CIS).
Desde ese mismo mes el color azul PP deja de predominar y los tonos rojos (PSOE) y rosa (sindicatos) pasan a dominar. Más adelante hay otro drástico bajón, a partir de marzo de 2014. La imputación y posterior de declaración de la infanta Cristina ante el juez (enero-febrero 2014) propiciaron un repunte a principios de año tanto en cobertura como en preocupación (Casa Real en verde oscuro). Si no fuera por la amplia cobertura del caso Nóos que implicaba a la infanta se hubiera mantenido la media por debajo del 5% todo lo que llevamos de año 2014.
La percepción de la corrupción como un problema se mantiene, sin embargo, en niveles cercanos al máximo (44,5%, marzo de 2013), cuando el caso Bárcenas estaba en su apogeo. Existe un descenso de casi 8 puntos en los últimos 2 meses (febrero 44,2%-abril 36,2%), pero la cobertura de corrupción no ha bajado de manera proporcional. La corrupción como problema se mantiene por encima del 30% desde mayo de 2013. No hay, de momento, esa caída vertical en la preocupación según el CIS que comenta Elordi.
No sé si existe presión directa del gobierno a determinados medios de comunicación, o si el descenso de la cobertura tienen que ver con la sustitución de los directores de periódicos de El Mundo, El País, La Vanguardia, como apunta Elordi. Lo que sí parece claro es que existe un descenso generalizado en todos los medios estudiados de la cobertura de corrupción. En algunos de ellos se ha adoptado la táctica del silencio para ayudar a los partidos e instituciones amigas. Por ejemplo, los medios más afines al PP como el ABC o La Razón en su día utilizaron sus portadas para defender al PP, pero ahora es mejor no mentar la burra.
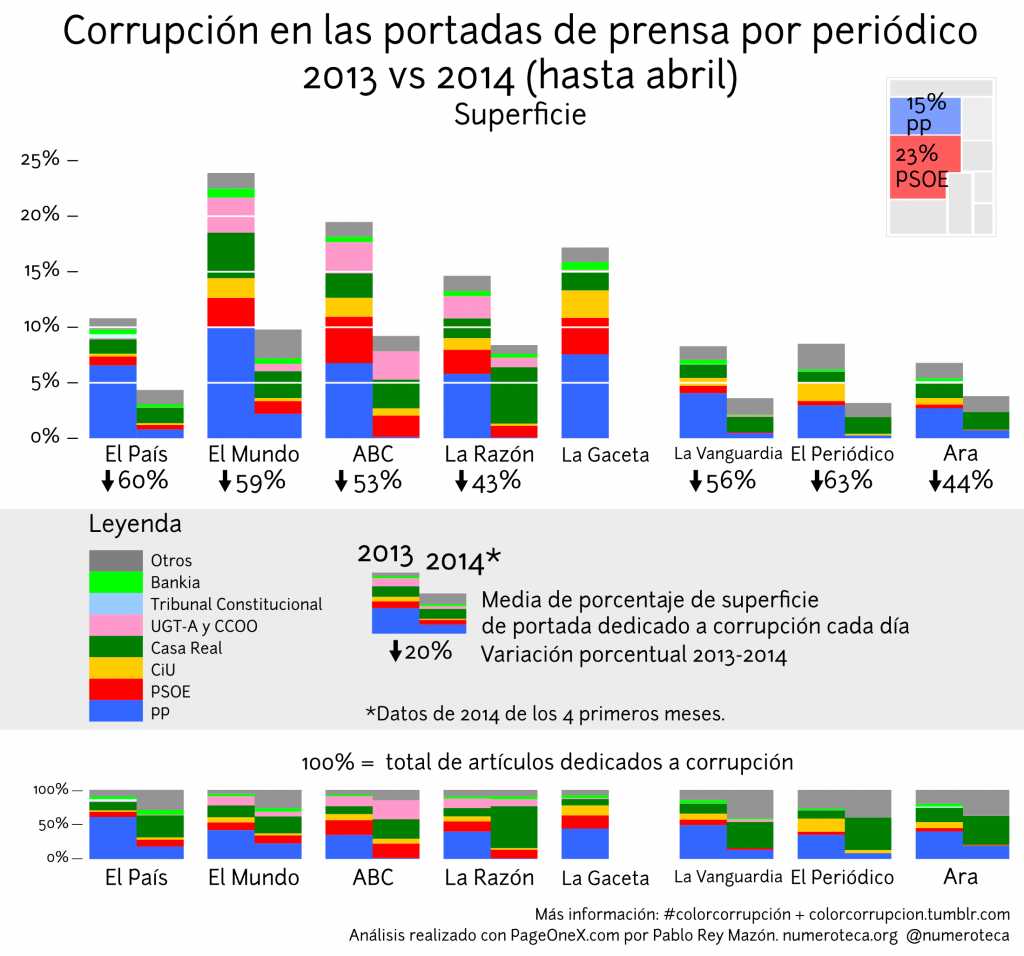
Hay que remontarse a 4 de febrero de 2014 para leer una mención negativa sobre corrupción en el PP en las portadas de La Razón y ABC. Y no llega a ser un titular sobre el PP propiamente, porque la noticia menciona las relaciones de Álvarez Cascos, ex secretario general del PP y exmiembro del partido, con la trama Gürtel. Encontramos una mención positiva en lo que llevamos de año, porque La Razón y ABC funcionan casi como un coro al unísono, seleccionando las mismas noticias para su portada: “Santamaría estalla tras el acoso del PSOE en el Congreso” (ABC) “Juego sucio del PSOE: intenta salpicar a la vicepresidenta con los sobresueldos sin pruebas” (La Razón) el 30 de abril de 2014. Para encontrar una defensa o noticía positiva de un caso de corrupción del PP hay que ir hasta el 19 de diciembre de 2013, cuando fiscal Anticorrupción recurre la imputación de la mujer de Ignacio González, presidente de la Comunidad de Madrid y del PP. Como se aprecia en el gráfico, los artículos sobre corrupción que llevan a portada La Razón y ABC son para PSOE, Casa Real, sindicatos y CiU, el color azul PP en 2014 casi ha desparecido.
El País sigue más o menos un patrón parecido, guarda silencio sobre los casos de corrupción en la Junta de Andalucía que afectan a su partido afín, el PSOE. Regla que se salta en 4 ocasiones en lo que llevamos de año: dos de enfoque negativo o perjudicial, una para señalar la imputación de Magdalena Álvarez (13 de marzo) y otra sobre cómo “Anticorrupción rastrea un nuevo fraude masivo en Andalucía” (16 de abril); y dos defensivas “La Junta acusa a Interior de orquestar una ‘causa general’ contra Andalucía” y “La Audiencia corrige otra vez a la juez Alaya” (17 y 23 de abril, respectivamente).
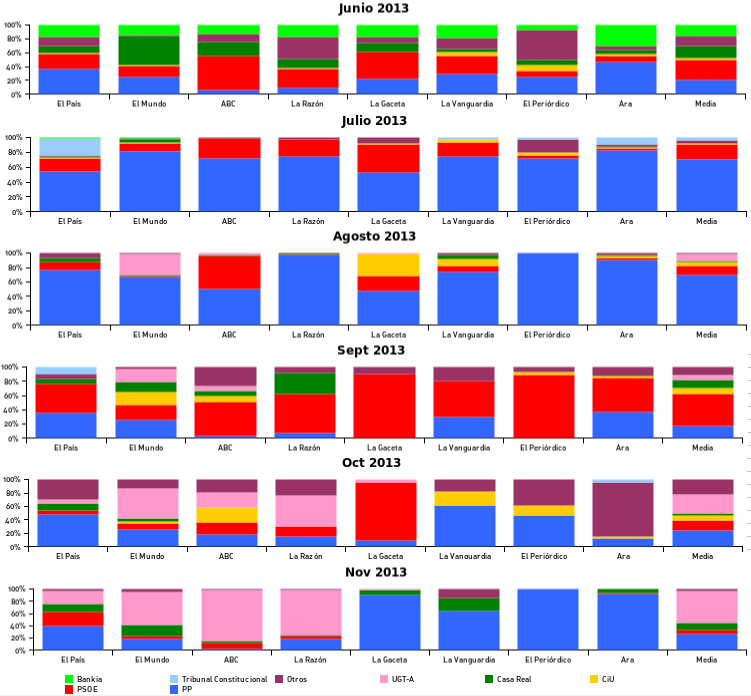
En 2014 El Mundo sigue siendo el periódico que más espacio en su portada dedica a casos de corrupción (9,8% de media por día), aunque ahora seguido más de cerca que en 2013 por ABC (9,2%) y La Razón (8,4%). El País dedica un poco menos de la mitad (4,4%) de superficie que El Mundo. Si comparamos los datos con los de 2013 observamos que todos los periódicos han bajado significativamente la cobertura en torno a un 40-60%. Los que más bajan proporcionalmente son El Periódico (63%), El País (60%) y El Mundo (59%), aunque todos están en cifras similares. El Mundo parece también seguir con la misma dieta mediática que el año anterior: platos surtidos y variados de PP, PSOE, CiU, Casa Real, Bankia y sindicatos (UGT-A).
Los tres periódicos catalanes analizados en este estudio (La Vanguardia, El Periódico y Ara) son los tres que menos espacio dedican a la corrupción tanto en 2013 como en 2014. Sin ellos la media de todos los periódicos saldrían algo más altas. La coloración gris “otros” en 2014, también presente en el resto de periódicos, tiene que ver con los casos de fraude del FC Barcelona, al que todavía no he asignado un color propio. La Gaceta desapareció como periódico en papel en los últimos días de 2013.
No he comentado apenas la cobertura del caso Nóos (Casa Real en verde oscuro) y las vicisitudes del juez Castro, ya que más o menos todos los periódicos le dedican una cantidad más o menos similar.
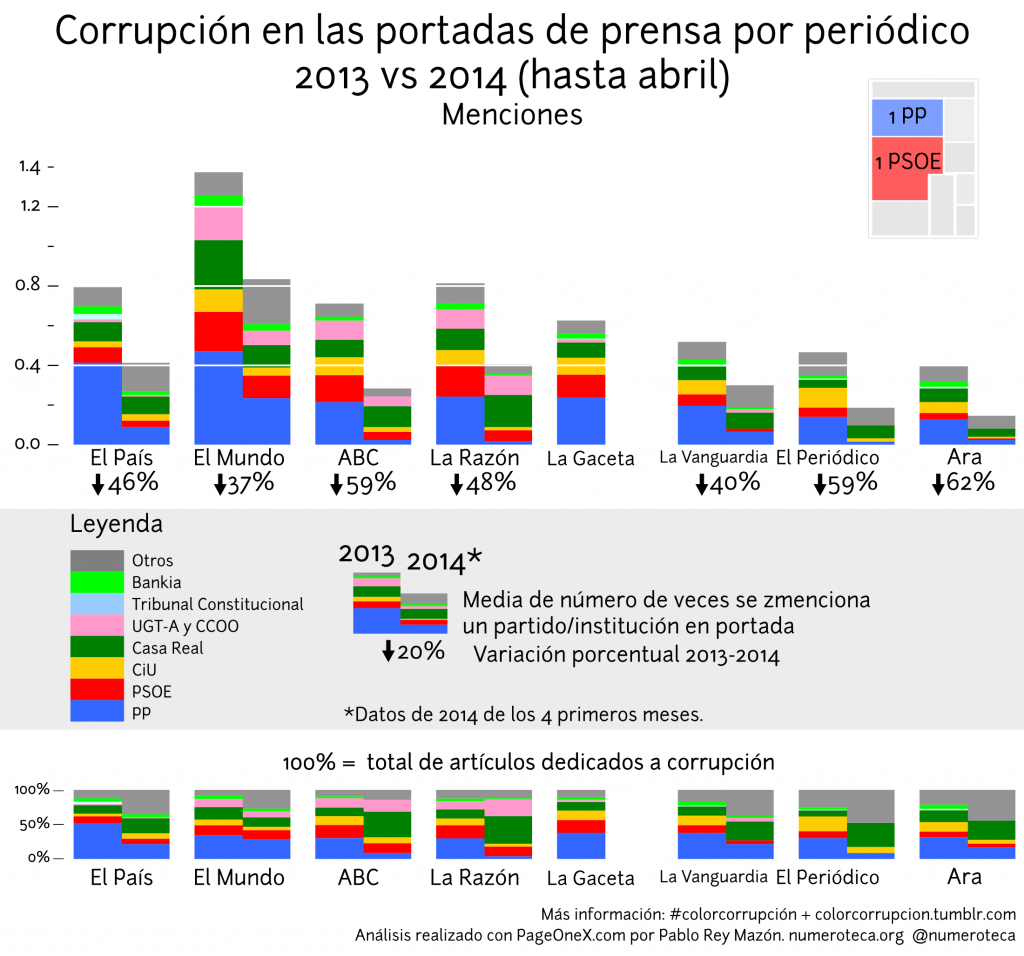
Todos los anteriores datos provienen de la medición la superficie que ocupan las noticias en la portada. Si utilizamos otra variable, el número de portadas en las que se cita a cada partido/institución por casos de corrupción, la relación entre El Mundo (103 menciones y 0,86 media diaria) y El País (51 menciones y 0,42 media idaria) se mantiene en una proporción de 2 a 1. El ABC (35 y 0,29) y La Razón (50 y 0,42) bajan en el ranking, de estar igualados con El Mundo pasan a estár igualados con El País. Debido a su diseño, que prima las fotos grandes (con menos de 5 artículos de media por portada frente a los más de 7 de El Mundo y El País), tienen menos noticias en portada: con menos artículos más grandes ocupan más superficie. Incorporar el número de menciones nos permite matizar la importancia de la superficie como atajo para medir la línea editorial de un periódico. Un análisis que estudiara el enfoque de las noticias (positiva-defensiva vs. negativa-ataque), nos haría entender mejor la situación.
Cabe destacar el número de apariciones de noticias de corrupción del PP, el partido en el gobierno, en El Mundo (29) que casi triplican los aparecidos en El País (11) en estos cuatro primeros meses del año. ¿Son estos datos indicativos de un cambio en la línea editorial de El País? Intentando encontrar las diferencias, es llamativa la ausencia de la noticia de la aparición de la cuenta en Suiza de Granados y su posterior dimisión en las portadas de febrero 2014 de El País, como se ve en el gráfico más abajo:
Sería interesante poder incluir en este estudio datos de cobertura de la radio y televisión. Estoy planeando usar los primeros minutos del telediario como atajo para medir el tiempo que dedica la televisión a cubrir la corrupción. Otro dato interesante a añadir sería el número de tuits sobre corrupción en Twitter ¿alguien tiene algo de eso por ahí?
El mes de mayo, con las elecciones europeas el día 25, viene caliente, permanezcan conectados:
Nota sobre el berómetro del CIS: Hay que tener en cuenta que las encuestas del barómetro del CIS se realizan habitalmente durante las dos primeras semanas de cada mes. En el mes de abril de este año, por ejemplo, se realizaron las 2.500 entrevistas del 1 al 7. En febrero de 2013 las entrevistas se realizaron del 4 al 12, justo durante los momentos con mayor atención mediática sobre los papeles de la contabilidad B del PP (los papeles de Bárcenas). Se puede decir que la radical subida del febrero de 2013 es consecuencia, por tanto, de la publicación de esa información en la prensa (El País) y su posterior.
Como siempre, puedes explorar todos los meses del Color de la corrpción desde enero de 2013 en los hilos abiertos en PageOneX y descargar todos los datos en formatos descargables.
Superficie media diaria en portada dedicada a casos de corrupción (Enero – Abril 2014)
Porcentaje de superficie [datos 2013]
El País 5,2% [10,8]
El Mundo 11,8% [23,9]
ABC 9,2% [19,5]
La Razón 8,4% [14,6]
La Vanguardia 3,6% [8,3]
El Periórdico 3,2% [8,5]
Ara 3,8% [6,8]
Menciones por casos de corrupción (Enero – Abril 2014)
Portadas en las que se cita a cada partido [media por día 2013 > media por día 2014]
El País 51 [0,79 > 0,42]
El Mundo 103 [1,36 > 0,86]
ABC 35 [0,71 > 0,29]
La Razón 50 [081 > 0.42]
La Vanguardia 37 [0,52 > 0,31]
El Periórdico 23 [0,46 > 0,19]
Ara 18 [0,40 > 0,15]
Hilos ColorCorupción en PageOneX
2013: Enero Febrero Marzo Abril Mayo Junio Julio Agosto Septiembre Octubre Noviembre Diciembre
2014: Enero Febrero Marzo Abril Mayo