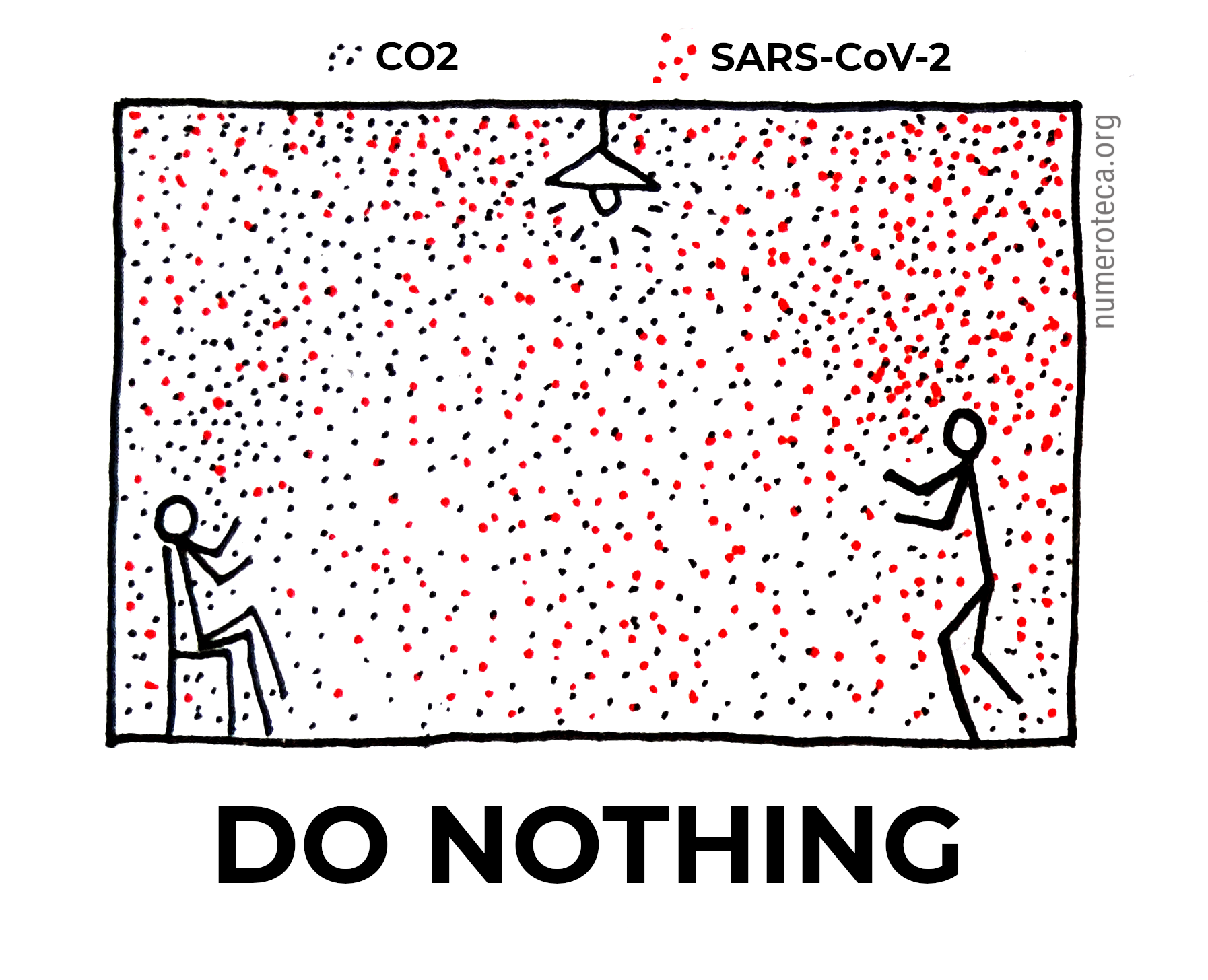
If you want to reduce viral transmission through indoor aerosols, of SARS-Cov-2 and other viruses, three methods can be applied to the air to reduce the chance of infection:
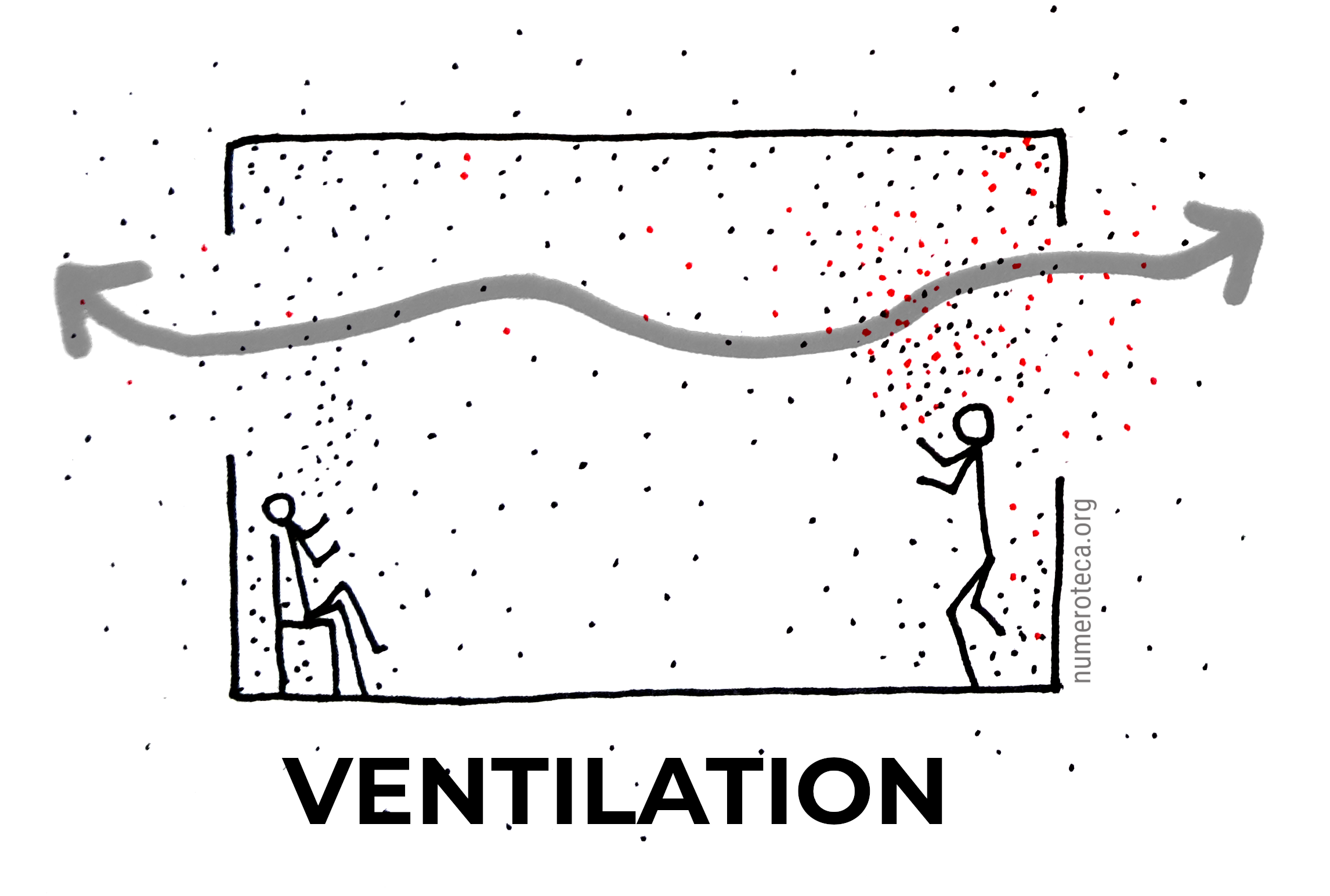
You can ventilate. With ventilation you expel the air with the aerosols outdoors, and introduce outdoor virus-free air. This can be achieved by opening doors and windows or adjusting the HVAC system to introduce more outdoor air. Note that moving air around with a recirculating forced air system, window air conditioner or minisplit air conditioner unit, or with a fan, is not ventilation in this sense, only air mixing.
You can filter. With filtration you keep the air indoors, but remove the floating aerosols. In environments where air is recirculated, or there is inadequate flow of outside air, stationary HVAC systems or portable air filters (e.g. HEPA filters or Corsi-Rosenthal boxes) can remove the virus and other contaminants from the air.
You can disinfect. With disinfection you keep the air and floating aerosols indoors, but “kill” (inactivate) the virus.
A summary of the four situations:
Update (2023-07-24): I’ve made a version in blue-red for people with color blindness:
These are all drawings, in real life you’ll not see things floating in the air:
En vista de la nueva ola y de que todavía las cosas no están muy claras ahí fuera, he decidido publicar en papel las viñetas de En el Aire que he ido publicando este año.
Pensé en imprimir y distribuir personalmente en mi entorno más cercano, pero iba a ser imposible gestionarlo en otros lugares, así que os dejo con el PDF por si queréis imprimirlo y regalarlo por ahí. Si lo imprimís, me encantará que mandéis una foto. Lo regalo o lo vendo por el costo de impresión, para producir más.
TLDR: cómo procesar uan pregunta de todos los barómetros del CIS que no está en los archivos fusionados. Necesito para mi tesis procesar todos los microdatos. Preguntas y próximos pasos al final.
Una de las fuentes de datos que uso para mi tesis son los barómteros del CIS. Cada mes desde hace muchos años el CIS hace una encuesta, barómetro, en donde se pregunta por los tres principales problemas que tiene España.
18/ …y analizando cómo la sociedad percibe la corrupción, por ejemplo, usando los barómetros del CIS y su percepción de ésta como problema. imagen de barómetro y corrupción. Analicé esto para el libro @espanaconC, un manual para entender de dónd viene la corrupción en España pic.twitter.com/13ZLGebAmk
Como los microdatos de cada barómetro están disponibles, esto es, cada una de las respuestas a los cuestionarios está publicada, es posible analizar y cruzar variables por edad, comunidad autónoma o profesión. El primer problema es conseguir y procesar los datos.
Disponibilidad de los datos: web y FID
Lo primero es dirigirse a la página del CIS a descargarlos (pestaña Estudios http://www.analisis.cis.es/cisdb.jsp), pero se encuentra uno el primer problema: hace falta introudcir tus datos personales (nombre, apellidos, universidad, email, objeto) para descargarlo, lo cual descarta un scrapero rápido automatizado de los datos. Existen datos fusionados de varios barómetros juntos para algunos años, pero no están disponibles para todos los años.
Así que la siguiente opción es usar los Fichero Integrado de Datos (FID) (http://analisis.cis.es/fid/fid.jsp) “un único fichero, de los microdatos de un conjunto de variables, para los estudios del CIS que se seleccionen”:
“El interfaz permite al usuario elegir de forma rápida y cómoda a partir de una colección, los estudios que desee y, de estos, las variables deseadas de entre las contenidas en el diccionario del FID. Posteriormente, la solicitud se envía al CIS y, una vez que el CIS procede a su autorización, el fichero con los microdatos seleccionados se puede descargar en formato ASCII o SAV, de modo sencillo y fácil de tabular por diversos programas estadísticos. Es necesario el registro del usuario o identificación del mismo (si el usuario ya está registrado), para completar una petición de datos”.
Web del CIS. Explicación sobre los Fichero Integrado de Datos (FID).
El problema es que la pregunta que necesito “¿Cuál es el principal problema que existe en España? ¿ y el segundo? ¿y el tercero?”, aunque su enunciado concreto ha ido variando a lo largo de los años, no está disponible en los FID, ya que solamente se ofrece un subconjunto de las variables integradas.
Según me han indicado soy el primero en hacerlo. Me parece raro que nadie lo haya hecho antes, ciertamente. Seguramente hayan usado otros métodos.
Tras una serie de pruebas con unos archivos de prueba para comprobar que los abría bien han procedido a preparar para que descargue todos los microdatos de los barómetros en zips por año. En pocos días me he hecho con la colección completa de microdatos de barómetros.
.zips esperando paciente a ser abiertos.
Un poco de código para descomprimirlos fácilmente:
unzip ‘*.zip’ unzipear todos los archivos mv */* . mover los que están en directorios al raiz mv MD*/* . rm -r 19* 20* fu* eliminar directorios vacíos Ahora que tengo todos, volver a unzipear: unzip ‘*.zip’
Ahora creo un archivo con todos los *.sav: ls | grep sav > files.csv
Ahora tengo el listado de todos los barómetros disponibles (los de 2020 y 2021 me da un problema para abrirlos que tengo que resolver “error reading system-file header”). Puedo procesar todos los microdatos de los barómetros desde junio de 1989, los anteriores solamente están disponibles uno de 1987 (nº 1695), dos de 1985 (nº 1442 y 1435) y otro de 1982 (nº 1320), que me enviarán cuando sea posible. Para el resto desde junio de 1979 no hay microdatos y habría que pagar por ellos si los quisiera.
Encontrar la pregunta y su número
Documentos que se incluyen en un .zip de un barómetro.
Para poder analizar las respuestas por CCAA, que es mi objetivo, tengo que encontrar el código de la pregunta, que, oh sorpresa, va cambiando a lo largo de los años. Para ello he montado una hoja de cálculo para anotar qué código lleva la pregunta (https://docs.google.com/spreadsheets/d/1xxlt8FnWanVzYkIQdU2yaWlE8-HUvnzVXSiE2QvNJRU/edit#gid=0). Así, la primera vez que aparece es en los archivos disponibles es de mayo de 1992, y tiene los códigos P501, P502 y P503, una por cada uno de los problemas percibidos. Ese código ha ido variando a lo largo de los años a la pregunta: P1401, P701, P1601, P1201… los primero números indican el número de la pregunta. Para averiguar el código hay dos maneras. Cada barómetro está compuesto por un conjunto de archivos. Así, el barómetro nº 3134 tiene los siguientes archivos:
3134.sav microdatos
DA3134 archivo dat
ES3134
FT3134.pdf ficha técnica
cues31314.pdf cuestionario original
codigo3134.pdf códigos utilizados
tarjetas3134.pdf tarjetas que usan los encuestadores
Al principio miraba si la pregunta estaba en el cuestionario, pero luego vi que era más rápido mirar directamente si en el archivo con los códigos venía la pregunta y su número: “P.7 Principal problema que existe actualmente en España. El segundo. El tercero” que con suerte correspondería con la variable P701, P702 y P703.
El problema es que en algunos casos contados ponen la “p” de la variable con minúscula y el código es p701. Algo que solamente se puede averiguar abriendo el archivo .sav. Para ver lo que contiene el archivo.sav con la librería “foreign” en R: df <- read.spss(data, use.value.label=TRUE, to.data.frame=TRUE), siendo data el “path” al archivo .sav correspondiente.
Desde Rstudio se puede previsualizar el archivo .sav cargado y mirar cuál es el código correcto:
Así se ve en Rstudio.
Lo que pasa es que muchos barómetros no tienen disponible esa pregunta, pero ¿cómo saberlo para ahorrarnos tiempo? Existe una página, ya ni recuerdo cómo llegué a ella, que tiene todas las respuestas recogidas y procesadas “Tres problemas principales que existen actualmente en España (Multirrespuesta %) http://www.cis.es/cis/export/sites/default/-Archivos/Indicadores/documentos_html/TresProblemas.htm, esto pernite de un vistazo saber cuáles son los barómetros que tienen respuesta:
Así se puede ir a tiro hecho a buscar el código en los barómetros que sabemos tienen respuesta. Relleno celdas de la hoja de cálculo de las columnas p1, p2 y p3 (cada una corresponde con una de las respuestas a los 3 principales problemas) copiando el valor anterior, hasta que da error el script que lo procesa (ver más adelante).
Clasificando en p1, p2 y p3 los códigos de las preguintas en cada uno de los barómtreos. En negro si lo he mirado, en gris si lo he “acertado” y no ha fallado el script.
Pero no se detienen los problemas. Los encuestadores recogían la respuesta libre (que no se ofrece en los microdatos) para después clasificarla en unos cajones-respuestas establecidos:
Lo que ocurre es que en algunos años “La corrupción y el fraude” no se ofrecían como respuesta posible, así que de haber habido alguna respuesta corrupción como respuesta en aquello años de bonanza económica habrá ido a la casilla de “otros”. Esto pasó entre septiembre de 2000 y julio de 2001, por ejemplo, lo que hará que la serie tenga algunos agujeros. Habrá que hacerlos explícitos.
Procesar 1: juntar todas las respuestas
Una vez sorteadas estas trabas es la hora de programar un script que vaya abriendo cada archivo .sav, seleccione las variables adecuadas y cree un archivo con todas las respuestas:
# Select and load multiple barometro files ------------
# where are files stored
path <- "~/data/CIS/barometro/almacen/tmp/"
# remove if it hasn't got the questions
cis_files <- cis_files %>% filter( p1 != "" )
# iterate through all the files
for ( i in 1:nrow(cis_files) ) {
# for ( i in 1:8 ) {
print("--------------------")
print(paste(i,cis_files$name[i],cis_files$date[i] ) )
# create path to file
data <- paste0(path, cis_files$name[i])
# load data in the file
df <- read.spss(data, use.value.label=TRUE, to.data.frame=TRUE)
# chec if variable ESTU exists
if ( "ESTU" %in% colnames(df) ) {
df <- df %>% mutate(
ESTU = as.character(ESTU)
)
} else {
# if ESTU is not in the variables, insert the ID of the barometer
df <- df %>% mutate(
ESTU = cis_files$id[i],
ESTU = as.character(ESTU)
)
}
# if REGION exixts, rename it as CCAA
if ( "REGION" %in% colnames(df) ) {
df <- df %>% rename(
CCAA = REGION
)
}
# add date to data by taking it gtom cis_id dataframe
df <- left_join(df,
cis_id %>% select(id,date),
by = c("ESTU"="id")
# ) %>% select( date, ESTU, CCAA, PROV, MUN, P701, P702, P703 )
)
# select the basic columns and the 3 questions
# the true name of the question is specified in the online document https://docs.google.com/spreadsheets/d/1xxlt8FnWanVzYkIQdU2yaWlE8-HUvnzVXSiE2QvNJRU/edit#gid=0
selected <- c( "date", "ESTU", "CCAA", "PROV", "MUN", cis_files$p1[i], cis_files$p2[i], cis_files$p3[i])
df <- df %>% select(selected) %>% rename(
p1 = cis_files$p1[i],
p2 = cis_files$p2[i],
p3 = cis_files$p3[i],
) %>% mutate(
p1 = as.character(p1),
p2 = as.character(p2),
p3 = as.character(p3)
)
# For the first file
if ( i == 1) {
print("opt 1")
# loads df in the final exportdataframe "barometros"
barometros <- df
print(df$date[1])
print(df$ESTU[1])
} else {
print("not i==1")
barometros <- rbind( df, barometros)
}
}
Por el momento tengo 570.795 respuestas a la pregunta analizada de 223 barómetros, a falta de solventar algunos problemas.
Ahora toca agrupar las respuestas por barómetros de nuevo y calcular el número de encuestas por barómetro que hacen mención a tal o cual tema:
# Group by date and CCAA ----------------------
evol_count <- barometros %>% group_by(CCAA,date) %>% summarise(
# counts number of elements by barometro and CCAA
count_total = n()
) %>% ungroup()
evol_p1 <- barometros %>% group_by(CCAA,date,p1) %>% summarise(
# counts number of answers for each type for question 1 by barometro and CCAA
count_p1 = as.numeric( n() )
)
evol_p2 <- barometros %>% group_by(CCAA,date,p2) %>% summarise(
# counts number of answers for each type for question 1 by barometro and CCAA
count_p2 = as.numeric( n() )
)
evol_p3 <- barometros %>% group_by(CCAA,date,p3) %>% summarise(
# counts number of answers for each type for question 1 by barometro and CCAA
count_p3 = as.numeric( n() )
)
# joins p1 and p2
evol <- full_join(
evol_p1 %>% mutate(dunique = paste0(date,CCAA,p1)) ,
evol_p2 %>% mutate(dunique = paste0(date,CCAA,p2)) %>% ungroup() %>% rename( date_p2 = date, CCAA_p2 = CCAA),
by = "dunique"
) %>% mutate (
# perc_p2 = round( count_p2 / count_total * 100, digits = 1)
)
# fills the dates and CCAA that were empty
evol <- evol %>% mutate(
date = as.character(date),
date = ifelse( is.na(date) , as.character(date_p2), date),
date = as.Date(date),
CCAA = as.character(CCAA),
CCAA = ifelse( is.na(CCAA), as.character(CCAA_p2), CCAA),
CCAA = as.factor(CCAA)
)
# joins p1-p2 with p3
evol <- full_join(
evol,
evol_p3 %>% mutate(dunique = paste0(date,CCAA,p3)) %>% ungroup() %>% rename( date_p3 = date, CCAA_p3 = CCAA),
by = "dunique"
) %>% mutate (
# perc_p2 = round( count_p2 / count_total * 100, digits = 1)
)
# fills the dates and CCAA that were empty
evol <- evol %>% mutate(
date = as.character(date),
date = ifelse( is.na(date) , as.character(date_p3), date),
date = as.Date(date),
CCAA = as.character(CCAA),
CCAA = ifelse( is.na(CCAA), as.character(CCAA_p3), CCAA),
CCAA = as.factor(CCAA)
)
# add number of answers per barometer and CCAA
evol <- left_join(
evol %>% mutate(dunique = paste0(date,CCAA)),
evol_count %>% mutate(dunique = paste0(date,CCAA)) %>% select(-date,-CCAA),
by = "dunique"
) %>% mutate (
count_p = count_p1 + replace_na(count_p2,0) + replace_na(count_p3,0),
# este sistema da error en los "no contesta" al contarlos varias veces al sumar!!!
perc = round( count_p / count_total * 100, digits = 1)
) %>% select ( date, CCAA, everything(), -dunique, -date_p2, -date_p3, -CCAA_p2, -CCAA_p3 ) %>% mutate(
p = p1,
p = ifelse( is.na(p),p2,p),
p = ifelse( is.na(p),p3,p),
date = as.Date(date)
)
Limpiar los datos 2: las respuestas
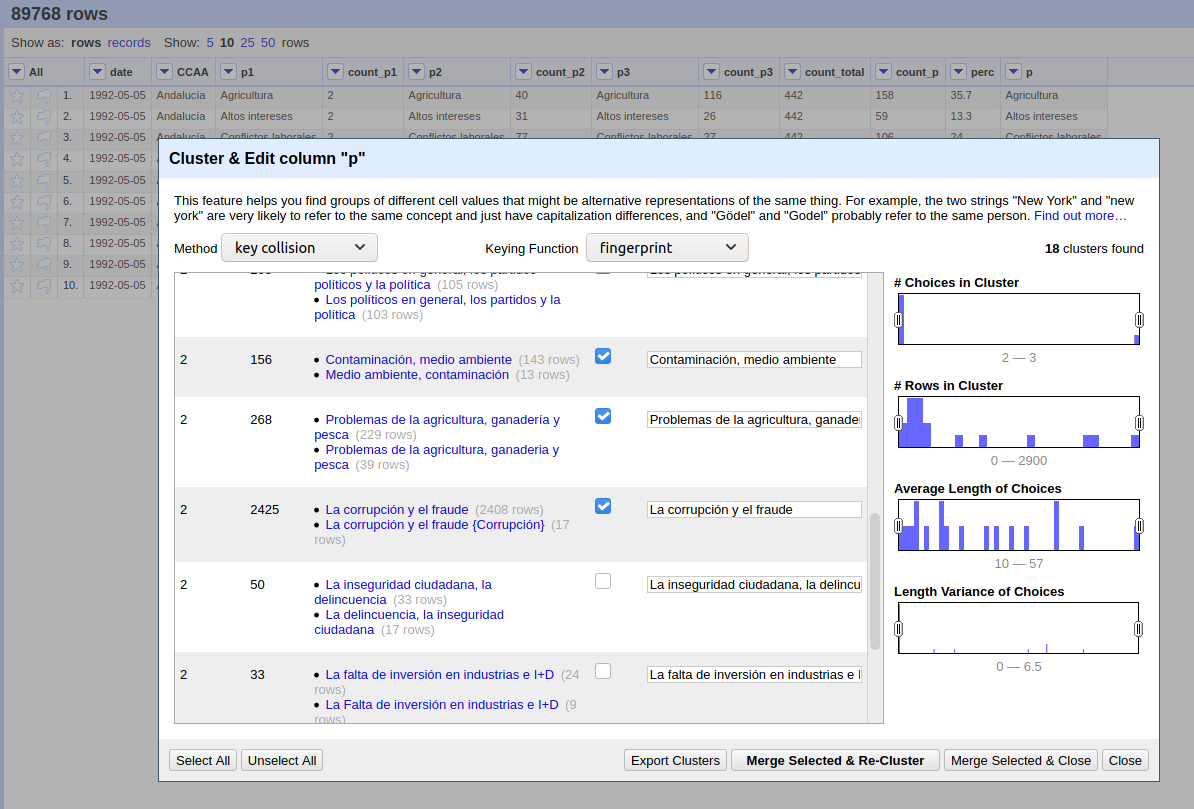
Toca limpiar las respuestas para eliminar las múltiples formas de escribir “La corrupción y el fraude” o “Corrupción y fraude ” (ojo al espacio después de “fraude” que a algunos vuelve loco). Una tarea de estandarización de las respuestas que hago con OpenRefine y que en algunos casos requiere de decisiones subjetivas, véase el ejemplo:
Detección de respuestas parecidas para su consolidación en OpenRefine.Proceso de consolidación de respuestas con OpenRefine.
Visualizar
El siguiente paso es visualizar los resultados para detectar los primero errores y corregir problemas en la captura y procesado. Antes de publicar esto ha ocurrido varias veces: detecté unos barómetros de 2016 que no se habían descomprimido, por ejemplo.
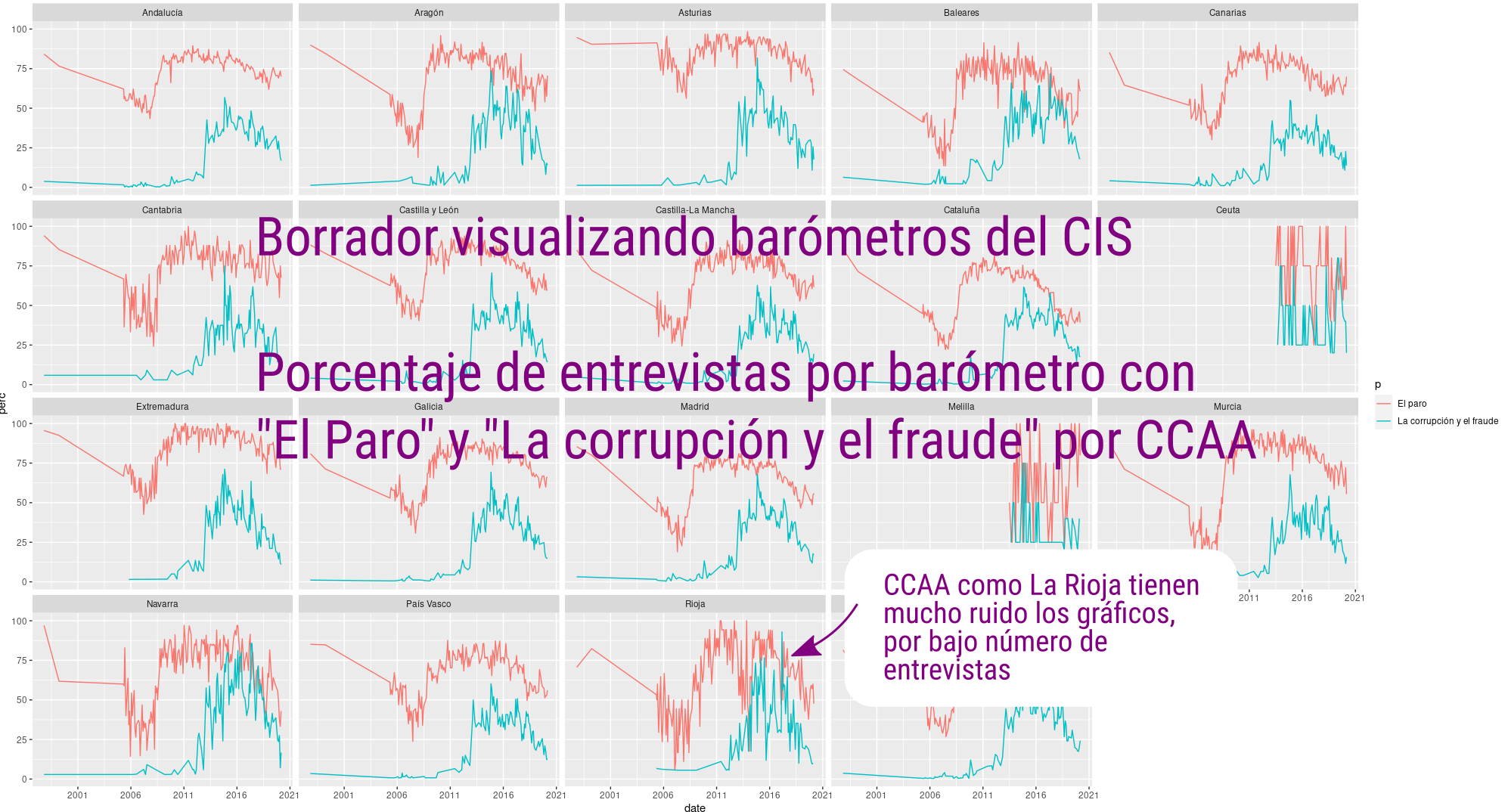
En las primeras visualizaciones trato de ver que salen valores congruentes y que no hay agujeros en los datos. En este primer gráfico de rejilla muestro el porcentaje de entrevistas de cada barómetro que tienen como respuesta “El paro” (rosa) y “La corrupción y el fraude” (verde). Ya se pueden ver cómo hay mucho más ruido en lugares como Ceuta y Melilla por el bajo número de respuestas, pero que el resto de valores sigue una tendencia parecida. En La Rioja (fila de abajo, tercera por la izquierda) también se ve ese problema, con sus 17 entrevistas por barómetro.
Un primer vistazo a las visualizaciones, publicaré más cuando tenga más claro que no hay errores en los datos
Problemas y siguientes pasos
Desde el CIS no solamente me enviaron todos los microdatos sino que me asesoraron sobre su uso. Les conté lo que pretendía hacer con los datos y me advirtieron de dos cosas relacionadas con la cantidad de entrevistas por CCAA y la ponderación:
A. Ponderación en SPSS
“Los ficheros Sav, por defecto van con la ponderación activada, siempre, en todos los que hemos pasado ya y en los que pasaremos, de esta lista”, algo que no entiendo del todo bien, porque eso no creo que deba afectar a los microdatos. Si alguien ha trabajado con los .sav en SPSS quizás me pueda aclarar cómo funciona la ponderación en ese programa, dónde se almacena esa información.
B. Si no tienes más de 400 entrevistas…
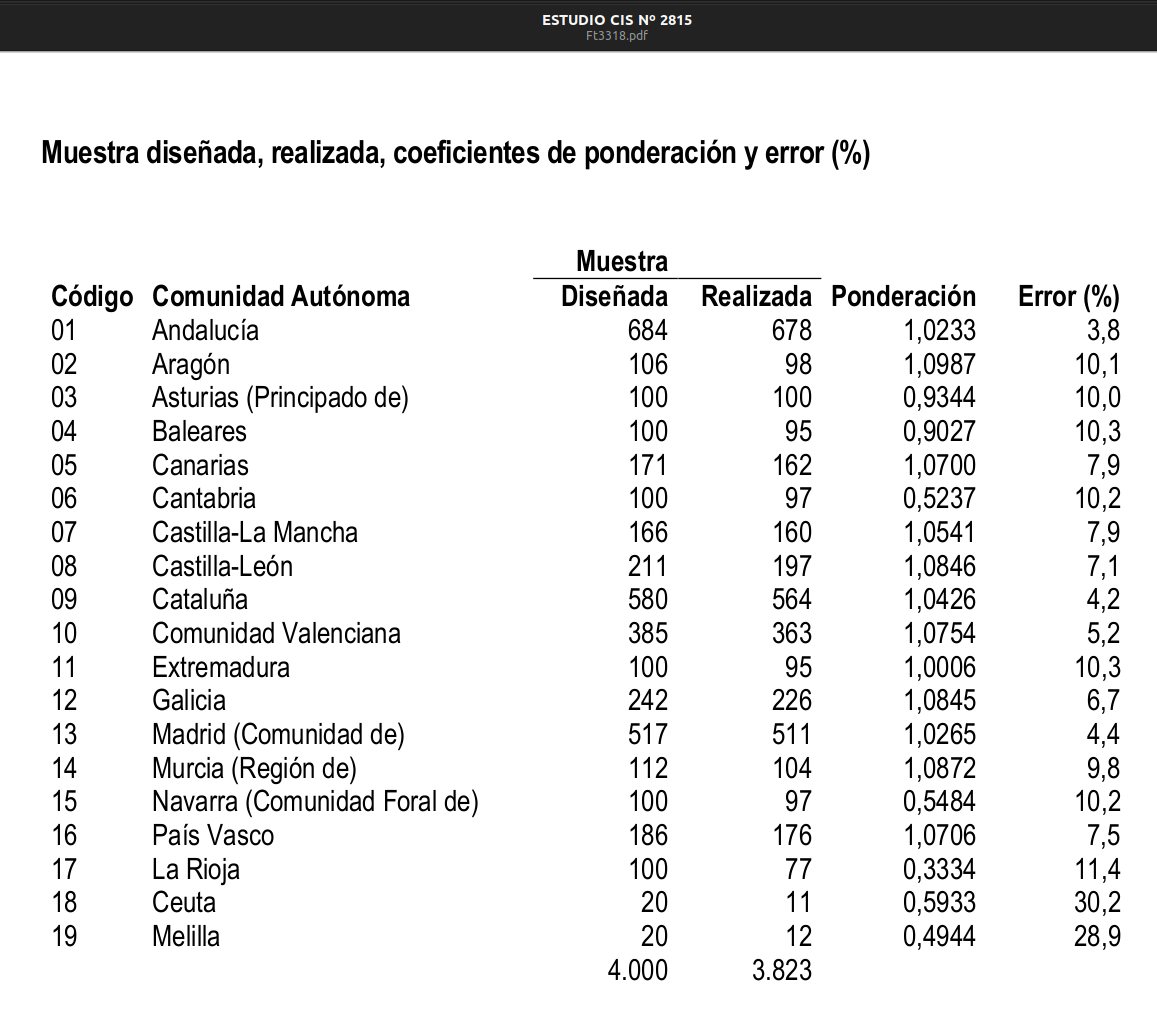
“Nosotros no consideramos representativos los datos de Comunidades con un tamaño menor a 400 entrevistas. En los barómetros, salvo los del último año para algunas Comunidades (mire ficha técnica), el tamaño muestral es de entorno a las 2.500 entrevistas, eso significa que habitualmente salvo Madrid y Cataluña, la mayor parte se quedan muy por debajo, incluso de menos de 100. Los márgenes de error cuando se quiere hablar sobre esos datos son muy altos, y más aún si además va a hacer cruces”. Me redirigían a una sección de su web:
ADVERTENCIA: El error muestral aumenta conforme disminuye el número de entrevistas realizadas. Téngase presente sobre todo en los cruces de variables y las preguntas filtradas. A modo orientativo, bajo la hipótesis de muestreo aleatorio simple, P=Q=1/2 y un 95% de intervalo de confianza, véase la siguiente tabla: Fuente: http://www.analisis.cis.es/aAvisoVars.jsp?tipo=2&w=800&h=600
Una cuestión no menor que puede hacer que no use finalmente estos datos para las comunidades, o tenga que emplear grados de incertidumbre demasiado altos.
En los últimos estudios sí aparece la ponderación usada para el valor global:
Día en que se realiza la entrevista ¿se podría saber?
Tenía interés en cruzar el día de la encuesta para ver si se podía estudiar con determinados escándalos que tienen un día muy marcado su anuncio en los medios de comunicación, podŕia verse su impacto en las encuestas, pero ese dato no está disponible. Lo que se conoce es el periodo en que se realizan las encuestas, que suele ser la primera quincena del mes. ¿se podrá conseguir la fecha exacta de cada entrevista?


















{kind=link}